Как за сутки обойти миллиард веб-страниц

TL;DR:
-
1,005 миллиарда веб-страниц
-
25,5 часа
-
$462
По какой-то причине уже долгое время никто не писал о том, что требуется для краулинга большой части веба: последним обнаруженным мной источником был пост Майкла Нильсена за 2012 год[1].
Очевидно, что за это время много изменилось. Всё стало больше, лучше и быстрее: у CPU появилось намного больше ядер, на смену жёстким дискам пришли твердотельные накопители NVMe, скорости ввода-вывода которых сравнимы со скоростями RAM, существенно выросла ширина сетевых каналов, существенно расширился список типов инстансов EC2 и так далее. Но в чём-то ситуация и усложнилась: гораздо бóльшая часть веба стала динамической, а контент теперь более тяжёлый. Как поменялось состояние Интернета? Теперь узкие места стали другими, и для создания своего Google по-прежнему нужно около 41 тысячи долларов? Мне захотелось это узнать, поэтому я собрал и выпустил собственный веб-краулер1 в условиях похожих ограничений.
Формулировка задачи
Лимит времени: 24 часа. Я подумал, что, судя по предварительным экспериментам, миллиард страниц вполне можно скраулить за день, а «40 часов» звучит не так круто. В конечном итоге, среднее время активности каждой машины составило 25,5 часа с небольшим разбросом. Здесь не учтены несколько часов тех машин, которые пришлось перезагружать.
Бюджет: несколько сотен долларов. Краулинг Нильсена стоил чуть меньше $580. Мне посчастливилось иметь свободную сумму, и я нацелился на то, чтобы мой эксперимент стоил примерно столько же. Финальный прогон, включающий только 25,5 активного часа стоил примерно $462. Также я провёл множество мелких экспериментов в процессе оптимизации одноузловой машины (которые стоили гораздо меньше) и второй крупный эксперимент, чтобы понять пределы вертикального масштабирования (я завершил его преждевременно, но затраты были примерно такими же).
Только HTML. Проблема, которую стоит упомянуть: даже к 2017 году большая часть веба уже требовала jаvascript. Но мне хотелось провести адекватное сравнение с предыдущими экспериментами по веб-краулингу; к тому же это был мой хобби-проект и у меня не было времени на добавление и оптимизацию кучи воркеров Playwright. Поэтому я работал по старинке: запрашивал все ссылки, но не выполнял JS, просто парсил HTML в его неизменном виде и добавлял на фронтир все ссылки из тэгов <a>. Мне было любопытно ещё и то, какую часть веба можно скраулить подобным образом; оказалось, что довольно большую!
Вежливость. Она крайне важна! Я прочитал пару историй (пример) о том, сколько проблем возникает у админов из-за крупномасштабных веб-краулеров, не уважающих robots.txt, выдающих себя за другие агенты для избегания блокировок и бесцеремонно атакующих конечные точки. Я придерживался этичных практик: соблюдал robots.txt, добавлял информативный user agent, содержащий мою контактную информацию, хранил список исключённых доменов, который мог расширять по просьбам владельцев, ограничился своим исходным списком из одного миллиона самых популярных доменов, чтобы не вредить мелким персональным страничкам, и установил задержку в 70 между обращениями к одному и тому же домену.
Устойчивость к сбоям. Это было важно на случай, если мне придётся по какой-то причине останавливать и возобновлять краулинг (так и случилось). Кроме того, это сильно помогло в экспериментах, потому что в моей единовременной процедуре краулинга характеристики производительности зависели от состояния: начало краулинга сильно отличалось от установившегося процесса работы. Я не стремился к идеальной устойчивости к сбоям; меня вполне устраивала потеря части посещённых сайтов после вылета или сбоя, потому что мой краулинг, по сути, был выборкой веба.
Архитектура в целом
Архитектура, к которой я пришёл в итоге, сильно отличалась от типичного решения для создания краулера из собеседований по проектированию систем, в котором функции (парсинг, загрузка, хранение данных, хранение состояния краулинга) разнесены на отдельные пулы машин. Я же выбрал кластер из десятка высокооптимизированных независимых узлов, каждый из которых включал в себя всю функциональность краулера и обрабатывал шард доменов. Я сделал так, потому что:
-
Мой бюджет для экспериментов и финального прогона был ограничен, поэтому мне показалось логичным начинать с малого, запихнуть как можно больше в одну машину, а потом масштабировать эту систему.
-
На самом деле, изначально моя цель заключалась в максимизации производительности одной машины, а не в краулинге миллиарда страниц за 24 часа (эта идея возникла уже на полпути). Даже после добавления этой цели я всё равно был очень оптимистично настроен относительно вертикального масштабирования, отказавшись от него и перейдя к кластеру только тогда, когда близился назначенный мной дедлайн.
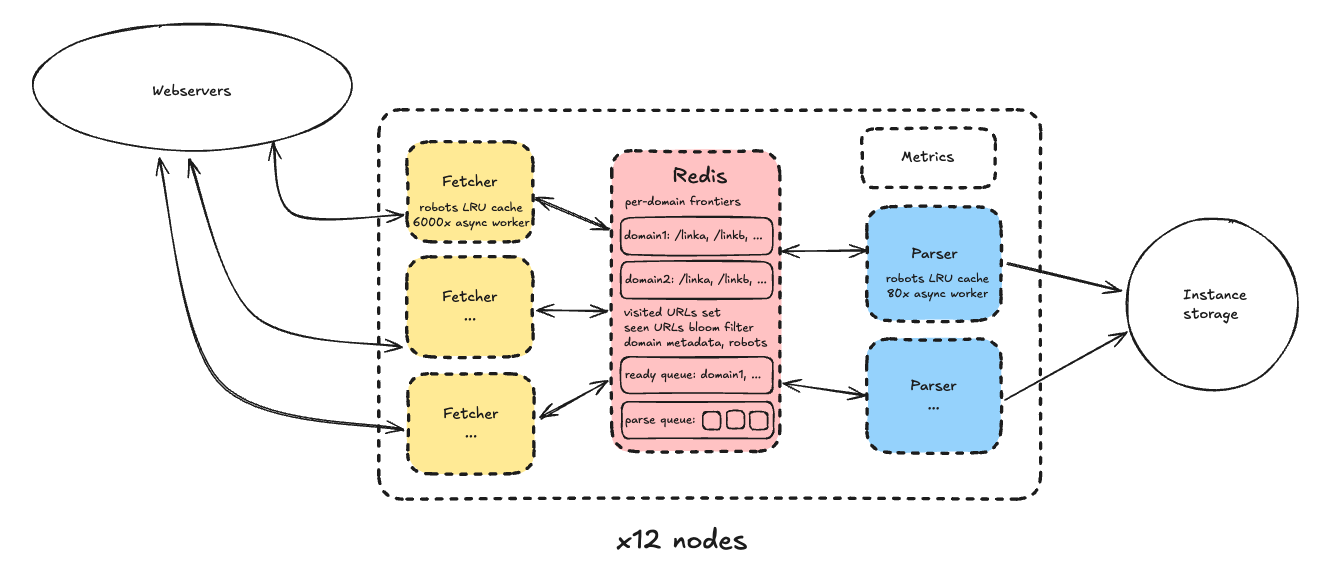
Содержимое каждого узла было таким:
-
Один инстанс Redis, хранящий структуры данных, которые описывают состояние краулинга:
-
Фронтиры для каждого домена, то есть списки URL для краулинга
-
Очередь доменов, упорядоченная по следующей метке времени повторного запроса по истечении их интервала задержки2
-
Записи для всех посещённых URL, где с каждым URL связаны метаданные и путь к сохранённому на диске контенту3
-
Фильтр Блума для просмотренных URL, чтобы можно было быстро определять, добавлен ли уже URL во фронтир. Он отделён от записей посещённых URL, потому что нам не нужно добавлять URL во фронтир, если он уже там, но ещё не загружен. Небольшая вероятность ложноположи��ельных срабатываний4 фильтра Блума меня устраивала, потому что, повторюсь, я решил, что мой краулинг был выборкой Интернета, поэтому оптимизировался по скорости.
-
Метаданные доменов, в том числе то, добавлен ли домен вручную в список исключённых, является ли он частью исходного списка, а также полное содержимое его robots.txt (+ временная метка завершения срока действия robots).
-
Очередь парсинга, содержащая загруженные страницы HTML для дальнейшей обработки парсерами.
-
-
Пул процессов загрузки:
-
Процессы загрузки работали в простом цикле: извлечение следующего готового домена из Redis, получение следующего URL из его фронтира и загрузка (+ удаление домена из очереди готовых), затем запись результата в очередь парсинга.
-
Каждый процесс упаковывал при помощи asyncio высокую конкурентность в одно ядро; я эмпирическим путём выяснил, что процессы загрузки могут поддерживать 6000-7000 «воркеров» (независимых асинхронных циклов загрузки). Стоит отметить, что при этом системе было далеко до перегрузки пропускной способности сети: узким местом был CPU, к чему я вернусь ниже. Асинхронная архитектура — это разновидность многозадачности в пользовательском пространстве, она долгое время была популярна в системах с высокой конкурентностью (Python Tornado появился в 2009 году!), потому что позволяет полностью избежать переключения контекста.
-
И загрузчики, и парсеры также хранили кэши LRU важных данных доменов, например, содержимое robots.txt, чтобы минимизировать нагрузку на Redis.
-
-
Пул процессов парсеров:
-
Парсеры работали аналогично загрузчикам; каждый состоял из 80 асинхронных воркеров, которые подтягивали следующий элемент из очереди парсинга, парсили HTML-контент, извлекали ссылки для записи во фронтиры соответствующих доменов в Redis и записывали сохранённый контент в постоянное хранилище. Конкурентность здесь была гораздо ниже потому, что ограничивающим фактором был CPU, а не ввод-вывод (хотя парсерам всё равно нужно общаться с Redis и время от времени загружать robots.txt), а 80 воркеров было достаточно, чтобы загрузить CPU работой.
-
-
Прочее:
-
Для постоянного хранения я воспользовался технологией instance storage. В советах по прохождению собеседований порекомендовали бы применить S3; я думал об этом, ��о S3 берёт оплату в зависимости от количества запросов, а также пропорционально ГБ-месяцам; если принять средний размер страницы равным 250 КБ (всего 250 ТБ), то для хранения 1 миллиарда страниц всего в течение одного дня мне бы понадобилось
0.022*1000*250*(1/30)+0.005*1e6= $5183,33 при стандартном тарифе или0.11*1000*250*(1/30)+0.00113*1e6= $2046,67 при Express, что на порядок величин больше, чем в конечном итоге потратил я! Даже если закрыть глаза на все затраты на PUT, то для хранения моих данных в течение дня понадобилось бы $183,33 на стандартном тарифе или $916,67 на Express, то есть если бы даже я объединял страницы, то цена оказалась бы неподъёмной. -
В конечном итоге я выбрал оптимизированные на хранение инстансы серии
i7i, и урезал сохранённые страницы, чтобы они точно уместились. Очевидно, в случае реального краулера урезание было бы плохой идеей; я думал об использовании быстрого способа сжатия в парсере наподобие snappy или более медленного алгоритма сжатия в фоновом режиме, но у меня не хватило времени, чтобы проверить эту мысль. -
Первый процесс загрузчика в пуле назначался «главным» и периодически записывал метрики в локальную базу данных Prometheus. В реальной системе было бы лучше иметь одну базу данных метрик для всех узлов.
-
Итоговое содержимое кластера:
-
12 узлов
-
Каждый — это машина
i7i.4xlargeс 16 vCPU, 128 ГБ ОЗУ, пропускной способностью сети 10 Гбит/с и 3750 ГБ хранилища инстанса -
В основе каждого лежит 1 процесс Redis + 9 процессов загрузчиков + 6 процессов парсеров
Исходный список доменов шардился между всеми узлами кластера без обмена данными между узлами. Так как я выполнял краулинг только доменов из списка, узлы краулили собственные непересекающиеся области Интернета. В основном причиной этого было то, что мне не хватило времени на реализацию альтернативной архитектуры (с обменом данными между узлами).
Почему всего 12 узлов? В одном из экспериментов выяснилось, что шардинг доменов из списка на слишком большое количество узлов приводил к серьёзной проблеме горячих шардов: узлам, которым достались очень популярные домены, приходилось выполнять большой объём работы, а другие завершали её быстро. Кроме того, я ограничил вертикальное масштабирование пулов загрузчиков и парсеров 15 процессами на один процесс Redis, потому что Redis начал достигать показателя 120 операций/с, а я читал, что это может вызвать проблемы (если бы было больше времени, я бы поэкспериментировал, чтобы найти точную точку насыщения).
Исследованные альтернативы
Прежде, чем остановиться на описанной выше архитектуре, я изучил ещё несколько. Похоже, самые современные краулеры[1][2][3] используют быстрое хранилище данных в памяти наподобие Redis, и на то есть веские основания. Я создал маломасштабные прототипы с бэкендами на SQLite и PostgreSQL, но выполнение запросов к фронтиру было чрезмерно сложным, несмотря на концептуальную простоту структуры данных. В этом исследовании мне очень помогли ИИ-инструменты; я писал об этом в отдельном посте.
Кроме того, я приложил много усилий к вертикальному масштабированию отдельного узла; я был настроен оптимистично, потому что многие препятствия, мешавшие предыдущим опытам масштабного краулинга[1][4] на основе распределённых систем, похоже, теперь не актуальны. Например, AWS предлагает инстанс i7i.48xlarge, который, по сути, просто состоит из слепленных вместе 12 машин i7i.4xlarge. Он имеет гораздо меньшую пропускную способность сети (100 Гбит/с вместо 12x25 Гбит/с), но при скорости, необходимой для обхода 1 миллиарда страниц за 24 часа, даже если каждая страница будет весить 1 МБ (а это не так), я займу всего 8*1e6*(1e9/86400)=92 Гбит/с и ещё останется ресурс на исходящие соединения (которые явно меньше, чем 1 МБ на запрос!).
Первая попробованная мной крупномасштабная архитектура упаковывала всё в один i7i.48xlarge, упорядочивая процессы в «поды», которые во многом напоминали узлы в моём финальном кластере (группы из 16 процессов с одним инстансом Redis), но с разрешённым обменом данными. Во второй архитектуре я отказался от обмена данных и просто запустил независимые поды; большой прогон этого эксперимента привёл к разочаровывающим результатам (вся система могла обеспечивать всего 1 тысяч страниц/с, что было лишь ненамного больше, чем пропускная способность одного узла в финальном кластере). У меня закончилось время, поэтому я сдался и перешёл к горизонтальному масштабированию. Подозреваю, что ограничивающим фактором может быть скорее ПО (ресурсы операционной системы), нежели оборудование.
Выводы
Парсинг — критичное узкое место
Меня очень удивило то, насколько серьёзным узким местом оказался парсинг. В финальной системе мне пришлось распределять процессы в соотношении парсинга к загрузке 2:3, но изначально всё было иначе, и для того, чтобы прийти к этому, потребовалось множество итераций. На самом деле, в первой системе с разделением процессов парсинга и загрузки нужно было два парсера, чтобы поспевать за одним (частично простаивающим) загрузчиком с 1000 воркеров, обрабатывающих 55 страниц/с. Реально казалось, что парсинг не позволит мне обойти миллиард страниц, уложившись в бюджет!
Это меня очень удивило, потому что из этого следовало, что мой четырёхъядерный узел не достигал той же пропускной способности, чем более слабый четырёхъядерный компьютер в 2012 году. Профилирование показало, что узким местом определённо оказывался парсинг, но я использовал ту же библиотеку парсинга lxml, которая была популярна в 2012 году (её рекомендовал Gemini). В конечном итоге я разобрался в причинах: средняя веб-страница стала намного больше: метрики тестового прогона показали, что размер несжатой страницы в P50 теперь равен 138 КБ5, а средней ещё больше, 242 КБ — это во много раз больше, чем ожидавшийся Нильсеном в 2012 году средний размер в 51 КБ!
Больше всего мне помогли мне два изменения:
-
Я переключился с
lxmlнаselectolax: гораздо более новую библиотеку, обёртывающую Lexbor — современный парсер на C++, спроектированный специально для HTML5. На его странице утверждается, что он в 30 раз быстрее, чем lxml. В итоге оказалось, что не в 30 раз, но прирост производительности был огромным. -
Кроме того, до передачи страницы парсеру я урезал её содержимое до 250 КБ. Так как порок урезания выше среднего и почти вдвое больше медианы, думаю, аргументация из работы Нильсена[1] по-прежнему актуальна: большинство веб-страниц сохраняется полностью, чего должно быть достаточно для большинства областей применения.
В такой схеме мне удавалось достичь парсинга примерно 160 страниц в секунду одним процессом парсера, что позволило моей финальной архитектуре краулить примерно 950 страниц/с при помощи девяти загрузчиков и шести парсеров.
Загрузка: одновременно и проще, и сложнее
Во многих проектах краулинга считалось, что важные узкие места — это пропускная способность сети и DNS. Например, в процессе изучения этой темы я написал Джейми Кэллену из Университета Карнеги-Меллона, чтобы проконсультироваться по поводу проекта Sapphire 2009 года[4]; профессор Кэллен сообщил, что узким местом в нём была скорость DNS-ресолвинга, а в проекте 2012 года, где использовалась сеть кампуса Университета, скорость краулинга приходилось ограничивать, чтобы не задействовать всю пропускную способность. В анализе собеседований Эвана Кинга, написанном примерно год назад, тоже рекомендуется оптимизировать DNS-ресолвинг.
В моём проекте проблема DNS вообще не возникала. Думаю, дело в том, что я ограничил краулинг моим исходным списком популярного миллиона доменов. Пропускная способность сети тоже и близко не была к насыщению ни для одного узла кластера; при установившемся режиме работы большинство узлов потребляло примерно 1 ГБ/с (8 Гбит/с), а максимальная пропускная способность для i7i.4xlarge равна 25 Гбит/с. Пропускная сетевая способность дата-центров сегодня избыточна, особенно для ИИ: AWS предлагает инстанс P6e-GB200 с 28,8 терабитами пропускной способности сети!
Тем не менее, одна из частей процесса загрузки стала сложнее по сравнению с тем, что было десяток лет назад: гораздо больше веб-сайтов сегодня использует SSL. Это стало абсолютно очевидно при профилировании: вычисления SSL handshake были в нём самым затратным вызовом функции, занимающим в среднем аж целых 25% от всего времени CPU; учитывая отсутствие насыщения сетевых каналов, это означало, что для загрузки узким местом гораздо быстрее становится CPU, чем сеть!
Масштабный краулинг
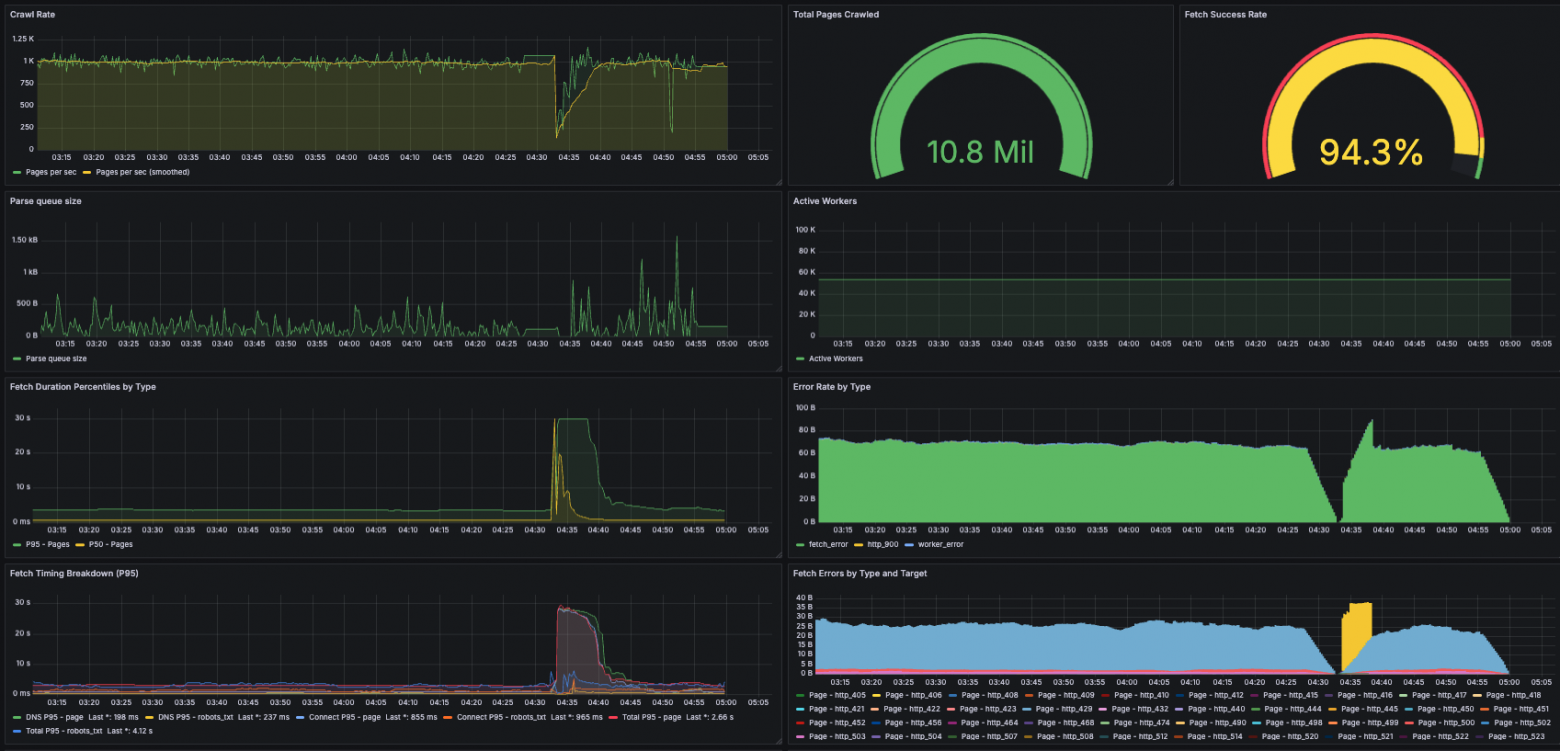
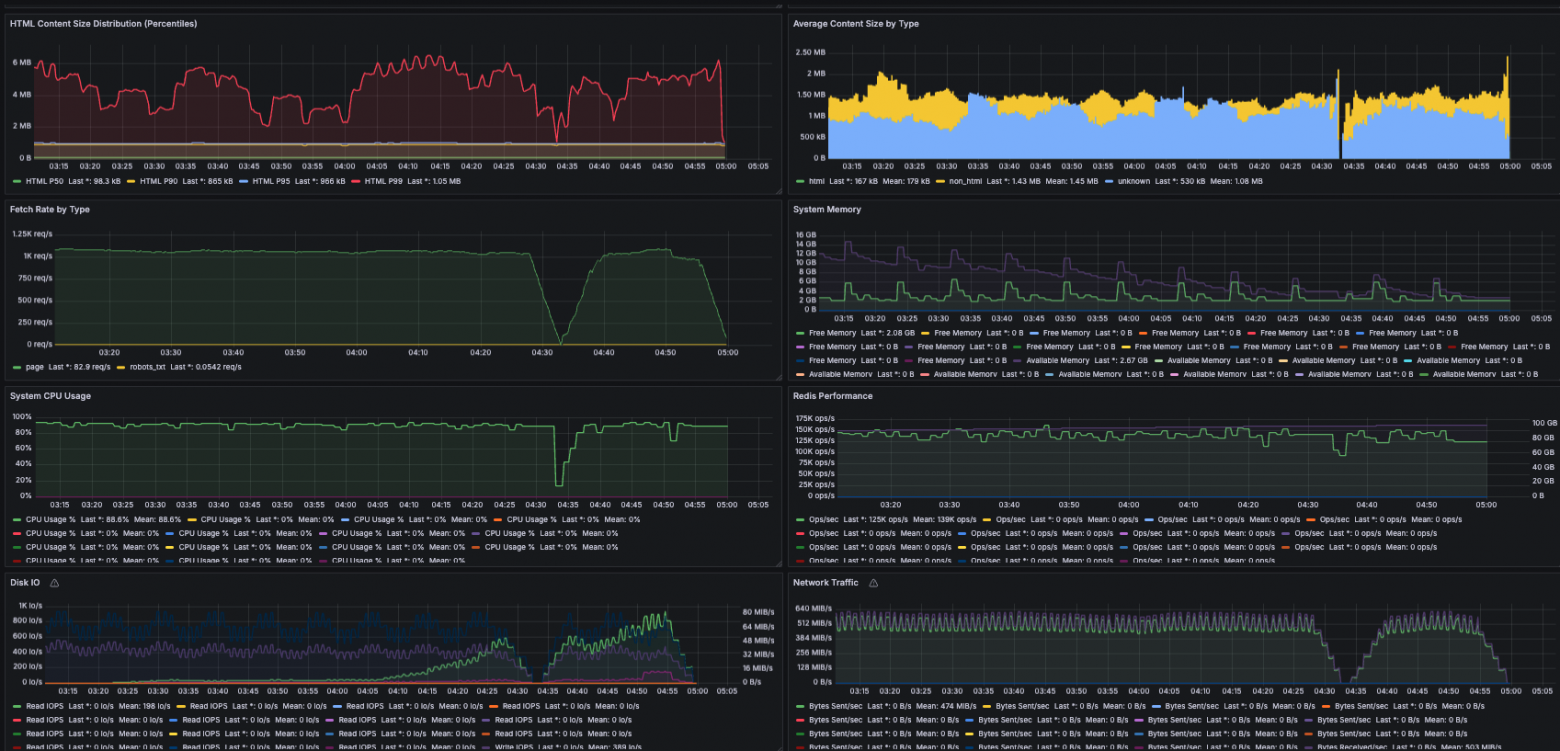
Перед масштабным краулингом на 12 узлах i7i.4xlarge самым большим моим экспериментом стал многочасовой прогон на одном узле i7i.2xlarge, поэтому при резком скачке масштабов возникло довольно много неожиданностей. Всё воскресенье от рассвета до заката (и даже позже) я был «на дежурстве» у моего собственного проекта, наблюдая за метриками и быстро устраняя проблемы. Часть из них заключалась в глупых эксплуатационных оплошностях (например, я забыл организовать ротацию логов и у меня закончилось место в корневом томе), но самой серьёзной проблемой стало разрастание памяти из-за фронтиров.
Она была специфичной для моей архитектуры, в которой все данные фронтиров хранились в памяти. У меня возникали проблемы с памятью и в менее масштабных экспериментах, но в других компонентах, например, в HTTP-клиенте или в записях посещённых страниц. Я вычислил объём памяти, необходимый этим компонентам для миллиарда посещённых страниц, но не предусмотрел, что фронтиры особо «горячих» доменов могут разрастись до десятков гигабайт (сотни миллионов или миллиарды URL), и посередине прогона мои узлы начали дохнуть, как мухи. Мне приходилось вмешиваться вручную и перезапускать зависающие машины, а потом урезать фронтиры. К счастью, благодаря устойчивости к сбоям возобновлять процесс оказалось легко.
Какие домены вызывали эти проблемы? Насколько могу судить, в основном это были просто очень популярные веб-сайты со множеством ссылок. Например, среди них оказались yahoo.com и wikipedia.org. Ещё одним был веб-сайт cosplayfu, который поначалу показался мне странным онлайн-магазином, но после Интернет-поисков выяснилось, что он вполне нормален. Самые проблематичные домены просто вручную добавлялись в список исключений.
Размышления
Теория и практика
Как мой проявился краулер по сравнению с решениями «из учебников», например, с анализом HelloInterview Эвана Кинга? Здесь, вероятно, интересна приблизительная метрика Кинга: 5 машин могут выполнить краулинг 10 миллиардов страниц за 5 дней. В его предложении машины занимаются исключительно загрузкой, а парсеры и хранилище фронтиров находится в другом месте. Нет никаких подробностей про оборудование машин, только пропускная способность сети в 400 Гбит/с на машину, из чего мы можем вычислить использование на 30%.
По крайней мере, расчёт процента использования приблизительно верен; у моих узлов было всего 25 Гбит, но я действительно получил примерно 32% использования (8 Гбит/с на ввод и вывод) в установившемся режиме работы. Тем не менее, загрузкой занимались только 9/16 ядер каждой машины, то есть при наивном масштабировании я должен был достичь использования сети на 53%. Аналогично, поскольку я использовал 12 машин для краулинга 1 миллиарда страниц примерно за одни сутки, мне, вероятно, удалось бы достичь того же миллиарда за день с 6,75 машины, занимающихся исключительно загрузкой. Если предположить ещё и прямолинейное масштабирование с i7i.4xlarge до i7i.8xlarge, это подразумевает, что 6,75 машины удвоенного размера, применяемых исключительно для загрузки смогли бы выполнить краулинг 10 миллиардов страниц за 5 дней. То есть оценка Кинга достаточно точна, но могла бы потребовать больше оптимизации, чем в моей системе!
Что дальше?
Откровенно говоря, я удивлён доле веба, доступной6 без выполнения JS. И это здорово! Благодаря этому краулингу я узнал об интересных веб-сайтах, например, о ancientfaces.com. Но я заметил, что даже на многих доступных для краулинга веб-сайтах наподобие GitHub скачиваемые страницы не содержат значимого текстового контента с разметкой; весь он встроен в огромные строки, которые, предположительно, должны рендериться на стороне клиента чем-то наподобие «легковесных» скриптов на JS. Думаю, в будущем любопытно было бы изучить этот вопрос: как будет выглядеть крупномасштабный краулинг, когда нам действительно нужно рендерить страницы динамически? Подозреваю, что при тех же масштабах это окажется гораздо дороже.
Ещё один вопрос: какую форму и распределение имеет миллиард страниц, которые я скраулил? я сохранил эту выборку, но у меня не было времени заняться аналитикой. Было бы любопытно узнать базовую информацию о метаданных, например, соотношение живых и мёртвых скрауленных URL, HTML-контента и мультимедиа и так далее.
В этом посте частично раскрыты масштабные изменения, произошедшие с вебом за последний десяток лет, но ситуация продолжает меняться. Агрессивный краулинг/скрейпинг при помощи огромных ресурсов не стал чем-то новым (вспомним скандал с Facebook и скрейпингом OpenGraph), но сегодня он активировался из-за ИИ. Я очень серьёзно отнёсся к вежливости, соблюдая договорённости наподобие robots.txt, но многие краулеры этого не делают, и Интернет начинает вырабатывать меры защиты от подобного. Экспериментальная фича Cloudflare pay-per-crawl — новое предложение на рынке, и оно может в этом сильно помочь.
Благодарности
Спасибо Майклу Нильсену и Джейми Кэллену за их предыдущие проекты, вдохновившие меня, и за обсуждение по электронной почте; спасибо Сойеру Худу и Джонатану Чену за полезные отзывы о посте.
Примечания
-
Я обсудил с Майклом Нильсеном предыдущий прецедент и тоже решил не публиковать код. Простите!
-
Например, задержка между обращениями к домену, чтобы избежать его DDOS.
-
Если загрузка успешно получала текстовое содержимое.
-
Например, некорректные сообщения о том, что URL уже был встречен, хотя на самом деле это не так.
-
Это не соответствует «медианному весу страницы» в 18 КБ, заявленному в Web Almanac за 2024 год, но, вероятно, это связано с доменами, которые я краулил; список был ограничен примерно миллионом самых популярных доменов из комбинации датасетов Cisco и Cloudflare datasets.
-
В смысле, что они доступны через якорные тэги, а не в отношении UX.
Ссылки
-
How to crawl a quarter billion webpages in 40 hours, Nielsen, M., 2012.
-
Scrapy, scrapy, ., 2015.
-
Frontera, scrapinghub, 2015.
-
The Sapphire Web Crawler, Callan, J., 2009.










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое