OpenRouter выкатили огромное исследование: как реально используют LLM (анализ 100 трлн токенов)
В исследовании изучили 100 трлн токенов живого трафика через OpenRouter (300+ моделей, 60+ провайдеров, миллионы пользователей, до ноября 2025 года).
Ключевые выводы ?
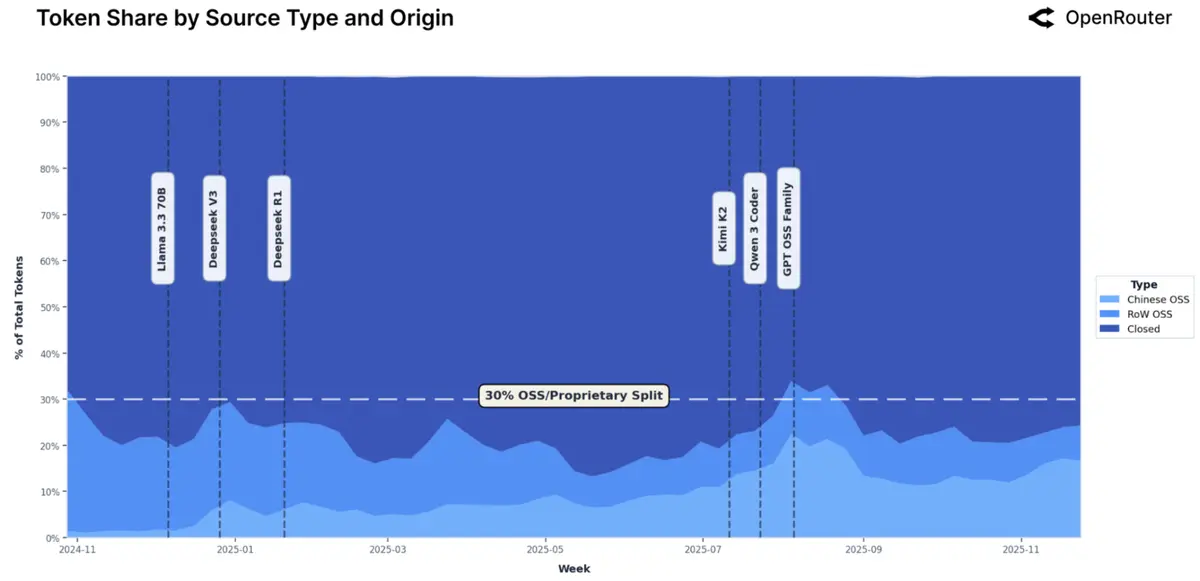
Open source закрепился на ~30% и привёл с собой Китай.
Открытые модели стабильно держат около трети токенов. Особенно выросли китайские OSS (DeepSeek, Qwen, Kimi): с ~1–2% до до 30% трафика в отдельные недели, в среднем ~13%.
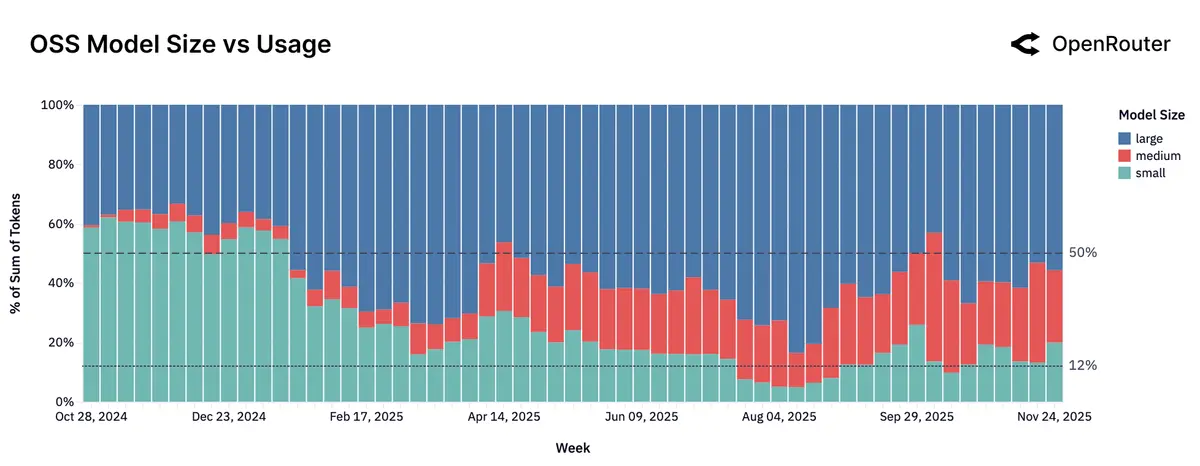
"Medium is the new small": рынок смещается к 15–70B.
Маленьких моделей много, но их доля в использовании падает. Реальный рост — в medium-классе (15–70B): Qwen2.5 Coder 32B, Mistral Small 3, GPT-OSS 20B.
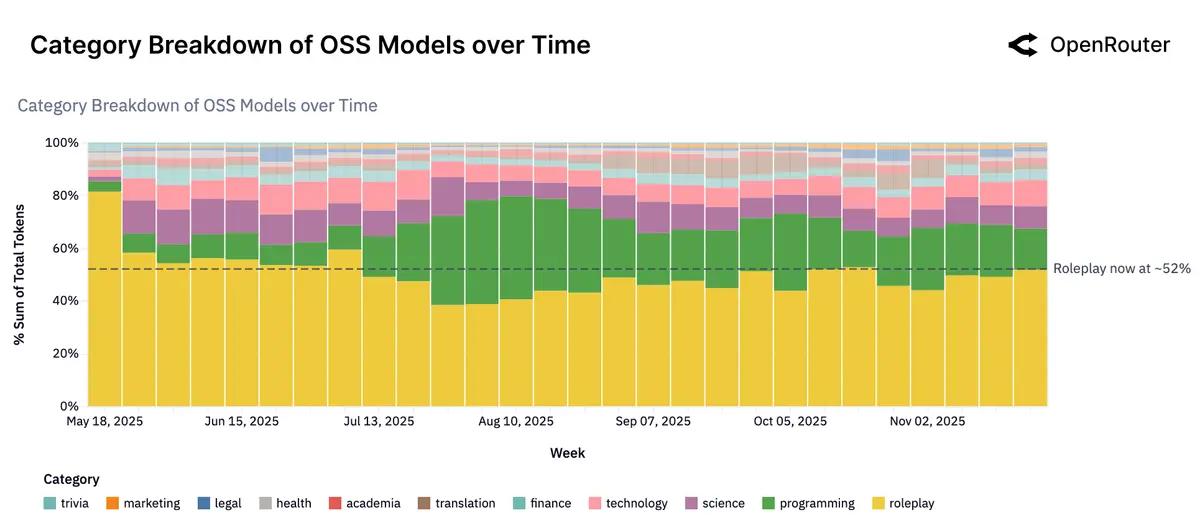
Главные use-cases для OSS: roleplay и кодинг.
У открытых моделей: Roleplay ≈ 50%+ токенов: игровые сценарии, персонажи, фанфик-миры, «длинные» диалоги. Programming — второй по величине сегмент. Китайские OSS сдвинуты ещё сильнее в практику: у них roleplay уже не доминирует, а кодинг + технологии = ~39% нагрузки.
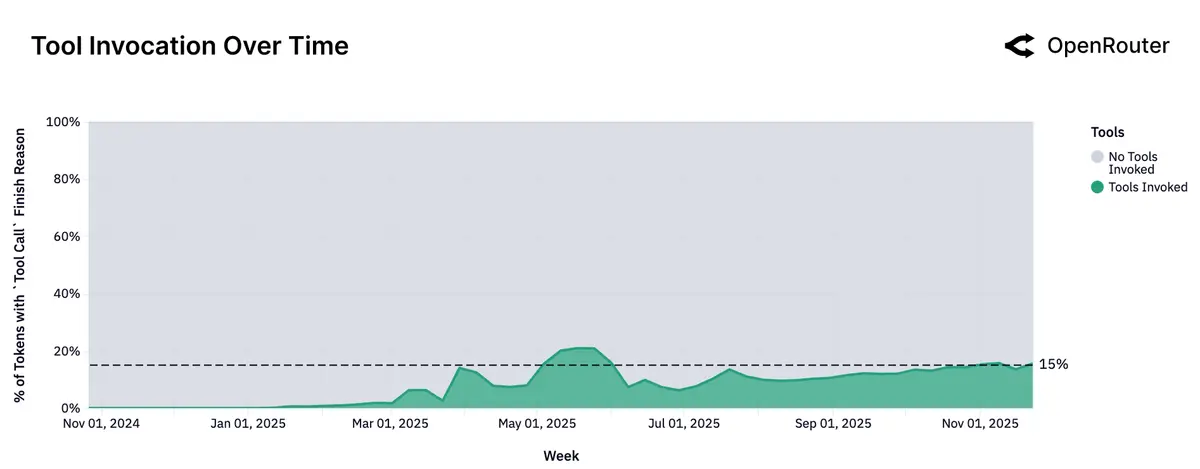
Agentic inference стал нормой, а не экспериментом.
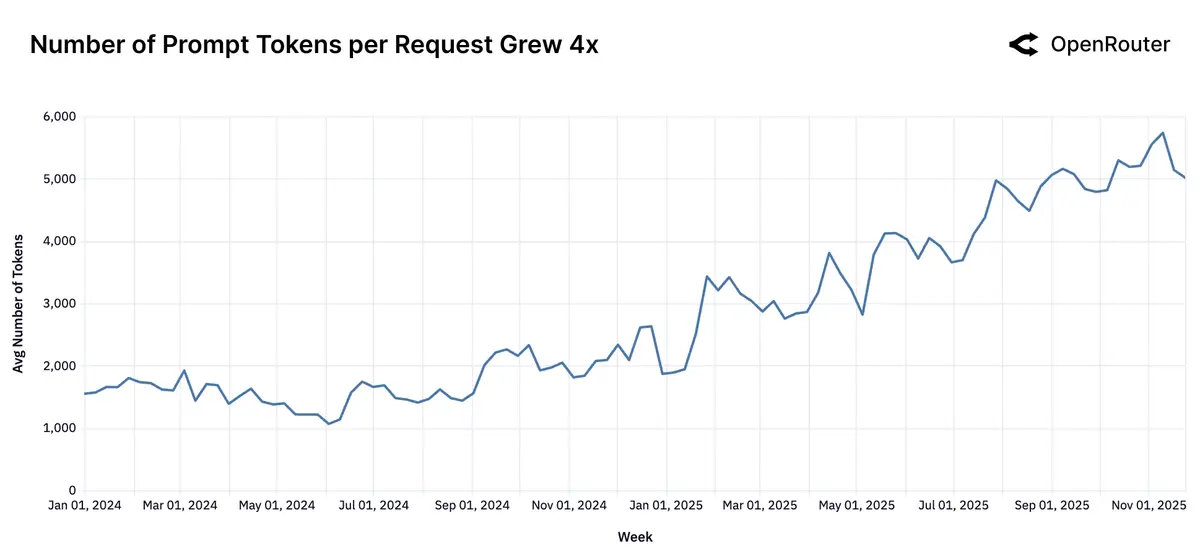
Reasoning-модели обслуживают уже >50% всех токенов. Растёт доля запросов с tool-calling, появляются модели заточенные «под агентность». Средний запрос стал длинным: prompt вырос ~с 1.5K до >6K токенов, completion почти утроился.
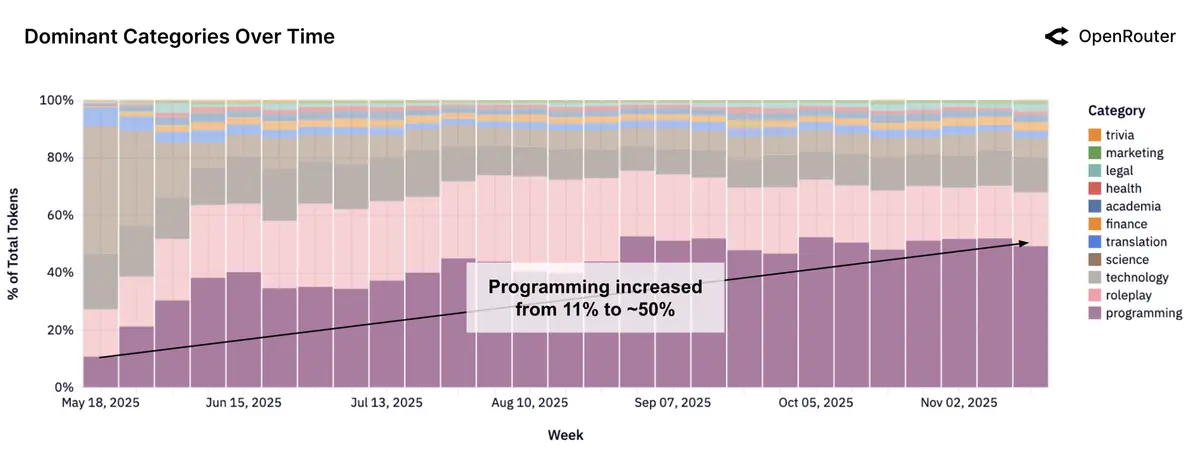
Программирование стало "killer-категорией": 11% → >50% токенов.
В начале 2025 года программирование ≈ 11%, в последние недели — уже больше половины трафика. Лидирует Claude: стабильно >60%. OpenAI вырос с ~2% до ~8%, Google удерживает ~15%. OSS (Qwen, Mistral, DeepSeek и др.) активно захватывают mid-tier, MiniMax растёт особенно быстро.
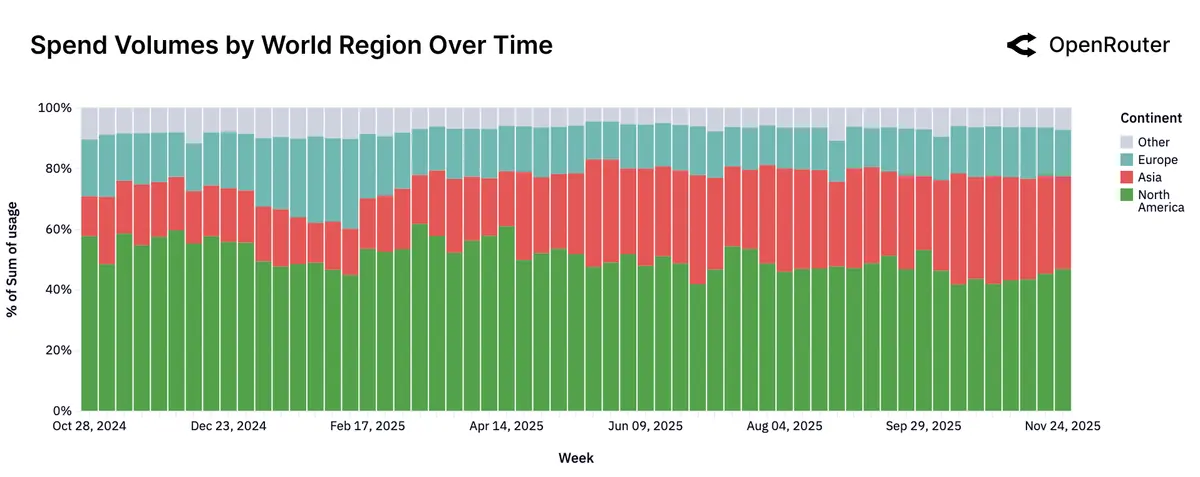
География: Азия резко догоняет, язык почти полностью английский.
По континентам (share по токенам): Северная Америка: 47%, Азия: ~29% (было ~13%, стало ~31% в неделях под конец), Европа: ~21%. По языкам: английский ≈ 83%, далее упоминаются китайский, русский, испанский.
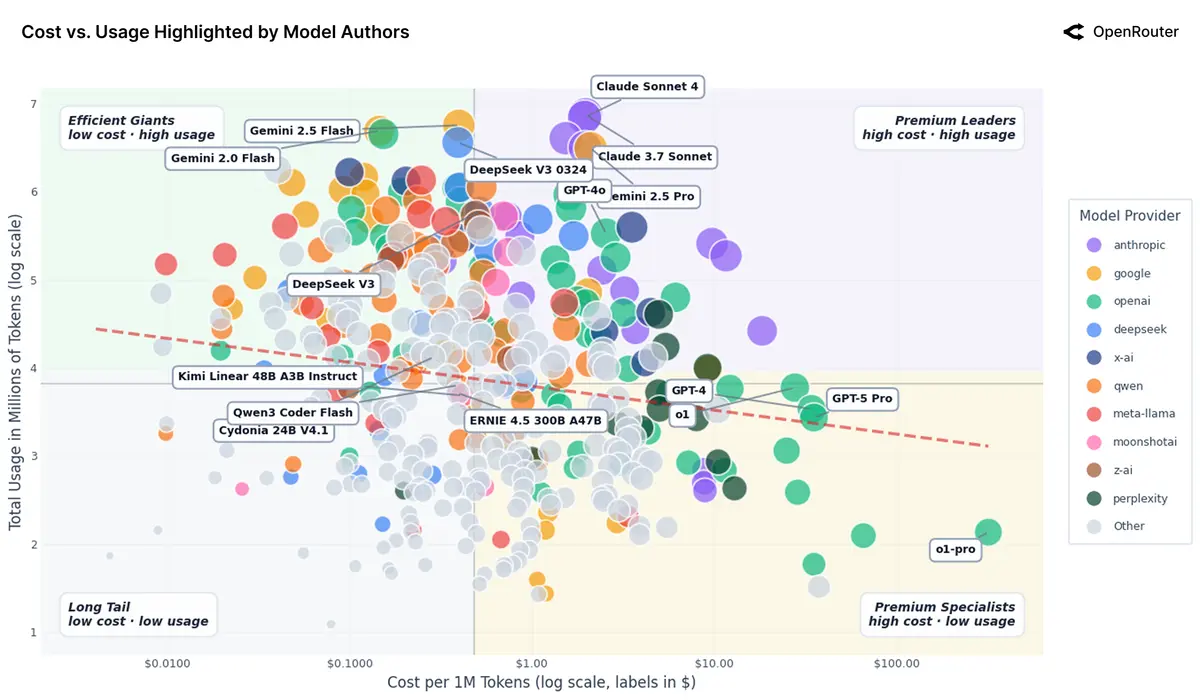
Рынок почти не чувствителен к цене.
Дорогие модели вроде Claude Sonnet стоят около $2 за 1M токенов и всё равно получают огромные объёмы, дешёвые «рабочие лошадки» вроде Gemini Flash и DeepSeek V3 стоят меньше $0.4 и загружаются сопоставимо, ультрадорогие GPT-4/5 Pro по $30–35 используются для узких задач, а сверхдешёвые OSS-модели за $0.03–0.05 остаются нишевыми. Цена сама по себе не решает: критичны качество, стабильность и интеграции.
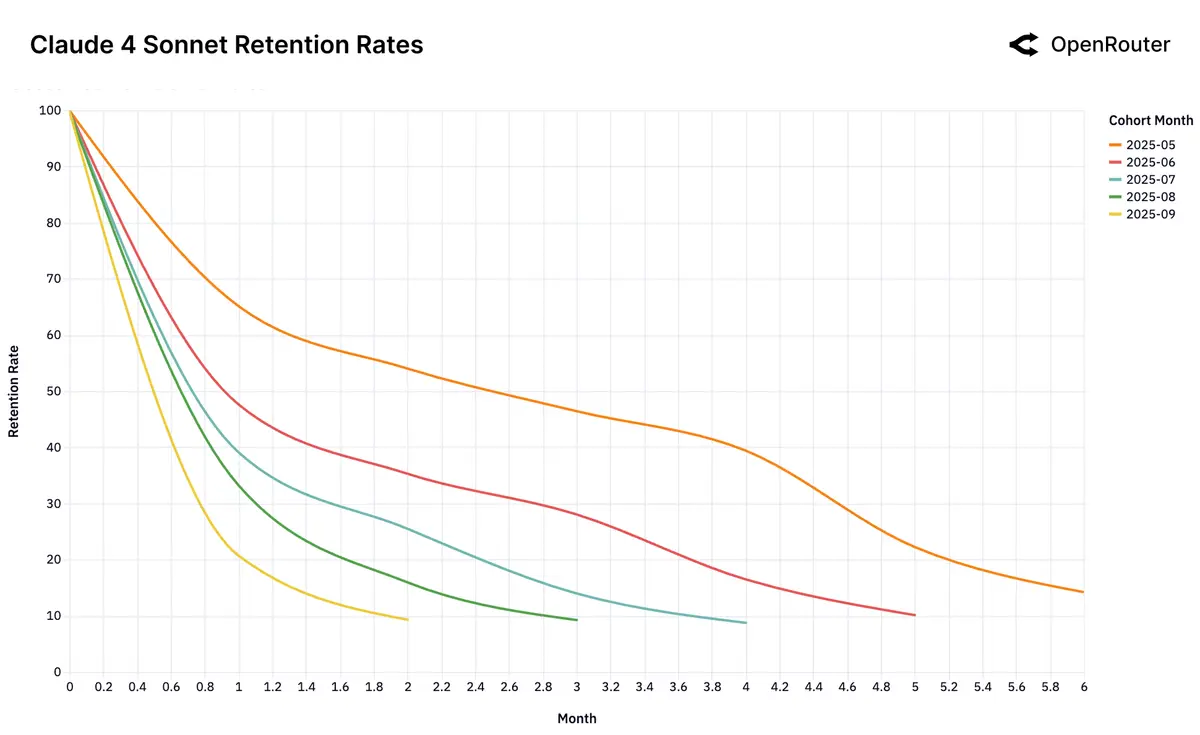
"Glass Slipper": когда модель идеально попадает в задачу, её уже не меняют. У frontier-моделей есть короткий момент, когда они впервые закрывают болезненный workload и формируют «фундаментальную» когорту, которая остаётся надолго. Так случилось у Claude 4 Sonnet и Gemini 2.5 Pro с retention около 40% на 5-й месяц. У моделей без такого момента (например, Gemini 2.0 Flash или Llama 4 Maverick) устойчивых когорт не возникает. У DeepSeek заметен «бумеранг»: пользователи пробуют альтернативы и возвращаются, подтверждая, что именно он лучше решает их задачу.
Русскоязычное сообщество про AI в разработке

Друзья! Эту новость подготовила команда ТГК «AI for Devs» — канала, где мы рассказываем про AI-ассистентов, плагины для IDE, делимся практическими кейсами и свежими новостями из мира ИИ. Подписывайтесь, чтобы быть в курсе и ничего не упустить!










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое