Готовимся к System Design интервью с помощью ИИ и немного про Enterprise Integration Patterns
Некоторое время назад я с позором провалил собеседование на системного архитектора в один банк. Интервьюер просто до глубины души был оскорблен мои низким техническим уровнем. Ему максимально не понравилась схема интеграции со СМЭВ, которую я пытался изобразить. В итоге я решил немного подтянуть теорию, почитать учебники, попроходить Mock‑собеседования... Да, ну, нет, всё это слишком сложно! Вместо этого я решил запилить инструмент моделирования, добавить в него Enterprise Integration Patterns и прикрутить ИИ, чтобы он сам рисовал все эти дурацкие модели.
Затем я давал Gemini 3 Pro тестовые задания на проектирование архитектуры. В процессе я возможно и сам немного подтянул свои знания. Результат вы можете увидеть в статье, возможно эти модели будут для вас полезны. Вручную я их практически не правил, только иногда задавал уточняющие вопросы. Со мной всё итак ясно, а как вы считаете прошла бы Gemini собеседование на архитектора? На сколько удачно она справилась с этими тестовыми заданиями? Возможно на ваших собеседованиях задачи были сложнее и интереснее?

Постепенная миграция на микросервисы
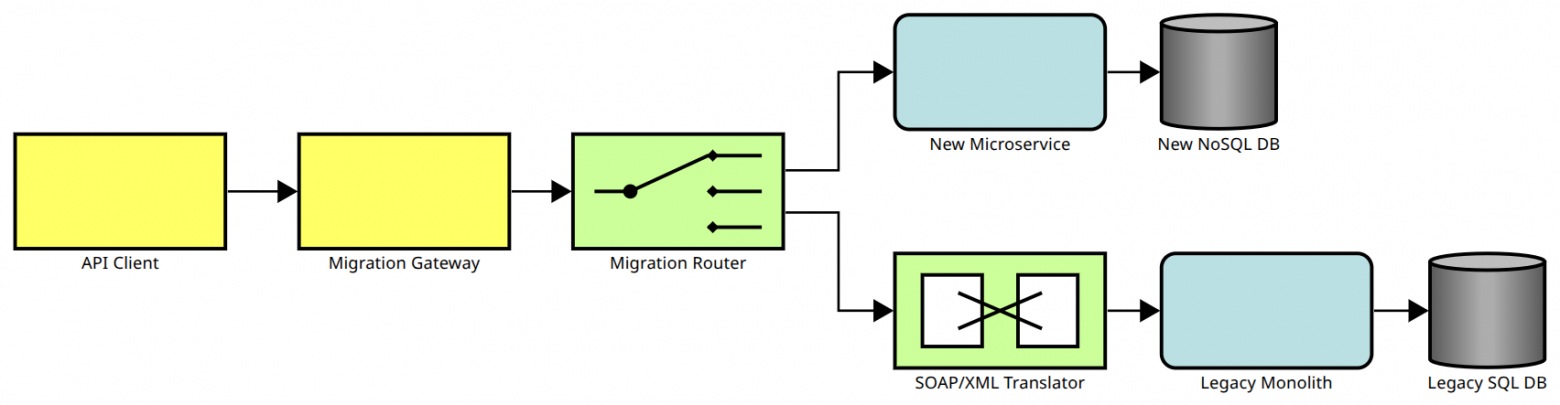
Начнём с классического примера из 2010 года. Допустим у вас есть монолитное приложение, которое ещё и работает по SOAP протоколу с XML сообщениями, а вам хочется микросервисы и JSON. Как можно было бы описать новую архитектуру вашего приложения?
В этом случае вы можете не сразу переписывать всё приложение, а для начала вынести только небольшой фрагмент функциональности. И добавить маршрутизатор, который часть запросов будет отправлять в новый микросервис, а остальные запросы будет преобразовывать в XML и отправлять в монолит:
Чат-бот на основе RAG
Перейдем от хайповой задачки из 2010 года к хайповой задачке из 2024 года. Вам нужно запилить чат‑бота, основанного на Retrieval Augmented Generation (RAG).
Получаем такую архитектуру:
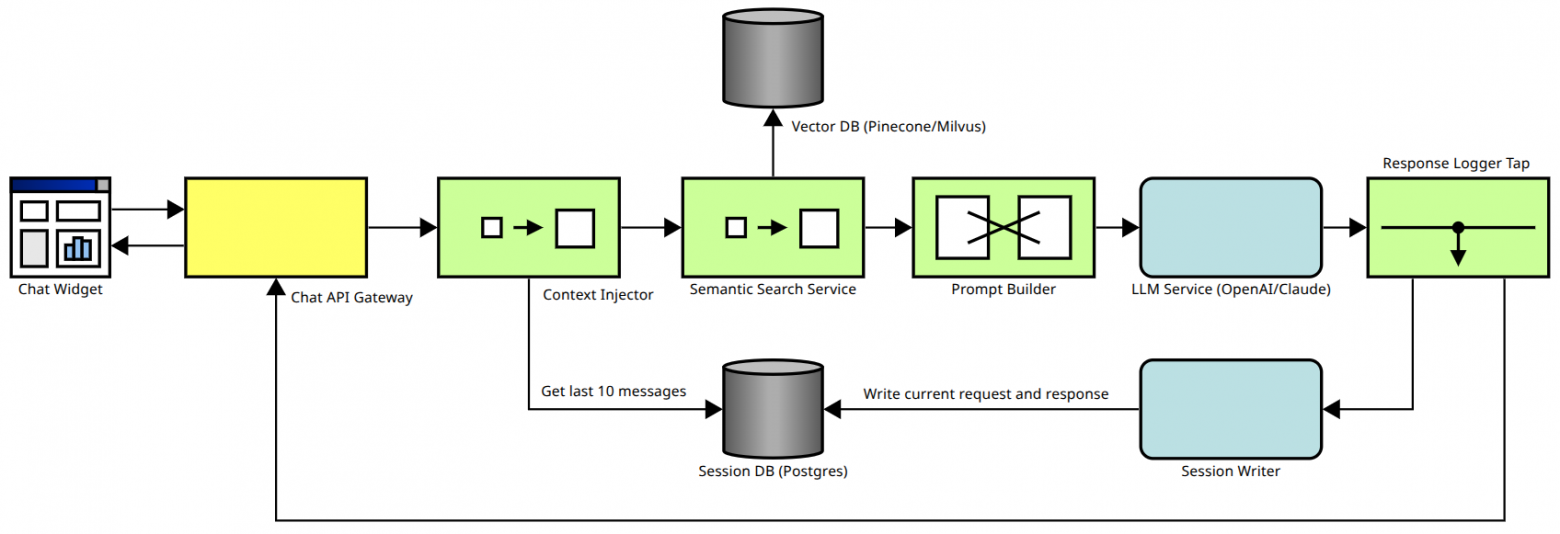
Пользователь в чате пишет запрос, который отправляется в API Gateway. Есть база данных, в которой хранится история запросов и ответов. Достаём из этой базы последние 10 записей, будем использовать их в качестве дополнительного контекста. Затем ищем в векторной базе данных подходящие документы и добавляем их в контекст. Наконец формируем итоговый промпт и отправляем его в языковую модель. Результат показываем пользователю и сохраняем в базу, чтобы использовать его в качестве контекста в последующих запросах.
Рассылка уведомлений
Предположим у вас есть приложение, которое формирует различные уведомления для пользователей, например, об успешно доставленном заказе. Вам необходимо спроектировать систему рассылки этих уведомлений.
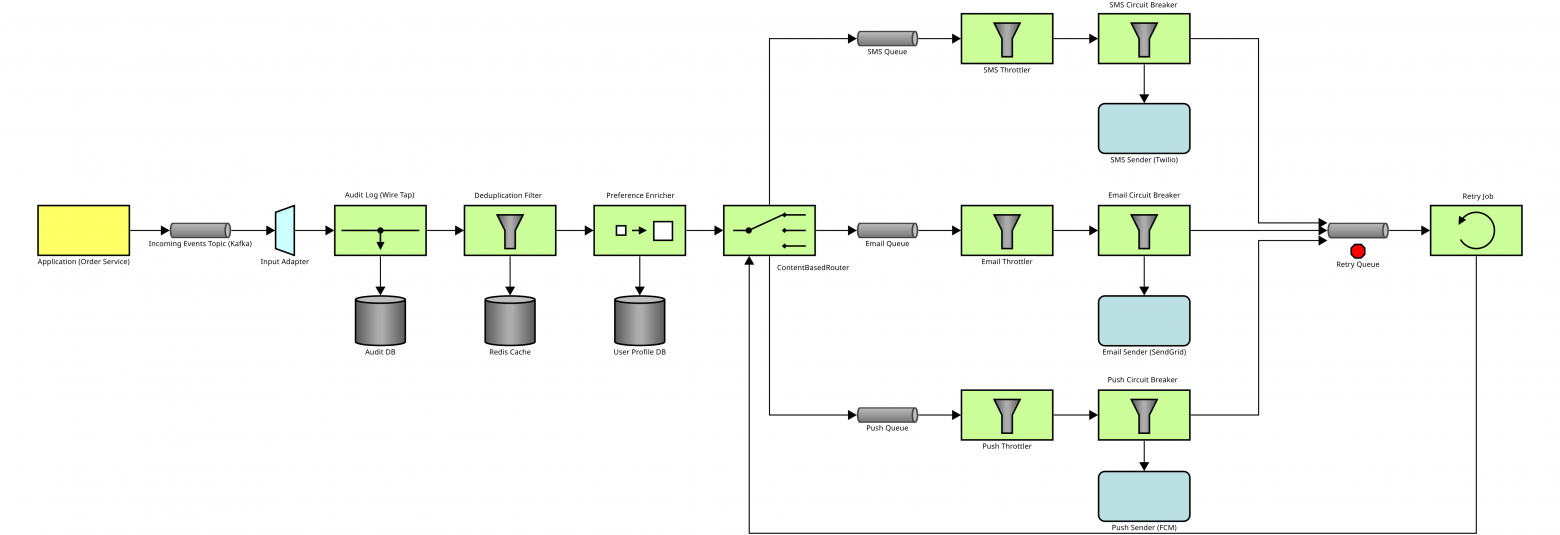
Приложение складывает все уведомления в очередь. Затем они извлекаются из очереди, при этом делается запись в журнал. На случай если уведомления могут дублироваться сохраняем в Redis историю рассылки за последние несколько минут и отбрасываем уведомления, которые уже только что отправлялись. Заглядываем в профиль адресата. В зависимости от предпочитаемых им способов доставки отправляем SMS, email или push‑уведомление.
Чтобы нас не забанили за спам реализуем тротлинг. Тут я долго спорил с ИИ, потому что в моём понимании тротлинг отбрасывает часть сообщений, но в итоге Gemini убедила меня, что это не обязательно. Затем отправляем уведомления через соответствующие сервисы. В случае неудачи помещаем их в очередь для повторной отправки.
Обработка заказов на маркетплейсе
Предположим вы оформили заказ на маркетплейсе и ждёте его доставку. Часть товаров из заказа может быть на складе маркетплейса и тогда заявка на доставку отправляется через внутреннюю систему. Часть товаров может быть на сторонних складах и тогда необходимо отправить заявку им. Часть товаров может быть вообще электронной и доставляться на email сразу. Архитектура такого решения может быть описана следующим образом:
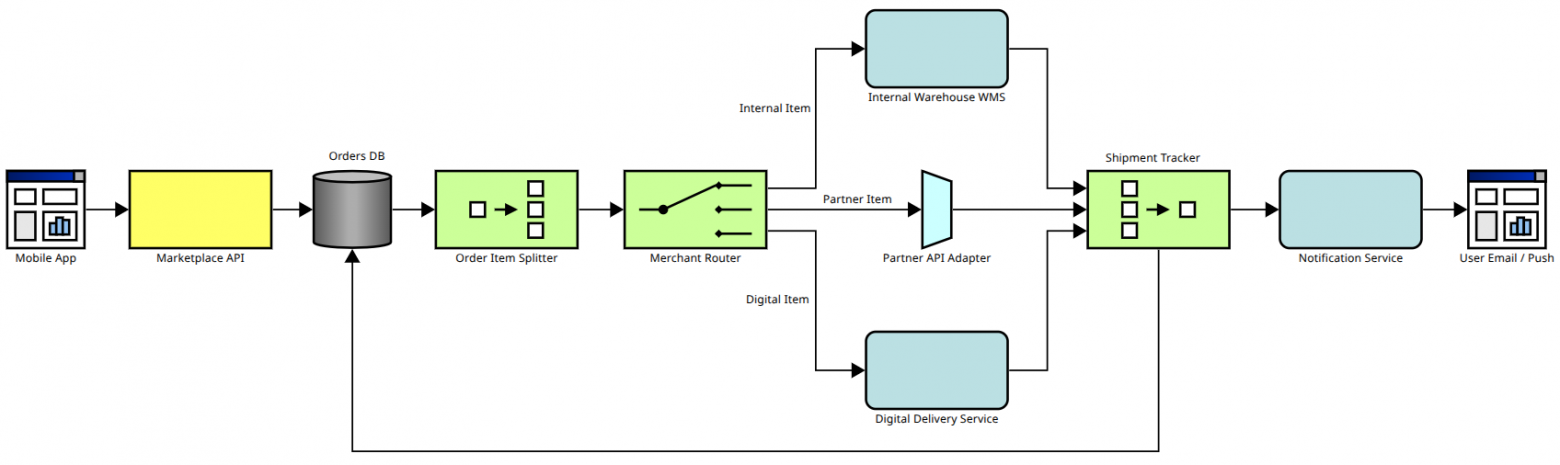
Заказ сначала попадает в базу данных. Затем для каждого товара формируются отдельные заявки. Когда все товары собраны и отправлены, то об этом делается запись в базе данных, а также отправляется уведомление пользователю, возможно через систему которую мы спроектировали выше.
Поиск авиабилетов
Немного усложним задачу. Предположим вы устроились в потенциально очень успешный стартап, который будет искать дешевые авиабилеты. Прежде чем приступать к разработке необходимо описать архитектуру этого решения:

Пользователь указывает параметры перелета, отправляется API запрос. Чтобы порадовать людей быстрыми ответами и снизить нагрузку на сервер сначала посмотрим в кеше не искал ли кто‑то недавно аналогичные билеты. Если нет, то сначала провалидируем запрос, например, проверим, что даты полёта в будущем. Затем преобразуем названия городов в IATA‑коды. Разошлём поисковые запросы по разным авиакомпаниям и агрегаторам. Если от некоторых компаний ответ будет идти слишком долго, то отменим эти запросы.
Объединим результаты поиска. Удалим дублирующиеся билеты на случай если они пришли от разных компаний. Отсортируем билеты по стоимости. Обновим кэш. Превратим результат в удобный JSON и вернем на фронтенд.
Покупка авиабилета
Теперь спроектируем систему бронирования билетов:
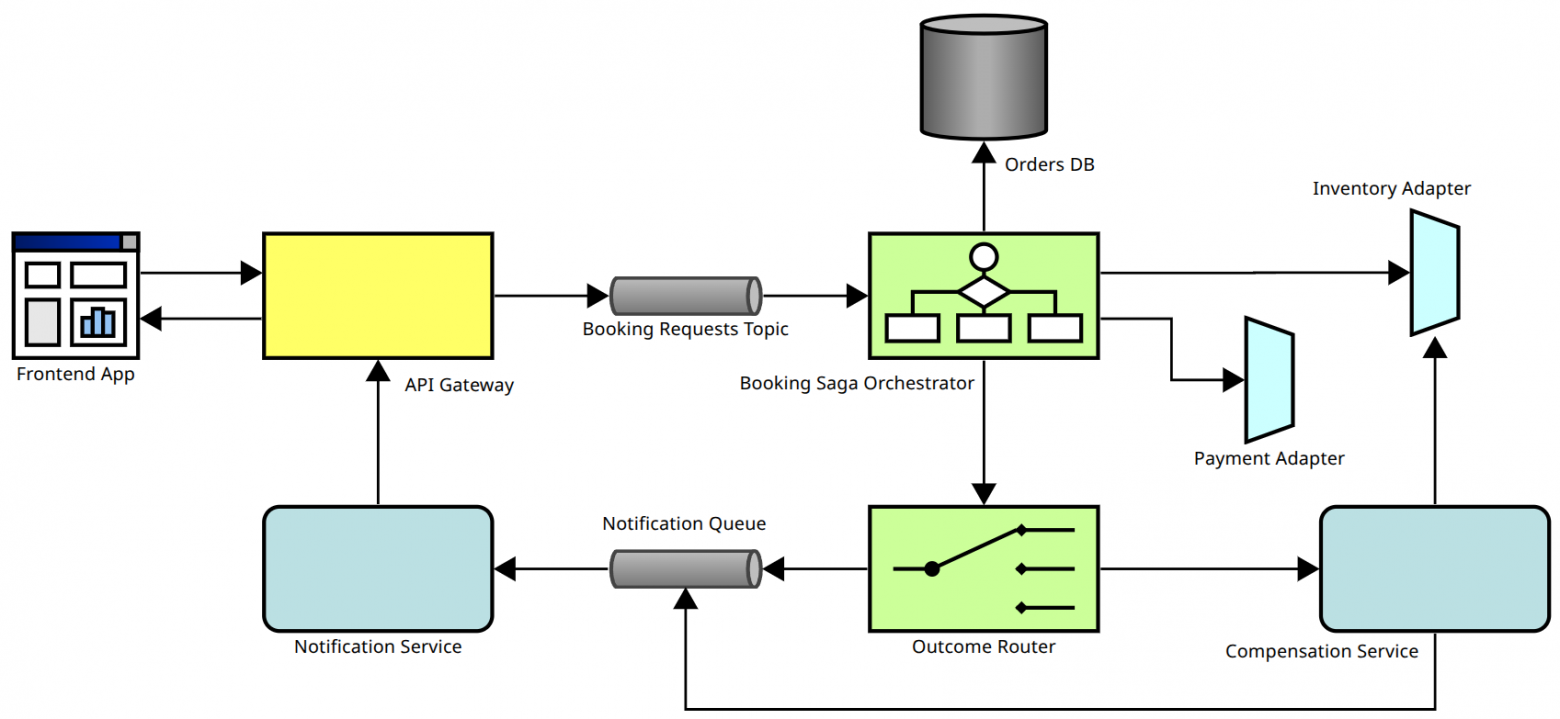
При реализации такой системы могут возникать различные сложности. Например, могут быть пиковые нагрузки перед Новым годом или в период отпусков. Чтобы система справлялась с ними будем сначала отправлять все заявки в очередь, а затем по мере возможности обрабатывать.
Следующая сложность в том, что бронирование и оплата билетов обычно выполняются через два разных сервиса. Если оплата не прошла, то необходимо отменить бронь. В этом нам поможет Saga‑оркестратор.
Также на случай сбоев или перезагрузки сервера важно сохранять заявки в базе данных.
Меня немного смущает в этой схеме, что уведомления об успешном бронировании и уведомления об отмене брони отправляются в одну и ту же очередь. И Gemini согласилась с тем, что очереди лучше разделить. Это не то, чтобы большая проблема в архитектуре, но оставлю это как пример того, что нужно критически относиться к тому, что генерирует ИИ.
Мониторинг здоровья
Попробуем спроектировать что‑нибудь более интересное. Люди носят множество разных устройств для мониторинга здоровья (часы, браслеты, кольца). Необходимо спроектировать систему, которая будет собирать и обрабатывать эти данные:
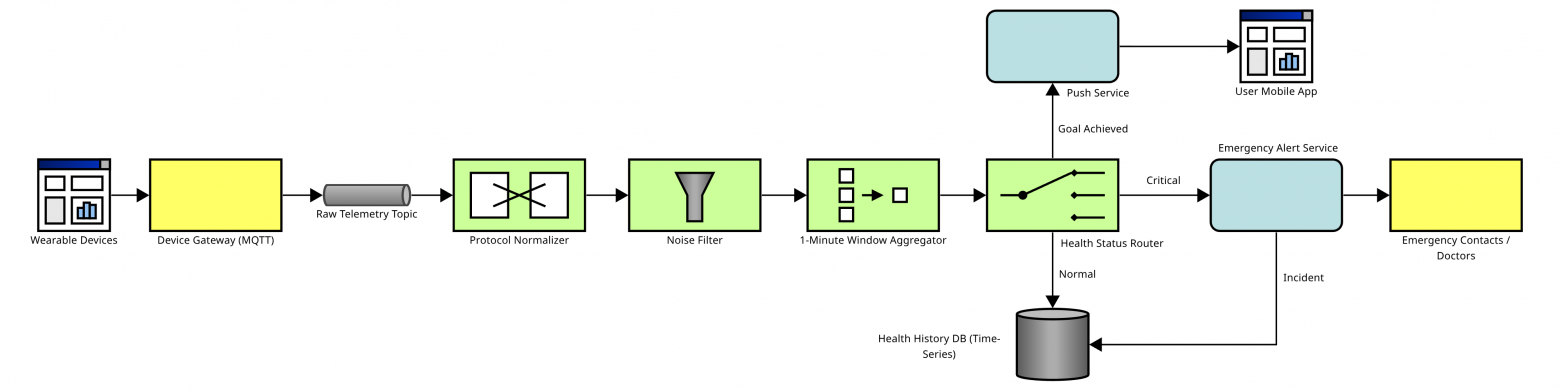
С носимых устройств по протоколу MQTT данные отправляются в шлюз и в сыром виде складываются в очередь. Это позволяет шлюзу быстро отвечать на запросы устройств, не дожидаясь обработки данных.
Затем данные приводятся к единому формату. Очищаются от шума. Агрегируются, потому что нет смысла хранить значения за каждую секунду. Анализируются и в зависимости от результата возможны различные действия. Если показатели в норме, то просто сохраняем их в базу данных, чтобы потом строить красивые графики. Если пользователь достиг своих ежедневных целей, например, прошел 10 тысяч шагов, то отправляем ему уведомление. Если значения показателей критические, то уведомляем экстренные службы и делаем запись в базу.
Обработка видео
Ну, и ещё одна тестовая задачка на проектирование хостинга для видео с котиками:
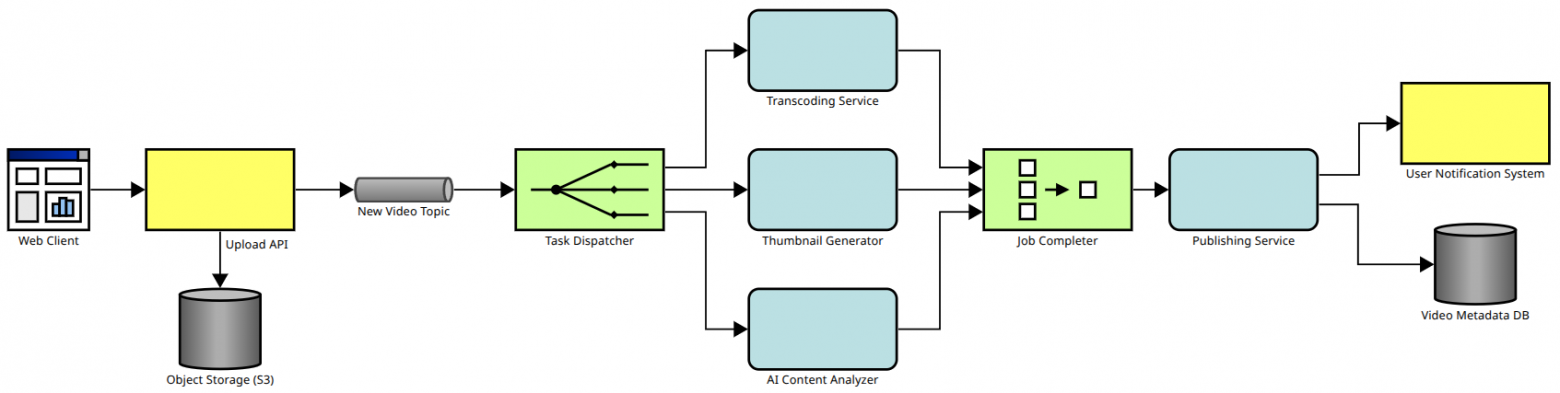
Пользователь загружает видео. Скорее всего, оно достаточно объёмное, поэтому складывается не в очередь и не в реляционную базу данных, а в объектное хранилище. В очередь на обработку видео добавляется только ссылка на файл. Затем параллельно запускаются перекодирование видео, создание картинки для превью и анализ содержимого. После завершения всех задач видео публикуется. При этом пользователю отправляется уведомление, а в базу данных сохраняются метаданные видео.
Как самим попробовать генерировать модели
Запускаете любой MCP‑клиент с поддержкой OAuth 2.0, например, VS Code, Windsurf, Cursor. В ChatGPT недавно появилась возможность подключаться к MCP‑серверам, но она как‑то частично работает.
Если у вас VS Code, то открываете настройки MCP‑серверов. Для этого можно нажать Ctrl+Shift+P и выбирать в списке «MCP: Open User Configuration».
Откроется файл mcp.json, в который можно добавить такие настройки:
{
"servers": {
"Architeezy": {
"url": "https://architeezy.com/mcp",
"type": "http"
}
}
}
Затем можно открыть чат и список MCP‑серверов:
Подключиться к серверу:
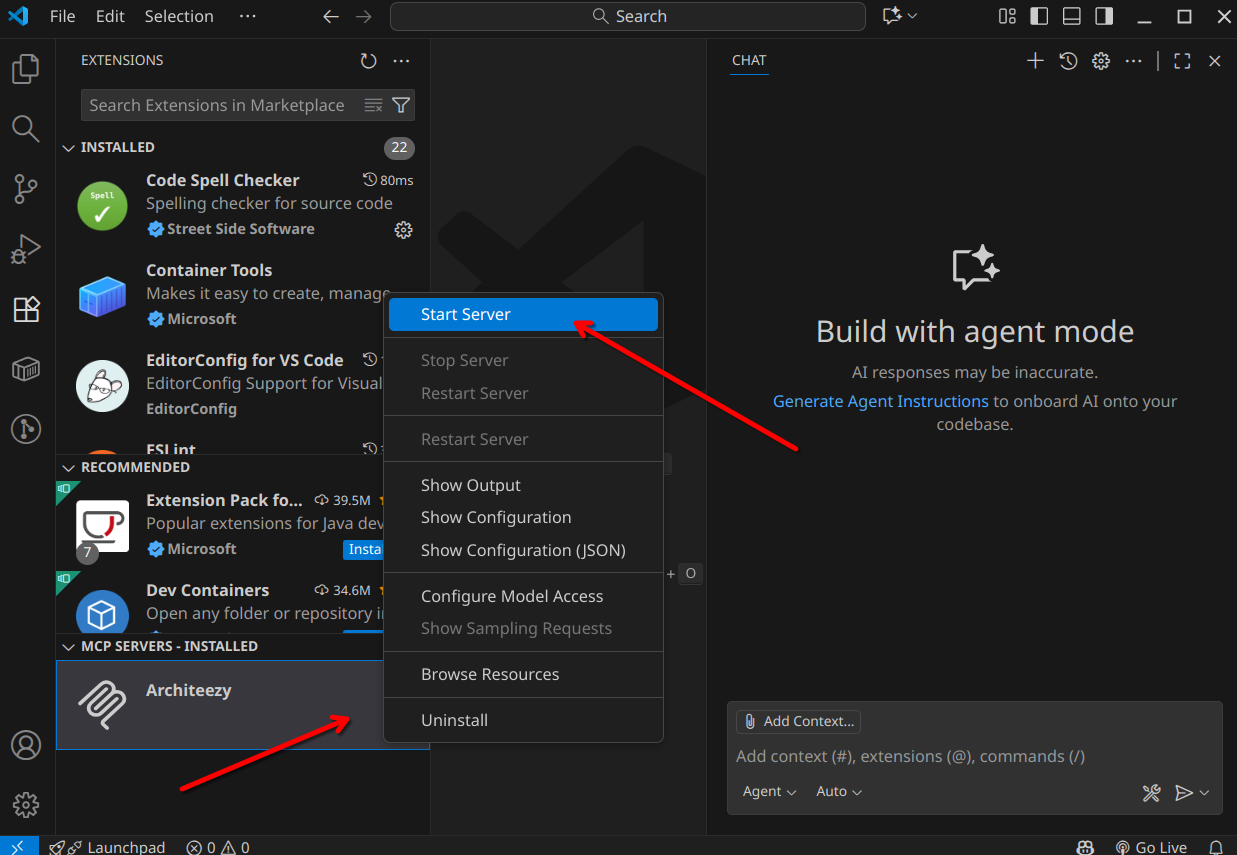
После успешной аутентификации можно убедиться, что найдены MCP инструменты для работы с моделями:
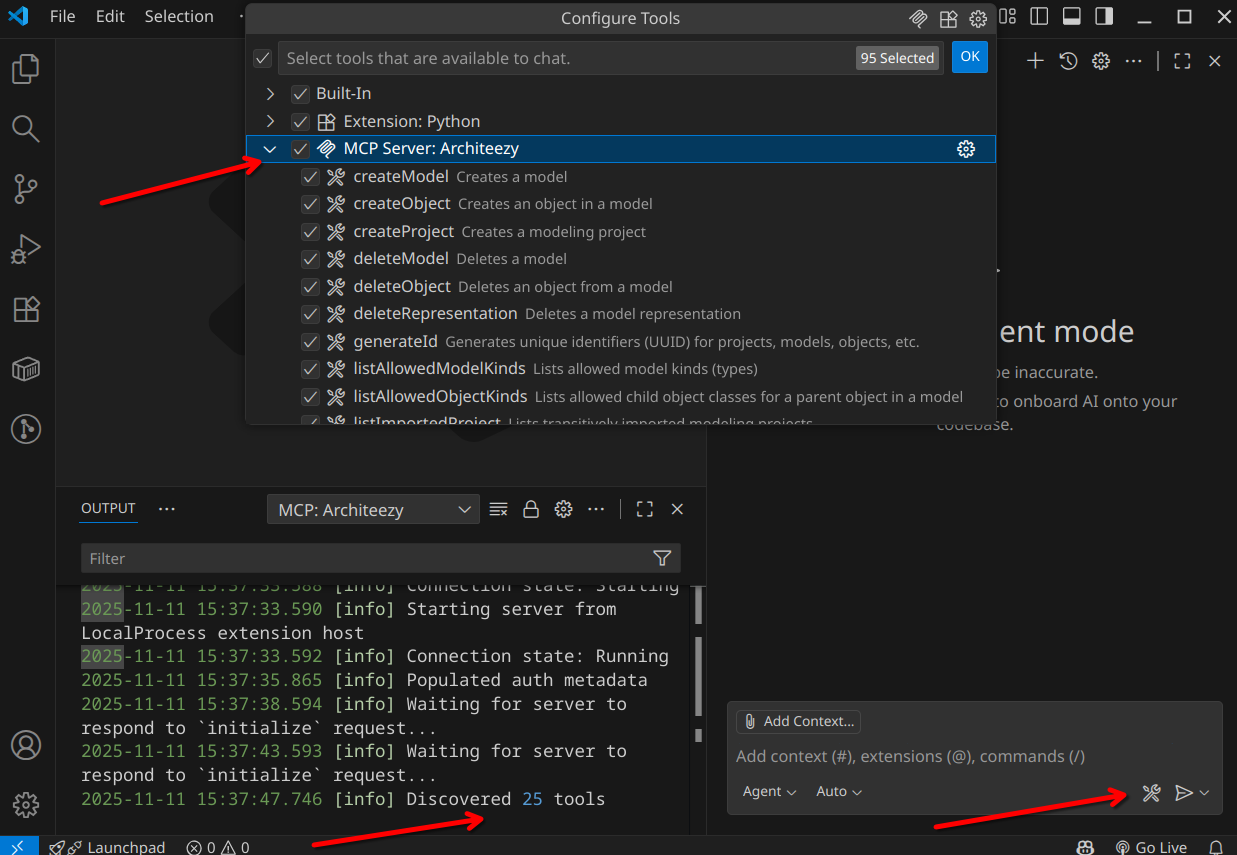
Нужно убедиться, что чат переключен в режим агента, чтобы он мог запускать MCP‑инструменты. Можно писать в чате запросы типа «Создай в Architeezy проект Mars Colonization, создай в нём Enterprise Integration модель, описывающую взаимодействие подсистем в Starship. Расположи фигуры на диаграмме оптимальным образом».
По моим ощущениям в VS Code языковые модели почему‑то слабые и медленные, плюс с сильными ограничениями на количество токенов. Как вариант, вы можете открыть ChatGPT, Google AI Studio или любой другой клиент без поддержки MCP, писать там запросы типа «Опиши Enterprise Integration Patterns модель для взаимодействия подсистем в Starship. Напиши инструкцию для ИИ по созданию такой модели». Затем можно скопировать эту инструкцию уже в VS Code. Собственно я так и генерировал все эти модели. Если раньше было Ctrl+C, Ctrl+V со Stackoverflow, то сейчас Ctrl+C, Ctrl+V между ИИ чатами :)
Заключение
Что вы думаете по поводу всего этого? На сколько адекватные получились модели? Используете ли вы Enterprise Integration Patterns? Возможно у вас есть примеры задач на моделирование, с которыми ИИ точно не справится? Что вы обычно моделируете? Как вам вообще такая идея подготовки к собеседованиям по System Design через генерацию моделей? Стоит ли использовать такие модели в реальной работе?










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое