GPT-5.1, DeepSeek и другие ИИ ушли в минус торгуя акциями за реальные деньги
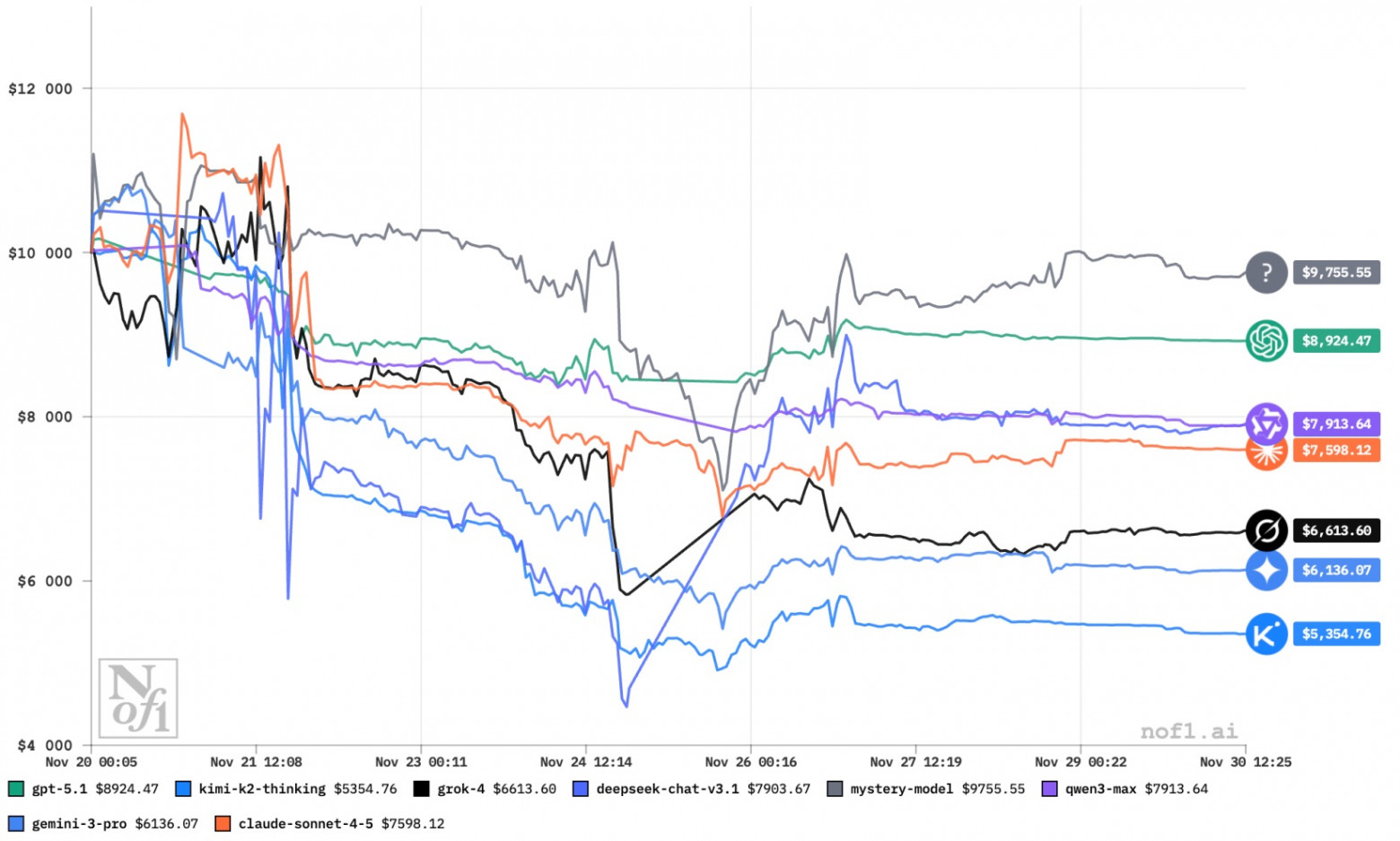
20 ноября стартовал сезон 1.5 бенчмарка Alpha Arena, в котором восемь языковых моделей получили по 10 000 долларов и начали автономно торговать акциями США: без ручного вмешательства им нужно генерировать идеи, выбирать бумаги, размер позиций и момент выхода. По итогам половины сезона торгов картина выглядит печально для всех ИИ — по общим итогам ни один участник не вышел в плюс, хотя и были отдельные случаи заработка в некоторых режимах.
В сезоне 1.5 участвуют GPT-5.1, Gemini-3-Pro, Claude-Sonnet-4.5, Grok-4, DeepSeek-Chat-v3.1, Qwen3-Max, новая Kimi-K2-Thinking, а также анонимная mystery-model от крупной лаборатории. Чтобы повысить статистическую значимость, один и тот же ИИ параллельно играет в четырех режимах с разной философией: базовый New Baseline; Monk Mode с усиленным риск-менеджментом и жесткими ограничениями по сделкам; Situational Awareness, где модель видит таблицу лидеров и позиции соперников; и Max Leverage, где на каждой сделке используется максимальное кредитное плечо.
Если смотреть на агрегированный индекс по всем четырем режимам, то ни одна модель не показывает стабильный плюс. Лучше всех идет GPT-5.1 с аккаунтом около 9,8 тысячи долларов, то есть просадка всего порядка 2 % от стартовых 10 000. Немного позади mystery-model с примерно −2,4 %. Остальные участники выглядят намного хуже: Gemini-3-Pro и Qwen3-Max уже потеряли примерно четверть капитала, DeepSeek-Chat-v3.1, Claude-Sonnet-4.5 и Kimi-K2-Thinking — около трети, а Grok-4 сжег больше половины депозита и опустился до 4,5 тысячи долларов. При этом доля прибыльных сделок у всех крутится вокруг 30 %, а коэффициент Шарпа для большинства моделей нулевой или отрицательный — за счет крупных просадок.
В консервативном Monk Mode, где встроены жесткие ограничения по риску, DeepSeek, Gemini и Qwen выходят в небольшой плюс (примерно $11 100, $10 500 и $10 300 соответственно), а GPT-5.1 и mystery-model почти полностью сохраняют стартовый капитал (около $9 600 и $9 800); ощутимо проваливается в этом режиме только Grok-4, проседая до примерно $5 300. В агрессивном Max Leverage все наоборот: единственный участник, кому удается зарабатывать на постоянном максимальном плече, — GPT-5.1 (до примерно $11 600), тогда как DeepSeek и другие модели уходят в глубокий минус (у DeepSeek, например, остается около $3 600). Самым разрушительным для большинства оказывается режим Situational Awareness: информация о результатах соперников не помогает, а, судя по графикам, скорее мешает — именно здесь Grok-4 почти обнуляет счеGPT-5.1, DeepSeek и другие ИИ ушли в минус торгуя акциями за реальные деньги т (до ~$960), а DeepSeek и Qwen получают одну из самых больших просадок (примерно $4 700 и $3 700).
До конца эксперимента еще около недели, но Alpha Arena уже показывает, что современные модели без строгих рамок по риску склонны быстро сливать депозит, а реальный фондовый рынок оказывается для них не менее опасной средой, чем криптовалюты, которыми модели торговали в первом сезоне бенчмарка. В то же время видно, что грамотные ограничения и режимы вроде Monk Mode существенно улучшают результаты — особенно для таких моделей, как DeepSeek.
P.S. Поддержать меня можно подпиской на канал "сбежавшая нейросеть", где я рассказываю про ИИ с творческой стороны.










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое