Разработчик поменял способ обработки диффов в Cursor и Aider. Точность правок выросла до 10x, но Google его забанил
Все началось с того, что security-исследователь и разработчик Джан Бёлюк (специалист по безопасности и реверс-инжинирингу, интересуется разработкой Windows-ядра, низкоуровневым программированием, статическим анализом кода, криптографией) посмотрел на современные код-агенты и задался вопросом: а что, если дело вовсе не в моделях? Что если GPT-5.3, Opus, Gemini и Grok уже достаточно умны, но мы просто даём им дурацкие инструменты для выражения этой умности?
Спойлер: так и оказалось.
Бёлюк поддерживает опенсорсный проект oh-my-pi (форк агента Pi), в который уже успел вкатить около 1300 коммитов. И в один из дней он поменял ровно одну переменную – ту, что отвечает за формат редактирования файлов. Результат превзошёл ожидания.
Суть проблемы, которую все видели, но никто не хотел решать
В индустрии сложилась парадоксальная ситуация. Большинство ИИ-агентов (Claude Code, Cursor, Aider и прочие) используют для внесения правок либо диффы в стиле OpenAI, либо замену строки по шаблону. У каждого подхода есть недостатки:
-
OpenAI-flavored patch (
apply_patch) отлично работает только на моделях, которые специально обучены этому формату. Стоит дать его Grok 4 – и вы получите 50,7% проваленных патчей. GLM-4.7 отстаёт ненамного – 46,2%. Модели просто не знают этого диалекта. -
Claude Code (
str_replace) требует абсолютно точного совпадения старого текста. Любой лишний пробел, неверный отступ – и ошибка “String to replace not found in file” (с собственным мегатредом на GitHub на 27+ связанных тикетов). -
Cursor решил, что, раз проблема такая сложная, надо натравить на неё ещё одну нейросеть. Они обучили отдельную 70B-модель, которая занимается только тем, что смерживает черновик правки в файл. И даже они признают, что для файлов до 400 строк просто перезаписать всё целиком – надёжнее.
-
Aider в собственных бенчмарках показал, что смена формата диффа поднимала результат GPT-4 Turbo с 26% до 59%, тогда как GPT-3.5 на том же формате выдавал 19% (так как не мог сгенерировать валидный дифф).
Исследователи из JetBrains ещё в 2025 году системно подтвердили: нет единого формата редактирования, который доминировал бы над всеми остальными для любых моделей и сценариев. EDIT-Bench добавил масла в огонь: лишь одна модель на рынке, Claude Sonnet 4, превышает порог в 60% успешных правок с первого раза.
Hashline
Идея Бёлюка заключалась в следующем: что если при чтении файла каждая строка будет возвращаться модели с хеш-тегом из 2–3 символов?
1:a3|function hello() {
2:f1| return "world";
3:0e|}
Когда модель хочет что-то отредактировать, она ссылается именно на эти теги: “Замени строку 2:f1”, “Замени блок с 1:a3 по 3:0e”, “Вставь после 3:0e”. Это как дать нейросети не размытую фотографию текста, а GPS-координаты каждой строчки.
Если файл изменился с момента последнего чтения, хеши не сойдутся – и правка будет отклонена ещё до того, как она успеет что-то сломать. Модели больше не нужно вспоминать точное содержимое старой строки, рассчитывать отступы и гадать, сколько там было пробелов. Она просто говорит: “Сделай вот тут”.
Бенчмарк, который разозлил Google
Бёлюк не стал ограничиваться теорией. Он собрал бенчмарк из реальных файлов React, наполнил их типовыми багами (перепутанные операторы, ошибки неучтённой единицы, инвертированные логические выражения, отсутствующие проверки входных данных и др.) и скормил 16 разным моделям с тремя разными инструментами редактирования.
Пример задачи из бенчмарка:
# Fix the bug in useCommitFilteringAndNavigation.js
A guard clause (early return) was removed.
The issue is in the useCommitFilteringAndNavigation function.
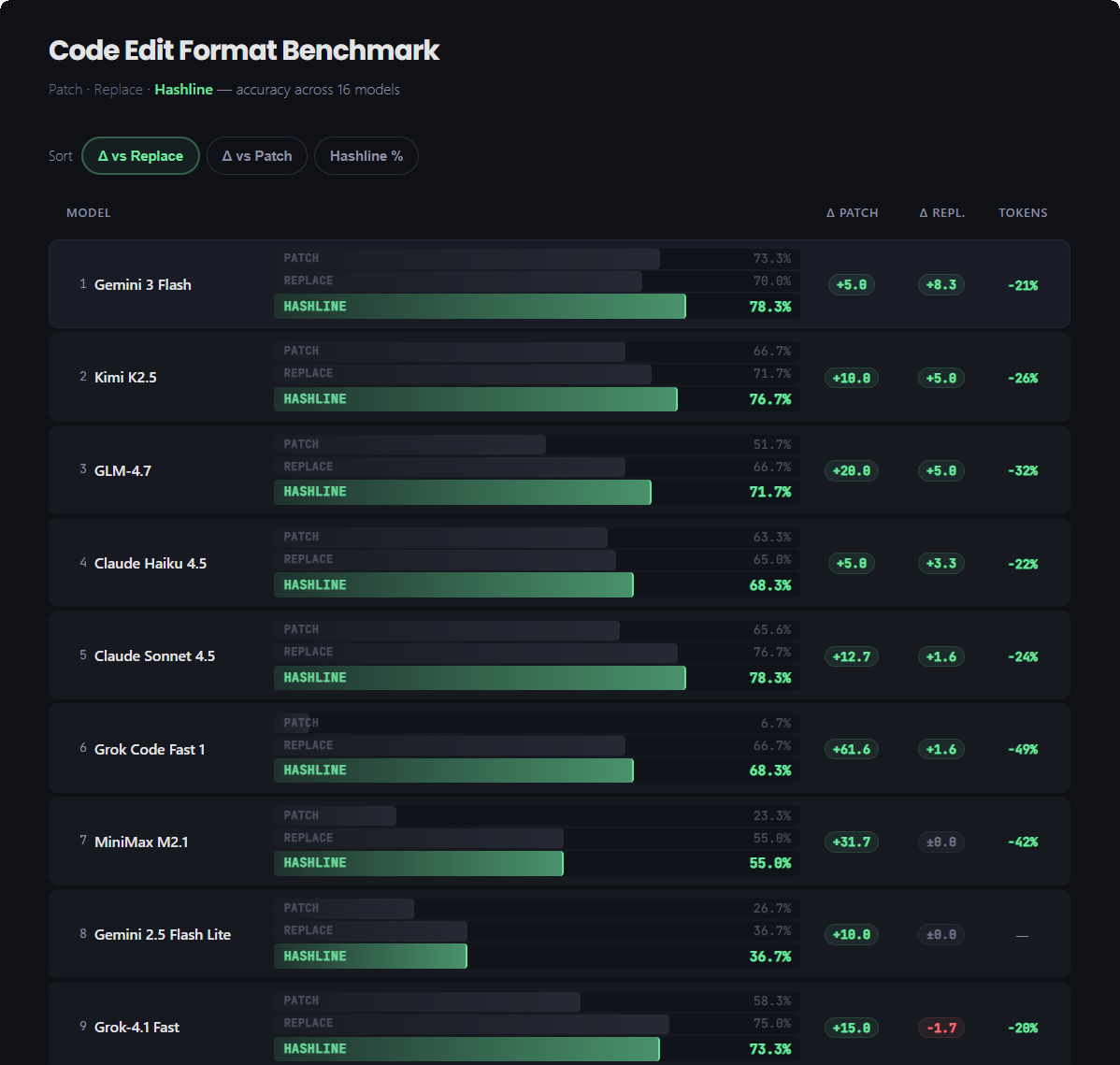
Restore the missing guard clause (if statement with early return).Результаты – безоговорочная победа хешлайна.
-
Grok Code Fast 1 совершил десятикратный скачок: с 6,7% до 68,3%. Формат патчей убивал модель настолько катастрофически, что её реальные способности к кодингу были просто похоронены под завалами механических ошибок.
-
MiniMax улучшил результат более чем в два раза.
-
Grok 4 Fast уменьшил выходные токены на 61% – модель перестала совершать бесконечные циклы повторных попыток.
-
Gemini (в разных версиях) прибавил от 5 до 14 пп.
Здесь история могла бы стать красивым кейсом про то, как опенсорс помогает корпорациям становиться лучше. Но корпорации думают иначе.
Пока Бёлюк писал пост, Google забанил его аккаунт Gemini.
Формальный повод – “Нарушение правил”. Неформальный – бенчмарк показал, что Gemini 3 Flash с техникой хешлайна выдаёт 78,3% успешных правок, что на 5 пп. выше, чем лучшее собственное решение Google.
Бёлюк добавляет, что ни один вендор не будет оптимизировать обвязку под модели конкурентов: Anthropic не будет настраивать формат под Grok, xAI – под Gemini, OpenAI – под Claude. Но опенсорсная обвязка настраивается под всех, потому что контрибьюторы пользуются разными моделями и фиксят те баги, на которые сами натыкаются.
Исходные коды, бенчмарки и отчёты доступны в репозитории: oh-my-pi.
Делегируйте часть рутинных задач вместе с BotHub! Для доступа к сервису не требуется VPN и можно использовать российскую карту. По ссылке вы можете получить 300 000 бесплатных токенов для первых задач и приступить к работе с нейросетями прямо сейчас!










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое