Вайбкодинг — не Вайб и не Кодинг
Привет Хабр! Понимаю, что постов на эту тему появляется всё больше, вижу как их количество растёт. Все они подходят к проблеме с разных сторон — я хочу показать свою.
Я фриланс-разработчик, 2 года опыта. В основном делаю телеграм-ботов и TG mini apps, иногда бывают заказы на лендинги, смарт-контракты и пентесты. Работаю на одной площадке — Кворк. Есть аккаунт на Fiverr, но там никто ни разу не писал, кроме мошенников...
Последние полгода я делаю проекты только при помощи LLM. Я почти не читаю код и не пишу его совсем — только логи иногда добавляю. Готов к летящим помидорам. Хочу рассказать о том, что я только вырос: в доходе, эффективности, доверии заказчиков. За эти полгода мой доход вырос почти в три раза, я нашёл двух стажёров, и дело идёт в гору — появились крупные заказы.
Но меня немного обескураживает, когда люди называют процесс разработки при помощи LLM "вайбкодингом". Я не могу назвать это ни вайбом, ни кодингом. Сейчас объясню почему.
Эволюция: от чатов к системе
Сначала я работал чисто руками - как все здравые ребята прошел курсы (бесплатные!) и пошел искать заказы (Aiogram). Спустя пол года начал использовать чаты с нейронками для решения локальных задач, для генерации отдельных файлов. С ростом проектов это становилось очень туго — надо было постоянно обновлять контекст, напоминать содержание оригинальных файлов и структуру проектов. Тогда так нельзя было нормально делать.
Потом я перешёл в Cursor — это решило прошлые проблемы, но возникли новые. Общая структура проекта размывалась, старые ошибки возникали снова. Это приводило к тому, что проекты плыли в болото. Тогда я понял: все достижения и планы надо фиксировать.
Так родилась система с документацией.
Документация как фундамент
## ✅ Реализованные компоненты
### Backend:
- ✅ Модель `WBCabinet` с полем `spreadsheet_id`
- ✅ `ExportService` с методами обновления таблиц
- ✅ API endpoints для сохранения и обновления
- ✅ Celery задачи для автоматического экспорта
- ✅ Интеграция с Google Sheets API
### Bot:
- ✅ Кнопка "? Экспорт в Google Sheets" в главном меню
- ✅ Обработка привязки таблицы
- ✅ Состояния FSM для workflow
- ✅ Ручное обновление таблиц
- ✅ Инструкции для пользователя
### Инфраструктура:
- ✅ Celery Beat для запуска по расписанию
- ✅ Google Service Account настроен
- ✅ Переменные окружения настроены
- ✅ Логирование всех операций
---
## ? Безопасность
### Service Account:
- Изолированный аккаунт для доступа к Google Sheets API
- Пользователь явно дает доступ боту
- Ограничение прав на уровне Google Drive
### Защита данных:
- HTTPS для всех запросов
- Изоляция данных между кабинетами
- Валидация прав доступа на каждом запросе
- Логирование всех операций
Я выработал свою схему работы в разработке c LLM. Важнейшая часть всего этого — документация. Конечно, для большинства это не новость, но в контексте LLM оно приобретает новый характер.
Все заказы я выполняю, разбивая на этапы. Причём такие этапы, которые заказчик сможет потрогать — оценить и увидеть какой-то результат. На примере fullstack: я не буду первым этапом делать бэк, а вторым фронт. Заказчик не сможет потрогать бэк собственноручно, если он сам не разработчик (что у меня бывало крайне редко). Поэтому необходимо разбить на такие этапы, которые он оценит, назначить им стоимость и длительность. Это прозрачная схема, с которой все заказчики соглашаются.
Это важный момент — так составляется ТЗ именно для заказчика. Но помимо этого я составляю ТЗ и для разработки — документ, в котором написаны основные фичи и структуры. И после я делаю ТЗ отдельно для каждого этапа — подробные, с описанием всех механик и нюансов.
Важно — я всё это делаю в процессе диалога с LLM. Обычно составление такого ТЗ для каждого этапа занимает около двух часов. Мы подробно прорабатываем, LLM задаёт уточняющие вопросы, критикует решения.
Я запрещаю писать примеры кода в документации вообще. Это забивает контекст информацией, которая будет меняться в процессе. Код будет постоянно адаптироваться — поэтому фиксировать определённые решения в виде кода вредно. Лишние фиксации и контекст. Всё должно быть описано словами, понятными мне и разработчикам из моей команды.
Такие документации являются опорой, точкой фиксации, от которой двигается LLM. Ведь известная проблема — модели начинают со временем уходить в далёкие и ненужные дебри, галлюцинировать и забывать о решении старых ошибок, и вообще увольняются... Документация это страхует.
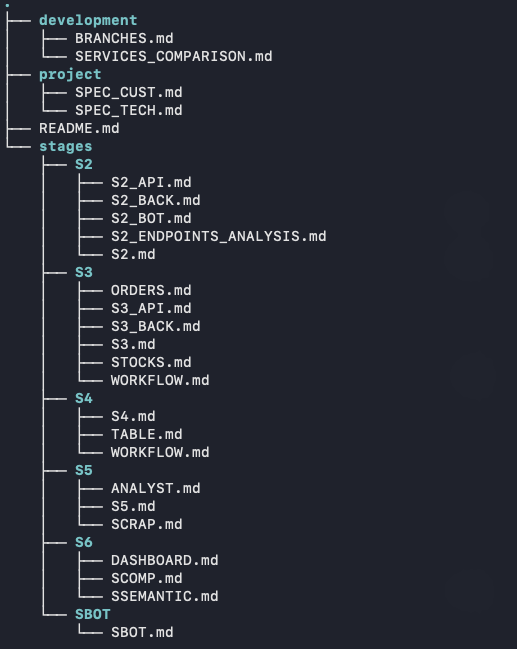
Например, если в проекте 5 этапов, то получается около 2 файлов основных в корне — ТЗ для себя и для заказчика. И около 4 файлов на каждый этап: суть этапа, ошибки, API, структура основной сущности с источниками (например). Итого около 20 документов для заказа длительностью в 2 месяца.
TDD как вторая опора
Реализация кода двигается по принципу TDD — test driven development. Эта техника отлично работает с LLM. Тесты опираются на логику той самой документации и становятся второй точкой опоры и истинности — уже в разрезе фактических результатов и кода.
Я давно заметил, что написание самого кода в разработке с LLM занимает минимум времени — 5–10%, и он всё равно будет с кучей ошибок. 25% — написание документации. 15% — тесты. Остальные 50% — исправление ошибок, ручное тестирование, фидбек от заказчика.
Живая документация
В процессе реализации этапа часто возникают сдвиги относительно документации. Некоторые гипотезы не работают, требуют иных подходов, библиотек. Это нормально. И я фиксирую, что новое решение лучше — очень важно это задокументировать вновь - постоянно актуализирую документацию, чтобы она соответствовала реалиям текущего состояния кода.
Для каждого этапа полезно составлять дополнительные документации в процессе. Например — список нужных API стороннего сервиса с примерами запросов и ответов, как Swagger, к которому быстро и легко обратиться и — важно — отредактировать. Аналогично со списком API бэка — именно эндпоинты, используемые на данном этапе.
### **Шаг 4: Получение заказов (независимо от товаров)**
curl -X GET "https://statistics-api.wildberries.ru/api/v1/supplier/orders?dateFrom=2024-01-01&dateTo=2024-12-31" \
-H "Authorization: Bearer YOUR_WB_API_KEY_HERE" \
-H "Content-Type: application/json"
**Назначение:** Получение заказов за период
**Результат:** Список заказов с детальной информацией
**Статус:** ✅ РАБОТАЕТ (200 OK)
**Базовый URL:** `https://statistics-api.wildberries.ru`
**Параметры:** `dateFrom`, `dateTo` (обязательные)
**Независимо:** Можно выполнять параллельно с шагами 5
### **Шаг 5: Получение отзывов и вопросов (независимо от товаров)**
# Отзывы
curl -X GET "https://feedbacks-api.wildberries.ru/api/v1/feedbacks?isAnswered=false&take=1000&skip=0" \
-H "Authorization: Bearer YOUR_WB_API_KEY_HERE" \
-H "Content-Type: application/json"
# Вопросы
curl -X GET "https://feedbacks-api.wildberries.ru/api/v1/questions?isAnswered=false&take=1000&skip=0" \
-H "Authorization: Bearer YOUR_WB_API_KEY_HERE" \
-H "Content-Type: application/json"
**Назначение:** Получение отзывов и вопросов покупателей
**Результат:** Список отзывов и вопросов с детальной информацией
**Статус:** ✅ РАБОТАЕТ (200 OK)
**Базовый URL:** `https://feedbacks-api.wildberries.ru`
**Независимо:** Можно выполнять параллельно с шагами 4
Если возникает проблема, которая не решается за пару итераций и заводит LLM в цикл — создаём документ ошибки. Фиксируем известную информацию, предполагаем пути решения. И вновь — этот документ становится опорным пунктом для решения проблемы. Мы больше не будем заходить в циклы, так как они документируются в нём, несработавшие решения тоже записываются.
Вся документация также сильно помогает при работе на последующих этапах. Ведь я могу забыть конкретную реализацию какой-то из первых идей, которые работают — но забыл как, и что важно — почему я решил так делать. Эта документация помогает вернуться в прошлое, прояснить ситуацию и иногда адаптировать прошлые механики.
Управление контекстом
Конечно, важно управлять контекстом. Новый этап — новый агент. Новая фича в этапе — новый агент. Новая проблема в этапе — новый агент. Доработка основной архитектуры — у нас есть агент-архитектор, есть агент для API по каждому этапу.
Новых агентов очень легко создавать, когда есть документация — просто отдаём им .md файлы нужного этапа, и готово.
Если вижу цикличность — необходим впрыск нового контекста. Циклы и ошибки возникают, когда LLM начинает петлять по одному и тому же контексту — по кругу, в одном и том же уже переваренном болоте. Тут надо включить фантазию, погуглить и закидывать свои предложения и решения. Что важно — они могут быть бредовыми, слишком креативными, но такие впрыски становятся катализаторами, которые помогают генерировать новый контекст.
В худшем случае, если фантазия кончилась — описать проблему другой модели LLM, получить от неё предложение по решению и передать его в основной чат. Или задокументировать подробно проблему и создать новый чат.
Кстати, о факапах из-за того, что не читаю код — проблема решается более атомарными документами и чатами. Чем меньше и конкретнее единица работы, тем меньше шансов что-то упустить.
Инструменты
До этого момента пользовался такими инструментами: Cursor + Gemini CLI — для фактической разработки, ChatGPT, Sonnet, Grok — для составления начальных ТЗ и документаций, для экономии. То есть - когда составляем ТЗ для всего проекта и этапов — общение идёт в чатах, не в IDE. После долгого общения получаем .md файлы, которые лягут в основу фундамента всего проекта или этапа. Тогда уже переходим к реализации.
У Gemini CLI огромный плюс в его бесплатности и обновлении запросов. Но он чаще входит в циклы. А иногда признается в собственной некомпетентности и забивает на задачу в истерике. В Cursor для сложных задач беру Sonnet, остальные случаи — авто.
Но в этом месяце я решил приобрести подписку Claude, чтобы использовать Claude Code — и вообще теперь в восторге. В терминале работает превосходно. Лимиты возобновляемые, немного дороже Cursor — но это того стоит.
Вообще, если знаешь как работать с LLM — не жалей на них денег. У меня корреляция финансов: рост затрат на LLM на 80% дал прирост дохода на 60%. Конечно, были и другие факторы, но факт такой.
Что работает плохо
Не всё радужно. LLM пока плохо работают со смарт-контрактами, особенно на сети TON. Приходится самому искать примеры, изучать тонкости документации. Более сложные операции с криптой, чем просто транзакции — тоже проблемная область.
С TypeScript модели работают слабее, чем с Python.
Примерно один проект из пяти оказывается проблемным именно из-за таких специфичных областей. По итогу все доходят до релиза, но некоторые требуют значительно больше ручной работы. Поэтому надо пользоваться документами из старых проектов и обращаться к готовым решениям
Результаты и команда
За эти полгода я сделал 5 проектов. Обычно у меня проекты по 2–3 месяца, и я часто веду параллельно до 3 штук.
Самый крупный, которым сейчас занимаюсь — телеграм-бот, ассистент для селлеров маркетплейсов. Уведомления, статистика, аналитика, генерация карточек и фото, RAG, графики и движения по складам. Нашёл двух стажёров. Один новый — только осваивается. С другим уже третий месяц и приносит плоды. Сначала отрицал использование LLM, немного стеснялся этого факта. Но потом, когда я показал как надо работать с документацией и тестами — дело пошло. вообще они умнички.
Мне важно, чтобы заказы делались быстро. Понимание архитектуры, тесты и фиксации ошибок позволяют минимизировать плохой код. Повторные ревью и дополнительные проверки помогают его чистить. Теперь стажёры тоже занимаются именно этим — мыслят как инженеры и архитекторы, а не просто пишут код.
Заказчики, кстати, ни разу не интересовались, работаю ли я с LLM. Но я не скрываю этого факта и считаю это своим преимуществом. Это ни разу не влияло на качество конечных продуктов — заказчики довольны, всё работает.
Важно понимать: такая методика — не способ делать проекты, ничего не понимая в разработке. Надо реально шарить в архитектуре, стеке, технологиях. Понимать как устроены базы данных, как ходят запросы, почему одно решение лучше другого. LLM не заменяет эти знания — он их использует. Просто мы теперь не зацикливаемся на синтаксисе и написании алгоритмов руками. Мы перестали быть печатной машинкой для кода. Но глобально — это и есть разработка. Настоящая. Мышление, проектирование, принятие решений. Если ты не понимаешь, что происходит под капотом — никакая документация и никакой Claude тебя не спасут. Система работает именно потому, что за ней стоит инженер, который знает что делает. LLM — это усилитель, не замена.
Почему это не вайбкодинг
Как ни крути, но разработка перешла на новый уровень. Теперь необходимо мыслить постоянно как инженер и архитектор, надо действительно понимать workflow проекта, потоки данных, оптимизировать архитектуру, вникать в решения проблем на более высоком уровне. И что важно — стажёры тоже теперь занимаются именно этим, а не просто написанием кода.
Это сложный процесс, требующий постоянной концентрации: ведение документации, правильная постановка вопросов, контроль и ещё раз контроль контекста.
Я не могу назвать это "вайбом" — это реально трудоёмкий процесс. Да и кодинга тут нет совсем.
Для меня вайбкодинг — это когда я не спешу со сроками, без требований, сижу и пишу код. Это действительно стало для меня медитативным процессом, приносящим гармонию.
Теперь Вайбкодинг — это классический кодинг, который уже становится… роскошью.










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое