Alibaba представила подробный технический отчет Qwen3-VL

Спустя несколько месяцев после анонса Qwen3-VL компания Alibaba опубликовала детальный технический отчет о своей открытой мультимодальной модели. Данные свидетельствуют, что система исключительно эффективно решает математические задачи на основе изображений и способна анализировать многочасовые видео.
Ключевой особенностью модели является работа с большими объемами данных: система обрабатывает двухчасовые видеоролики или сотни страниц документов благодаря контекстному окну объемом 256 000 токенов.
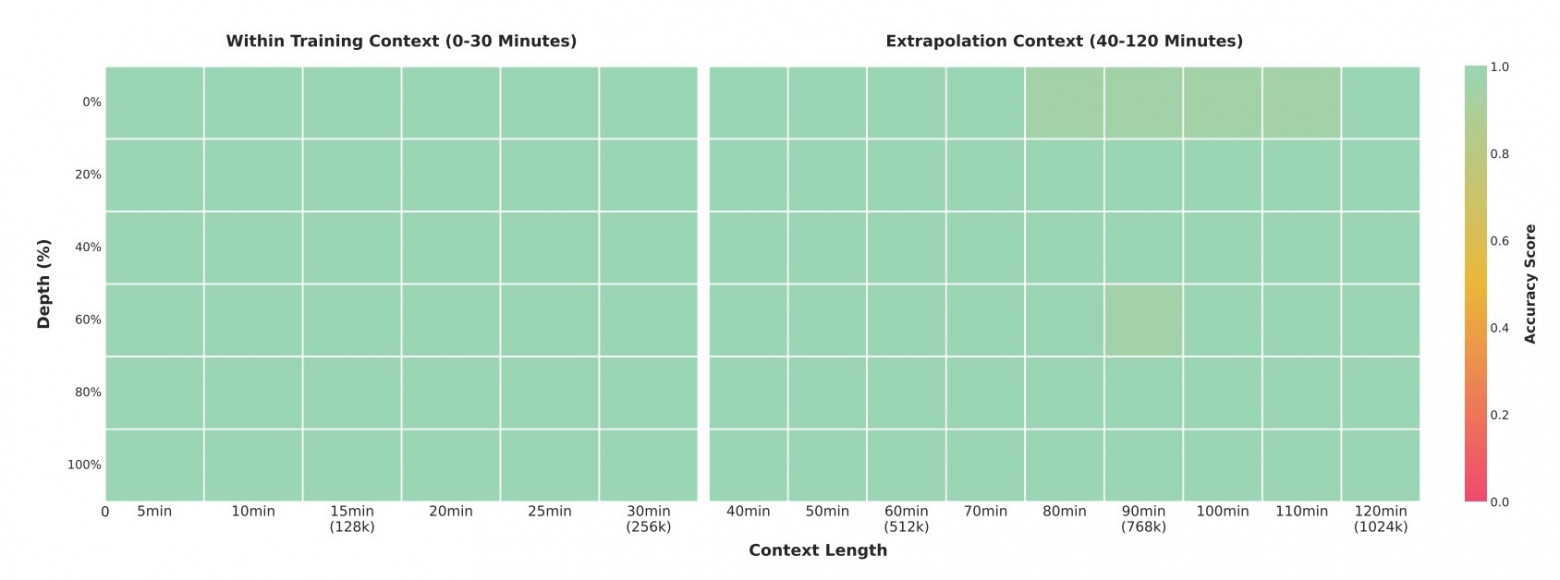
В тестах «иголка в стоге сена» флагманская модель с 235 миллиардами параметров продемонстрировала 100% точность обнаружения отдельных кадров в 30-минутных видео. Даже в двухчасовых роликах объемом около миллиона токенов точность сохранялась на уровне 99,5%. Тест предполагает вставку семантически значимого кадра-иголки в произвольные места длинных видео с последующим поиском и анализом.
В опубликованных бенчмарках модель Qwen3-VL-235B-A14B последовательно превосходит Gemini 2.5 Pro, OpenAI GPT-4o и Claude 3.5 Sonnet, даже когда конкуренты используют расширенные функции логического вывода. Модель демонстрирует абсолютное лидерство в задачах визуального вычисления: 85,8% в MathVista против 81,3% у GPT-4o и 74,6% в MathVision против 73,3% у Gemini 2.5 Pro.
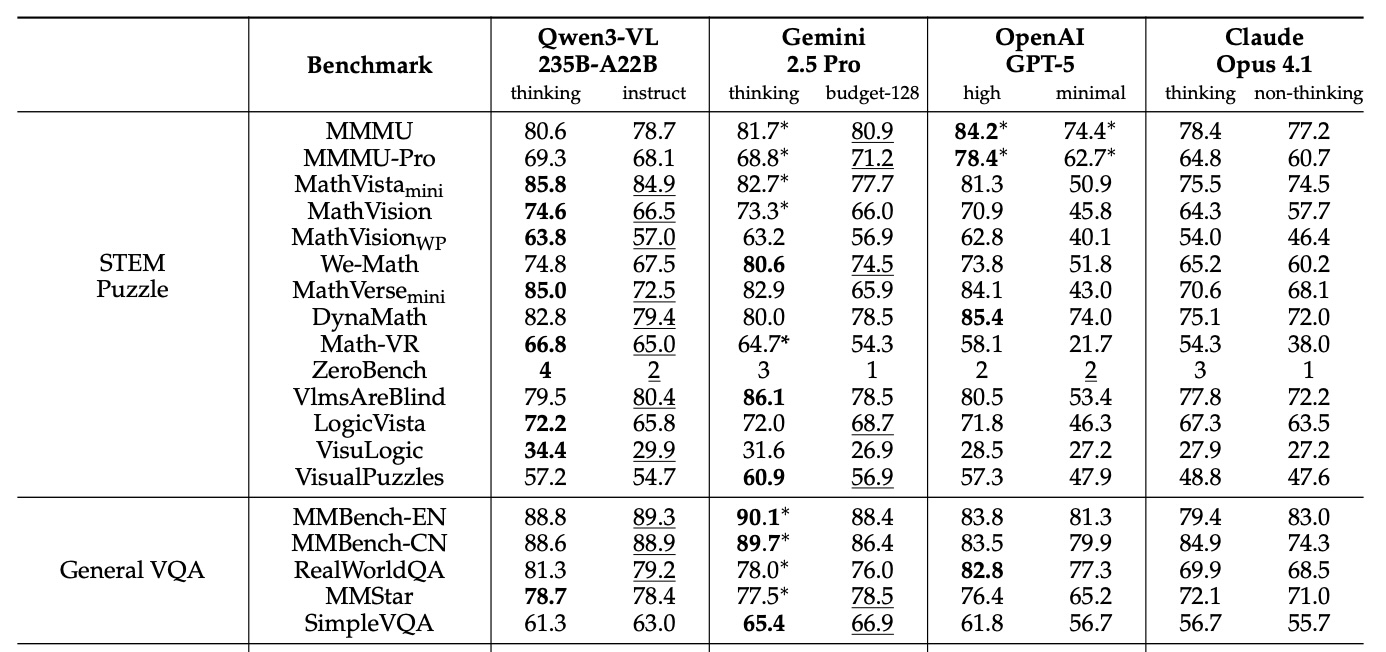
В опубликованных бенчмарках модель Qwen3-VL-235B-A14B последовательно превосходит Gemini 2.5 Pro, OpenAI GPT-4o и Claude 3.5 Sonnet, даже когда конкуренты используют расширенные функции логического вывода. Модель демонстрирует абсолютное лидерство в задачах визуального вычисления: 85,8% в MathVista против 81,3% у GPT-4o и 74,6% в MathVision против 73,3% у Gemini 2.5 Pro.
Система также показывает выдающиеся результаты в специализированных тестах:
-
96,5% в тесте на понимание документов DocVQA
-
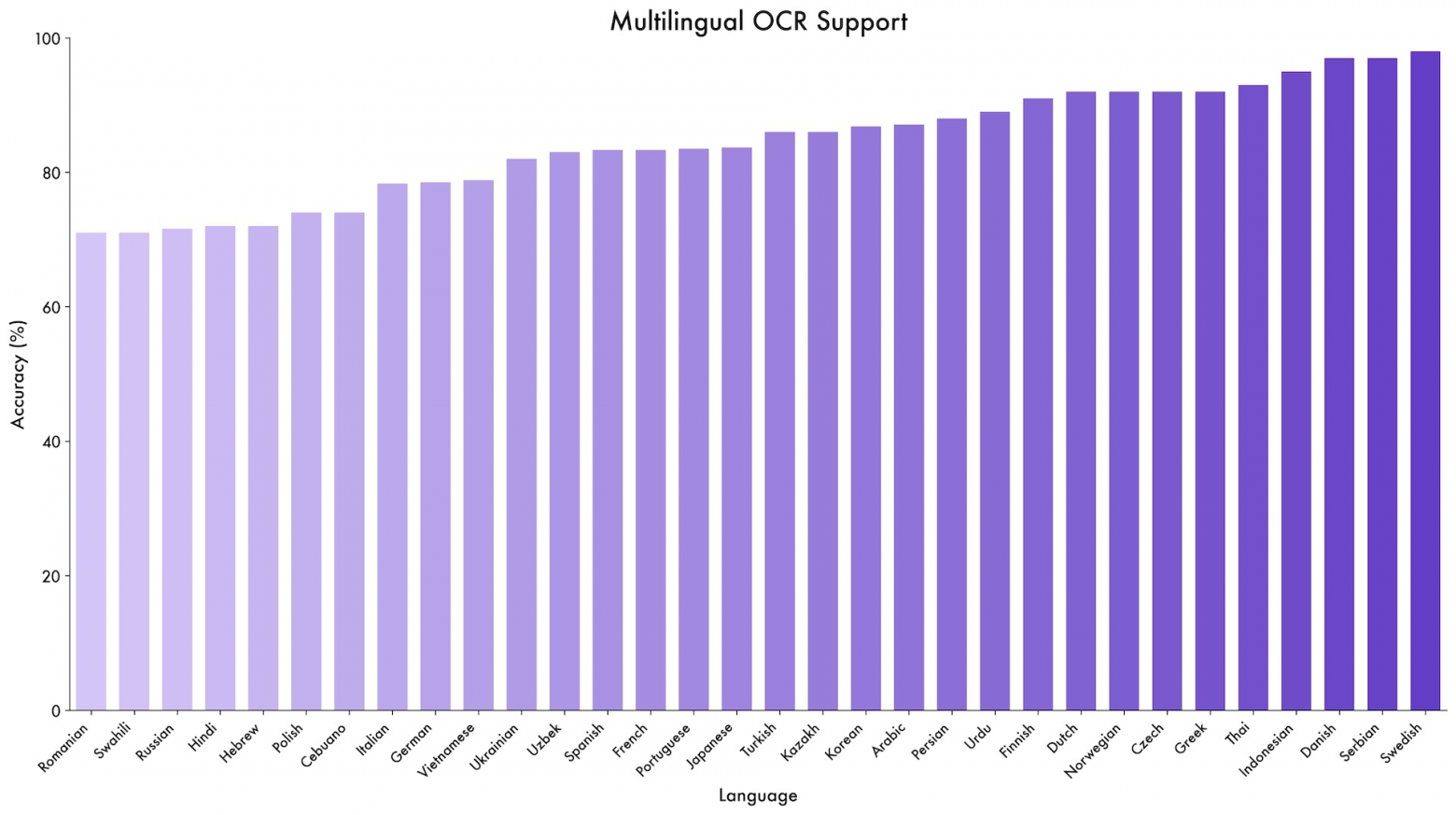
875 баллов в OCRBench с поддержкой 39 языков (почти вчетверо больше предшественника)
-
61,8% точности в ScreenSpot Pro (навигация в графических интерфейсах)
-
63,7% в AndroidWorld (автономное управление приложениями Android)
Модель эффективно обрабатывает сложные многостраничные документы: 56,2% в MMLongBench-Doc и 90,5% в CharXiv при описании научных диаграмм.
Однако модель не лишена слабых мест. В комплексном тесте MMMU-Pro Qwen3-VL набрал 69,3%, уступив GPT-4o (78,4%). Коммерческие конкуренты также сохраняют преимущество в тестах качества видео. Анализ показывает, что Qwen3-VL специализируется на визуальной математике и работе с документами, но все еще отстает в области общих логических рассуждений.
Делегируйте часть рутинных задач вместе с BotHub! Для доступа к сервису не требуется VPN и можно использовать российскую карту. По ссылке вы можете получить 100 000 бесплатных токенов для первых задач и приступить к работе с нейросетями прямо сейчас!










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое