Что такое LLMs.txt и LLMs-full.txt и зачем нам «sitemap для нейросетей»
Мы привыкли к классическому джентльменскому набору любого сайта: robots.txt экономит ресурсы сервера, запрещая поисковикам сканировать мусорные страницы, а sitemap.xml, наоборот, скармливает поисковикам каждую доступную страницу для полной индексации.
Однако ситуация изменилась, когда сайты начали читать не только поисковые роботы, но и языковые модели. Для них существующие стандарты не подходят: Sitemap избыточен и ресурсоёмок, а HTML-код создаёт слишком много шума.
Возникла необходимость в способе доставки актуального, очищенного контекста в сжатом виде. Это важно как для AI-агентов и встроенных в поисковики моделей, так и стратегически: логично предположить, что при сборе датасетов крупные игроки будут отдавать приоритет именно таким структурированным источникам, предпочитая их сырому HTML.
В сентябре 2024 года Джереми Ховард (создатель fast.ai) предложил решение в виде стандарта /llms.txt. Давайте разберемся, как он работает, чем отличается от llms-full.txt и как внедрить его у себя.
Проблема: HTML нужен только людям
Когда вы просите ChatGPT, Gemini, Perplexity или Cursor прочитать документацию библиотеки, чтобы написать код, модель сталкивается с несколькими проблемами:
-
Технические барьеры и глубина: LLM - не поисковые роботы. В чат-интерфейсах модели часто "ленятся" или технически не могут переходить по десяткам ссылок. Если вы дадите ссылку на корень документации, модель часто прочитает только эту страницу. Кроме того, многие сайты построены как SPA-приложения и требуют выполнения jаvascript, с чем встроенные браузеры LLM нередко не справляются, видя лишь пустой
<div id="root"></div> -
Грязные данные: Современные сайты - это смесь HTML, CSS, jаvascript, рекламных блоков и навигации, которые бесполезно расходуют токены. Даже у моделей с контекстом в миллион токенов есть предел "внимания". Скармливать им весь сайт целиком - это дорого и снижает качество ответов.
-
Отсутствие приоритетов: sitemap.xml содержит ссылки на всё подряд. LLM не знает, какие страницы важны, а какие второстепенны, устарели или носят юридический характер.
Решение: стандарт /llms.txt
Идея состоит из трех компонентов, которые превращают ваш сайт, документацию или библиотеку в AI-friendly ресурс.
1. Markdown-зеркала страниц
Первая часть предложения - создавать "чистые" версии страниц. Если у вас есть страница документации docs/api.html, по тому же адресу (или с суффиксом .md) должен быть доступен файл с чистым содержимым в Markdown-формате, например:
-
docs/api.html.md -
docs/api.md
2. Индексный файл /llms.txt
Это Markdown-файл в корне сайта, выполняющий роль карты. Он предоставляет краткое описание проекта и список ссылок на подготовленные .md-файлы, а также их краткие аннотации. Благодаря этому модель быстро понимает структуру проекта и знает, где искать детали.
3. Файл полного контекста /llms-full.txt
(В спецификации FastHTML он также называется llms-ctx-full.txt, но такую вариацию почти никто не использует).
Этот файл формируется автоматически. Специальный скрипт парсит ваш llms.txt, проходит по всем ссылкам, скачивает содержимое зеркал и склеивает их в один большой текстовый файл.
Зачем это нужно?
Этот файл собирает весь контекст проекта в единый документ. Это позволяет передать агенту или модели 100% актуальных знаний о библиотеке одним запросом, исключая риск ошибок навигации, потери информации или галлюцинаций.
Структура файла llms.txt
Хотя Markdown понятен нейросетям и без строгой схемы, спецификация требует соблюдения определенного порядка секций. Это нужно, чтобы классические инструменты (парсеры, CLI-утилиты) могли автоматически собирать контекст.
Порядок элементов следующий:
-
Заголовок H1: название проекта или сайта (обязательный элемент).
-
Цитата (Blockquote): Краткое саммари проекта. Самая важная информация.
-
Описание (Markdown): Произвольный текст с деталями, инструкциями или подсказками для модели.
-
Секции ссылок (Заголовки H2, H3 и т.д.): тематические разделы с перечислением ссылок.
-
Внутри списки вида: [Название](ссылка): Краткое описание
-
ссылки должны вести на Markdown-файлы, а не HTML
-
-
Секция "Optional" (H2): ссылки на второстепенные материалы. Они игнорируются при сборке сжатого контекста, но попадают в полную версию.
Укороченный пример файла:
# FastHTML
> FastHTML is a Python library that brings together Starlette, Uvicorn, and HTMX for creating server-rendered hypermedia applications.
Things to remember:
- Although its API is inspired by FastAPI, it is not compatible with its syntax.
- It is compatible with vanilla JS, but not with React, Vue, or Svelte.
## Docs
- [FastHTML concise guide](https://www.fastht.ml/docs/ref/concise_guide.html.md): A brief overview of idiomatic FastHTML apps
## API
- [API List](https://www.fastht.ml/docs/apilist.txt): A succint list of all functions and methods in fasthtml.
## Optional
- [FAQ](https://www.fastht.ml/docs/explains/faq.html.md): Answers to common questions about FastHTML.
(Оригинал файла можно посмотреть здесь)
Как внедрить (плагины и инструменты)
Поддерживать два набора документации (HTML и Markdown) вручную не вариант. Несмотря на молодость стандарта, для большинства популярных CMS и генераторов уже есть готовые решения.
GitBook: Полностью встроенная поддержка.
nbdev: Инструмент от fast.ai генерирует по умолчанию.
Python экосистема:
-
MkDocs: плагин mkdocs-llmstxt
-
Sphinx: sphinx-llms-txt
jаvascript / Node.js
-
Docusaurus: Плагин docusaurus-plugin-llms
-
VitePress: Плагин vitepress-plugin-llms
-
Gatsby: Плагин gatsby-plugin-llms-txt
-
Eleventy (11ty): Плагин eleventy-plugin-llms
-
Astro: Плагин astro-llms-txt
CMS
-
WordPress: Плагины odyssey-llms и llms-full-txt-generator
-
Drupal: модуль llms_txt
Похожие инструменты можно найти по запросам в поисковиках и на github:[ваш_фреймворк] llms.txt или llms.txt generator.
Кто уже использует
Хотя llms.txt это инициатива сообщества, а не утвержденный W3C или IETF стандарт, индустрия де-факто приняла его. Несмотря на отсутствие формальной спецификации, он уже применяется в продакшене крупнейших компаний.
Среди внедривших:
-
Amazon AWS: llms.txt | llms-full.txt
-
X (Twitter): llms.txt | llms-full.txt
-
Stripe: llms.txt
-
Docker: llms.txt
-
Cloudflare: llms.txt | llms-full.txt
-
Redis: llms.txt | llms-full.txt
-
Vue.js: llms.txt | llms-full.txt
-
Svelte: llms.txt | llms-full.txt
-
Angular: llms.txt
-
VitePress: llms.txt | llms-full.txt
-
Claude: llms.txt | llms-full.txt
-
Anthropic (MCP): llms.txt | llms-full.txt
-
Perplexity: llms.txt | llms-full.txt
-
Cursor: llms.txt | llms-full.txt
-
ElevenLabs: llms.txt | llms-full.txt
Интерес со стороны разработчиков подтверждает и статистика GitHub. Количество репозиториев в которых есть файл llms.txt исчисляется тысячами.
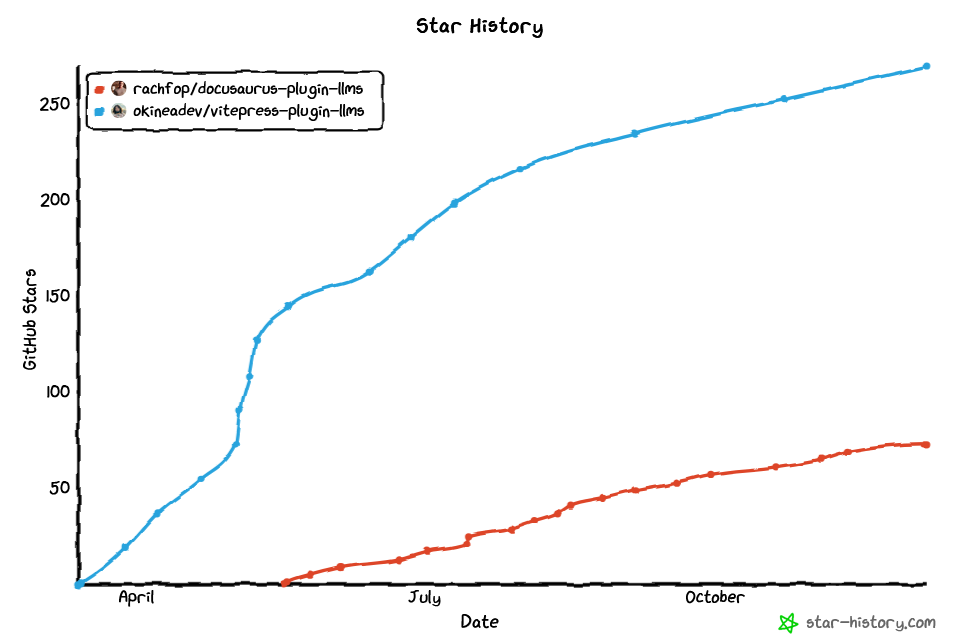
Динамика популярности плагинов для генерации тоже показательна. Вот, например, как рос интерес некоторым плагинам в этом году:
Лайфхак для разработчиков
Пользу от стандарта можете извлечь и вы. Попробуйте при изучении документации новой библиотеки допишите к её адресу /llms-full.txt. Если разработчики внедрили этот стандарт, вы мгновенно получите весь необходимый контекст в одном файле, очищенном от визуального шума.
Загрузив этот файл в LLM с большим контекстным окном, например Gemini 3 вы решаете проблему устаревших знаний и галлюцинаций: модель перестает выдумывать несуществующие методы из версий двухлетней давности и начинает отвечать строго по свежей документации.
Так вы получаете точные ответы на вопросы и возможность комфортного вайбкодинга с актуальным стеком без необходимости вручную копировать десятки страниц или настраивать сложные парсеры.
Заключение
Стандарты llms.txt и llms-full.txt стремительно превращаются в новый базовый формат представления знаний для языковых моделей. Несмотря на отсутствие формальной спецификации, они уже стали практическим стандартом де-факто: разработчики крупных корпораций и open-source-сообществ активно внедряют их в документацию и публичные сайты.
Разработчики всё чаще получают ответы на вопросы не из поисковиков, а от AI-ассистентов: Cursor, Claude, ChatGPT, Perplexity. Это меняет саму природу SEO: оптимизация становится ориентированной не только на поисковые алгоритмы, но и на языковые модели, которые формируют значительную часть трафика и влияют на видимость бренда. Чистые Markdown-зеркала и понятная структура llms.txt повышают шансы вашего проекта корректно попасть в AI-датасеты, улучшить качество ответов LLM и, как следствие, повысить "AI-видимость". Если ваша новая документация плохо читается LLM, она фактически перестаёт существовать для значительной части аудитории.
Добавление двух файлов в корень сайта это простое, дешёвое и стратегически важное улучшение, которое одновременно усиливает традиционное SEO, улучшает AI-доступность контента и готовит ваш проект к будущему, где веб читают не только люди, но и агенты.
Полезные ссылки:
-
llmstxt.org - Официальная страница стандарта
-
llmstxt.site - Каталог сайтов, которые уже внедрили стандарт.
-
directory.llmstxt.cloud - Еще один каталог сайтов внедривших стандарт










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое