Как я научил AI анализировать AI: observability для LLM-агентов с Langfuse
Пролог: Чёрный ящик современных AI-агентов
Вы когда-нибудь задумывались, что на самом деле происходит внутри AI-ассистента, когда он пишет код за вас? Вот вы даёте промпт в Cursor: "Исправь баг в функции авторизации" — и через 20 секунд получаете правку. Но что было в эти 20 секунд?
Реальность такова: мы не знаем.
Современные AI-агенты — это чёрные ящики. Они читают файлы, выполняют команды, вызывают API, думают (да, у них есть фаза "мышления"), ошибаются и иногда зацикливаются. Но всё это происходит за кулисами. Вы видите только результат: либо работает, либо нет.
Проблема становится критичной когда речь заходит о production. Вы запускаете LLM-приложение, пользователи начинают жаловаться на медленные ответы или странное поведение. Открываете логи — и видите лишь:
[2026-01-20 14:23:45] User query processed. Status: OK
[2026-01-20 14:23:57] Response sent. Tokens: 1234

Отлично. Но почему запрос обрабатывался 12 секунд? Что именно AI делал всё это время? Сколько это стоило? Можно ли было сделать быстрее?
Часть I: Почему это вообще важно?
Экономика LLM-приложений в 2026 году
Давайте говорить откровенно: работа с LLM стоит денег. Много денег.
Реальные цифры:
-
GPT-4: $0.03 за 1K входных токенов, $0.06 за 1K выходных
-
Claude Sonnet 3.5: $0.003/$0.015 за 1K токенов
-
Gemini 2.0 Flash: бесплатно (пока), но с rate limits
Типичный AI-агент в production делает 5-10 вызовов LLM на один запрос пользователя. Если каждый вызов — это 2000 токенов туда и 1000 обратно, вы платите $0.06-0.12 за каждого пользователя. При 10,000 активных пользователей в месяц это $600-1200 только на API.
Но самое интересное — большая часть этих денег тратится впустую.
Три источника неэффективности
1. Избыточный контекст
AI-агенты любят перестраховываться. Вместо того чтобы отправить только релевантный код, они отправляют весь файл. А иногда и несколько файлов. "На всякий случай".
Без observability невозможно понять сколько именно контекста используется и насколько он релевантен.
2. Логические циклы
AI-агент пытается исправить баг, но его правка создаёт новую ошибку. Он пытается исправить её, но создаёт третью ошибку. И так по кругу.
Без observability вы видите только результат: "Задача не выполнена после 5 попыток". Но не видите, что агент 3 раза правил один и тот же файл в одном и том же месте.
3. Медленные операции
Агент выполняет команду которая отвечает 8 секунд. Потом ещё раз. Потом третий раз. Итого: 24 секунды из 30 секунд общего времени ушло на ожидание.
Без трейсинга вы не узнаете об этом никогда.
Почему мы не понимаем как работают агенты?
Тут нужно признать неудобную правду: современные AI-агенты слишком сложны для полного понимания.
Когда вы пишете обычный код, вы знаете что он делает. Функция calculateTotal(items) складывает цены. Класс UserRepository работает с базой данных. Всё детерминировано и предсказуемо.
AI-агент? Он вероятностный. Вы даёте одинаковый промпт дважды — получаете разные результаты. Он принимает решения "на лету": какой файл читать, какую команду выполнить, когда остановиться.
Мы знаем:
-
Что агент делает (actions)
-
Что он возвращает (outputs)
-
Сколько это стоит (tokens)
Мы НЕ знаем:
-
Почему он принял именно такое решение
-
Были ли альтернативы лучше
-
Оптимален ли его path
Это и есть фундаментальная проблема observability в мире LLM: мы можем наблюдать что происходит, но не всегда понимаем почему.
Часть II: Langfuse — телескоп для чёрного ящика
Что такое Langfuse и почему он популярен
Langfuse — это open-source платформа для observability LLM-приложений. Если упрощённо: это APM (Application Performance Monitoring) для мира AI. Только вместо HTTP запросов и SQL queries здесь промпты, LLM вызовы и токены.
Цифры популярности:
-
7,500+ звёзд на GitHub (на январь 2026)
-
50,000+ monthly active projects
-
Используется в Anthropic, Replit, SuperAGI и сотнях других компаний
Почему именно Langfuse?
1. Self-hosted + Cloud
Многие компании не хотят отправлять промпты пользователей на чужие сервера. Langfuse можно развернуть у себя за 15 минут. При этом есть и облачная версия для быстрого старта.
2. Vendor-agnostic
Работает с OpenAI, Anthropic, Google, Ollama, и вообще с любым LLM провайдером. Вы не привязаны к экосистеме одного вендора.
3. Developer experience
SDK для Python, jаvascript, Go. Понятная документация. Активное комьюнити. Интеграции с LangChain, LlamaIndex, Vercel AI SDK.
Анатомия Langfuse: Traces, Generations, Spans
Langfuse использует концепцию знакомую по distributed tracing (привет, Jaeger и Zipkin):
Trace — это полный путь выполнения одного запроса пользователя.
Внутри трейса есть:
-
Generations — вызовы LLM (промпт → ответ)
-
Spans — любые другие операции (API calls, database queries, tool executions)
-
Events — моментальные метки (user feedback, errors)
Пример иерархии трейса:
Trace: "Создай функцию для валидации email"
├── Generation: User Prompt → AI Planning
│ └── Input: 230 tokens, Output: 180 tokens, Cost: $0.012
├── Span: Read file (utils.js)
│ └── Duration: 45ms
├── Generation: AI Writing Code
│ └── Input: 450 tokens, Output: 320 tokens, Cost: $0.023
├── Span: Write file (validators.js)
│ └── Duration: 12ms
└── Span: Run tests
└── Duration: 2.3s, Status: SUCCESS
Общая статистика:
-
Total tokens: 1,180
-
Total cost: $0.035
-
Total latency: 4.8s
-
Bottleneck: тесты (48% времени)
Вот теперь вы видите что происходило внутри чёрного ящика.
Часть III: Архитектура решения
Я построил систему состоящую из трёх компонентов, которые работают вместе для полной observability.
Общая схема
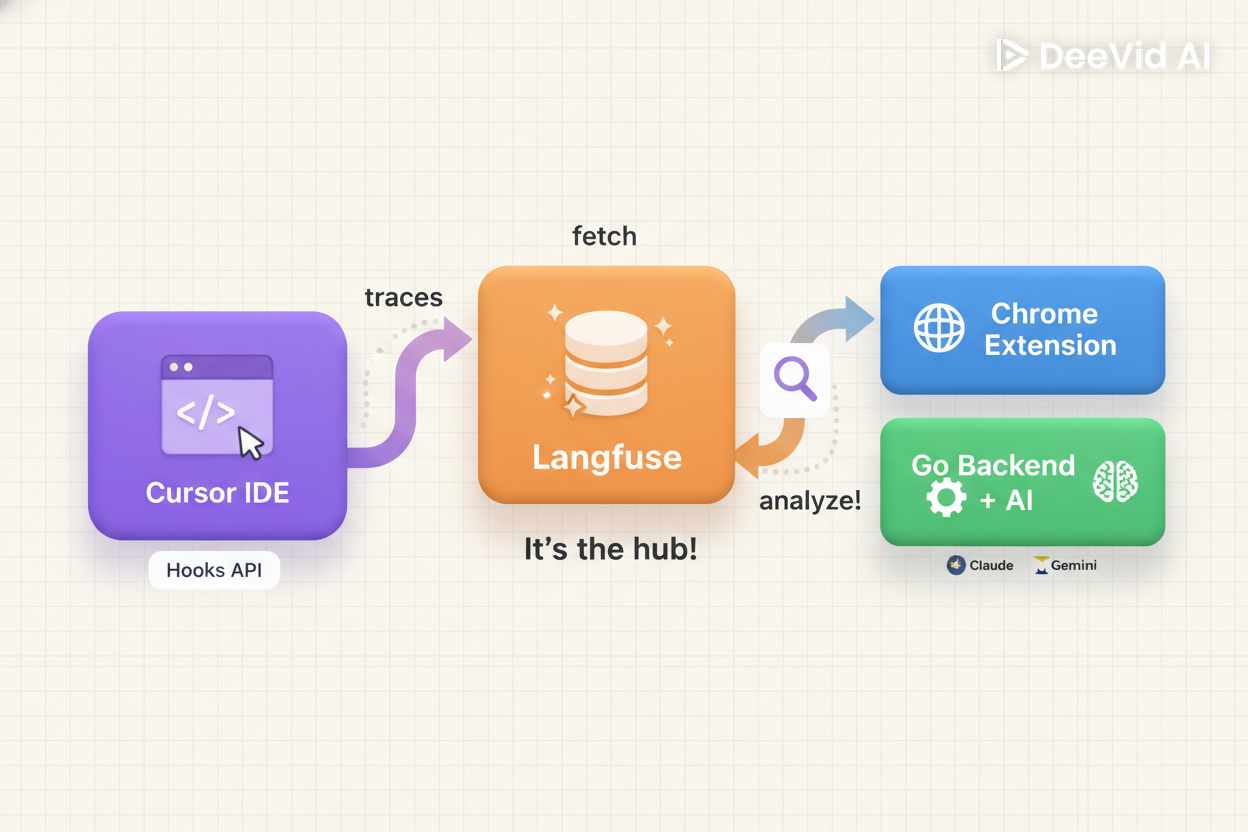
Компонент 1: Cursor Hooks → Langfuse
Перехватывает действия AI-ассистента в IDE и отправляет в Langfuse.
Компонент 2: Chrome Extension
Добавляет кнопку "? AI-Анализ" прямо в UI Langfuse для быстрого доступа.
Компонент 3: Go Backend + AI
Получает trace ID, запрашивает полный трейс из Langfuse API, анализирует через LLM, возвращает структурированные рекомендации.
Зачем три компонента?
Можно было бы обойтись одним — просто Langfuse. Но тогда:
❌ Пришлось бы вручную анализировать каждый трейс
❌ Не было бы автоматической детекции паттернов
❌ Не было бы actionable рекомендаций
Мой подход: данные собирает Langfuse, инсайты генерирует AI.
Часть IV: Cursor Hooks — телеметрия из IDE
Проблема: как отследить невидимое?
Когда вы работаете с Cursor, вы видите только финальный результат работы AI. Но за кулисами происходит намного больше.
Типичный сценарий:
Вы: "Исправь функцию parseDate, она неправильно обрабатывает leap years"
Что видите вы:
[AI печатает код]
...
Done!
Что происходит на самом деле (если бы мы могли заглянуть внутрь):
-
AI читает ваш промпт (230 токенов)
-
AI "думает" 1.2 секунды
-
AI читает файл utils/date.js (850 токенов контекста)
-
AI генерирует исправленный код (420 токенов)
-
AI применяет правку к файлу
-
AI запускает тесты:
npm test -
Тесты выполняются 3.2 секунды
Итого: 3 LLM вызова, 1500 токенов контекста, 420 токенов генерации, 4.4 секунды латентности, $0.04 стоимость.
Без observability всё это остаётся в чёрном ящике.
Решение: Hooks API
Cursor предоставляет Hooks API. В моей реализации используется 7 ключевых событий:
Диалог с AI:
-
beforeSubmitPrompt— ваш промпт отправлен -
afterAgentThought— AI "подумал" (планирование действий) -
afterAgentResponse— AI ответил
Работа с кодом:
-
afterFileEdit— AI отредактировал файл
Выполнение команд:
-
afterShellExecution— выполнена shell команда
MCP Tools:
-
afterMCPExecution— вызван Model Context Protocol инструмент
Завершение:
-
stop— генерация завершена
Техническая реализация
Создаём Node.js скрипт который:
-
Читает событие от Cursor через stdin
-
Немедленно отвечает Cursor (чтобы не блокировать IDE)
-
Асинхронно отправляет данные в Langfuse
async function main() {
const input = await readStdin();
// КРИТИЧНО: сразу отвечаем Cursor
console.log(JSON.stringify({ continue: true }));
// Теперь можем спокойно отправлять в Langfuse
const trace = getOrCreateTrace(input);
routeHookHandler(input.hook_event_name, trace, input);
flushLangfuse()
.finally(() => process.exit(0));
}
Cursor получает немедленный ответ. Отправка в Langfuse не блокирует работу.
Проблема стабильности имён трейсов
Неочевидная сложность: каждый hook вызывается с одним и тем же generation_id. Как понять, создавать новый трейс или обновлять существующий?
Наивная реализация:
function handleHook(input) {
langfuse.trace({
id: input.generation_id,
name: generateName(input) // ← перезаписывает имя!
});
}
Проблема:
-
beforeSubmitPromptсоздаёт трейс "Исправь баг в auth" -
afterAgentThoughtперезаписывает имя на "[SYSTEM] afterAgentThought"
Решение: кэширование трейсов + логика continuation
const CONTINUATION_HOOKS = ['afterAgentThought', 'afterAgentResponse', ...];
const traceCache = new Map();
function getOrCreateTrace(input) {
const cached = traceCache.get(input.generation_id);
// Устанавливаем имя только если это первый hook с промптом
const shouldSetName =
(!cached && input.prompt) ||
(cached && input.prompt && !cached.hasSetName);
const trace = langfuse.trace({
id: input.generation_id,
...(shouldSetName ? { name: input.prompt } : {})
});
traceCache.set(input.generation_id, { trace, hasSetName: shouldSetName });
return trace;
}
Теперь имя трейса устанавливается один раз и не меняется.
Что мы получаем в результате
Трейс в Langfuse выглядит так:
Trace: "Исправь функцию parseDate для leap years"
Session: "my-project | Bug fixing session"
├─ Generation: User Prompt
│ Model: claude-sonnet-3.5, Tokens: 230→180, Cost: $0.012
│
├─ Span: Thinking (1.2s)
│ "Нужно: 1) найти функцию, 2) понять логику, 3) исправить"
│
├─ Span: File Edit — date.js
│ +3 lines, -2 lines
│
├─ Span: Shell — npm test (3.2s)
│ Exit code: 0
│
└─ Score: completion_status = 1.0 (completed)
Ценность: теперь видно всю "кухню" работы AI-агента.
Важная деталь: установка per-project
⚠️ Критически важно: Hooks устанавливаются в каждый проект отдельно, а не глобально.
my-project/
├── .cursor/
│ └── hooks/
│ ├── hook-handler.js
│ └── lib/
│ └── langfuse-client.js
├── .env # ← Langfuse ключи
├── src/
└── ...
Это означает что для работы с несколькими проектами нужно скопировать папку .cursor/ в корень каждого из них.
Часть V: Chrome Extension — мост между мирами
Задача: бесшовная интеграция
Как внедрить функциональность в чужой сайт (Langfuse) без модификации их кода? Особенно если это SPA на Next.js?
Техническая проблема: SPA-навигация
Langfuse работает на Next.js с client-side routing. При клике на трейс:
-
URL меняется:
/project/abc/traces?peek=trace-123 -
Страница не перезагружается
-
DOM частично обновляется через React
Content script загружается только при первой загрузке страницы. Как отследить последующие навигации?
Три неудачных попытки
Попытка 1: MutationObserver на DOM
Проблема: React обновляет только часть DOM. Сложно понять когда навигация завершена.
Попытка 2: Пер��хват History API
Проблема: Конфликтует с React Router, события дублируются.
Попытка 3: popstate listener
Проблема: Работает только для кнопок "назад/вперёд", не для программной навигации.
Решение: URL polling
Простое и надёжное — проверять URL каждые 100ms:
let lastUrl = window.location.href;
setInterval(() => {
const currentUrl = window.location.href;
if (currentUrl !== lastUrl) {
lastUrl = currentUrl;
handleUrlChange();
}
}, 100);
Почему это работает:
-
Не зависит от DOM Langfuse
-
Не требует monkey-patching
-
100ms = 10 проверок/сек, незаметно
-
Overhead: ~0.1ms на проверку
Надёжность: 9/10. Единственная зависимость — структура URL, которая вряд ли изменится (это сломает закладки пользователей).
Сохранение trace ID
Ещё одна проблема: между созданием кнопки и кликом URL может измениться (Langfuse закрыл modal).
Решение: сохраняем trace ID в data-атрибуте при создании кнопки:
// При создании кнопки
appRoot.dataset.traceId = currentTraceId;
// При клике
const traceId = appRoot?.dataset.traceId;
Теперь trace ID "заморожен" и не теряется при изменении URL.
Как это выглядит в действии
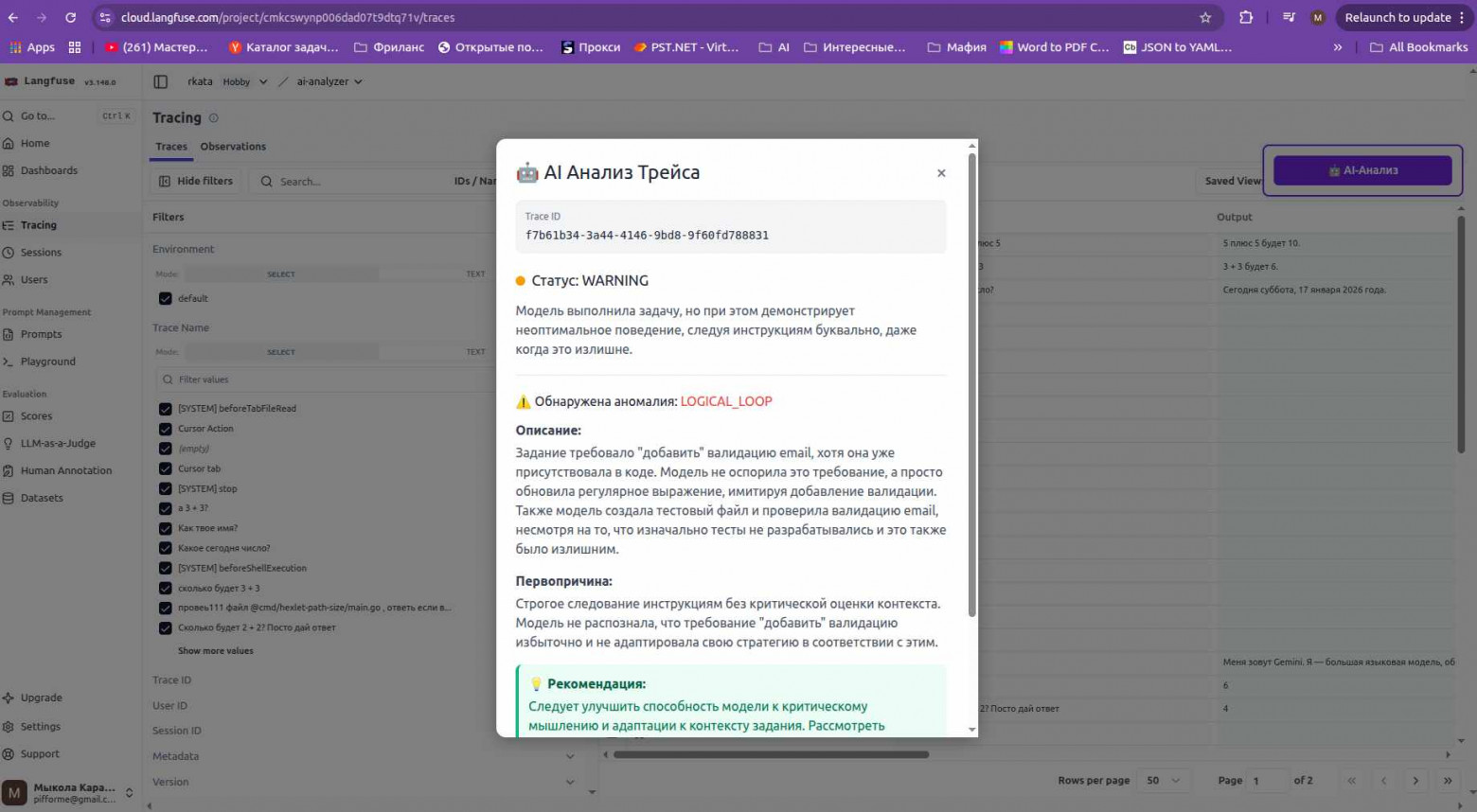
Кнопка "AI-Анализ" в правом верхнем углу и результат анализа с детекцией логического цикла
На скриншоте видно:
-
Кнопка "? AI-Анализ" появляется в fixed position
-
Модальное окно с результатом анализа
-
Статус WARNING с типом аномалии LOGICAL_LOOP
-
Конкретные рекомендации по исправлению
Часть VI: Go Backend — мозг операции
Почему Go?
Выбор языка — всегда компромисс. Для AI обычно выбирают Python. Но мне привычнее Go:
Что нужно:
-
Принимать HTTP запросы
-
Получать трейс из Langfuse API
-
Вызывать LLM для анализа
-
Отдавать результат
Почему Go:
-
✅ Быстрая компиляция (5 сек vs 30+ для Python)
-
✅ Один бинарник без зависимостей
-
✅ Встроенная concurrency
-
✅ Отличная экосистема HTTP/JSON
-
✅ Простая работа с OpenAI-совместимыми API
Поддержка множественных AI провайдеров
Ключевая фича — гибкость выбора модели:
-
OpenRouter (production): Единый API для GPT-4, Claude, Gemini. Платно, но надёжно.
-
Ollama (разработка): Локальные модели. Бесплатно, но требует мощное железо.
Реализация через интерфейс:
type AIClient interface {
AnalyzeTrace(ctx context.Context, data map[string]interface{}) (string, error)
}
func NewAIClient(provider ProviderType, ...) AIClient {
switch provider {
case ProviderOllama:
return NewOllamaClient(...)
default:
return NewOpenAIClient(...)
}
}
Переключение в .env:
AI_PROVIDER=openrouter # или "ollama"
Обработка ошибок AI провайдеров
LLM API падают. Часто. Нужна правильная обработка:
-
429 Too Many Requests— rate limit -
402 Payment Required— кончились деньги -
503 Service Unavailable— модель перегружена
type AIError struct {
StatusCode int
Message string
RetryAfter int
}
// В handler
if errors.As(err, &aiErr) {
switch aiErr.StatusCode {
case 429:
c.JSON(429, gin.H{
"error": "Слишком много запросов",
"retryAfter": aiErr.RetryAfter
})
case 402:
c.JSON(402, gin.H{
"error": "Недостаточно кредитов"
})
}
}
Расширение показывает правильное сообщение пользователю.
Интеграция с Langfuse API
Получение трейса — простой HTTP GET с retry логикой (3 попытки с exponential backoff):
for attempt := 1; attempt <= 3; attempt++ {
resp, err := client.Do(req)
if err != nil {
if attempt < 3 {
time.Sleep(time.Duration(attempt) * time.Second)
continue
}
return nil, err
}
return parseResponse(resp), nil
}
Задержки: 1s, 2s, 3s. Это спасает ~95% временных сбоев Langfuse API.
CORS настройка
⚠️ Критически важно для работы с Chrome Extension:
Backend должен разрешать запросы от расширения. В .env:
ALLOWED_ORIGINS=https://cloud.langfuse.com,chrome-extension://YOUR\_EXTENSION\_ID
Где взять ID расширения:
-
Откройте
chrome://extensions/ -
Найдите "Chrome Extension для Langfuse"
-
Скопируйте строку ID: из карточки
Часть VII: AI анализирует AI — TraceDebugger
Промпт-инжиниринг для детекции аномалий
Самая интересная часть — научить AI анализировать трейсы других AI.
Задача: дать LLM трейс в JSON и получить структурированный анализ:
-
Всё ли в порядке? (HEALTHY/WARNING/ERROR)
-
Какая проблема? (PERFORMANCE_BOTTLENECK/HIGH_COST/LOGICAL_LOOP/ERROR/NONE)
-
В чём причина?
-
Как исправить?
Системный промпт:
Ты — 'TraceDebugger', AI-аналитик для LLM-приложений.
Проанализируй JSON-трейс из Langfuse и дай структурированный отчет.
Инструкции:
1. Изучи latency и totalCost
2. Проанализируй observations (steps)
3. Выяви аномалии
4. Верни результат в JSON
Формат ответа:
{
"analysisSummary": {
"overallStatus": "HEALTHY | WARNING | ERROR",
"keyFinding": "Вывод в одном предложении"
},
"detailedAnalysis": {
"anomalyType": "NONE | ERROR | PERFORMANCE_BOTTLENECK | HIGH_COST | LOGICAL_LOOP",
"description": "Описание проблемы",
"rootCause": "Гипотеза о причине",
"recommendation": "Конкретный совет"
}
}
Критически важно:
-
ResponseFormat: JSON — гарантирует валидный JSON
-
Чёткие категории (не размытые определения)
-
Actionable рекомендации (не общие советы)
Типы аномалий с конкретными критериями
PERFORMANCE_BOTTLENECK
Детекция: latency > 10s ИЛИ одна операция занимает >70% времени
Пример:
{
"anomalyType": "PERFORMANCE_BOTTLENECK",
"description": "Shell команда 'npm install' выполнялась 12.3с (82% времени)",
"rootCause": "npm install загружает зависимости с нуля",
"recommendation": "Используйте npm ci в CI/CD — в 2-3 раза быстрее"
}
HIGH_COST
Детекция: totalCost > $0.20 ИЛИ >5000 токенов на простой запрос
Пример:
{
"anomalyType": "HIGH_COST",
"description": "8,450 токенов для ответа на вопрос '2+2'",
"rootCause": "Агент загрузил 5 файлов в контекст (по 1500 токенов)",
"recommendation": "Добавьте routing: для простых вопросов — lightweight модель без контекста"
}
LOGICAL_LOOP
Детекция: операция повторяется >3 раз с похожими результатами
Пример:
{
"anomalyType": "LOGICAL_LOOP",
"description": "Агент 5 раз редактировал auth.js, тесты падали с той же ошибкой",
"rootCause": "Агент исправляет симптом, не видит причину (импорт отсутствует)",
"recommendation": "Добавьте в промпт: 'Перед правкой проанализируй все импорты'"
}
ERROR
Детекция: exit code != 0, exceptions, failed API calls, compilation errors
Пример:
{
"anomalyType": "ERROR",
"description": "Компиляция Go кода завершилась с ошибкой",
"rootCause": "Syntax error в main.go:42 — missing closing brace",
"recommendation": "AI предложил код с синтаксической ошибкой. Добавьте в промпт: 'Убедись что код компилируется без ошибок'"
}
NONE
Всё в порядке, проблем не обнаружено.
Ценность: Сразу видно что пошло не так и почему. Не нужно искать в логах или выводе команд.
Влияние данных из Cursor Hooks
Без hooks:
{
"description": "Трейс медленный, 15 секунд",
"recommendation": "Оптимизируйте код"
}
Бесполезно.
С hooks (shell execution):
{
"description": "pip install requirements.txt выполнялся 12с из 15с",
"rootCause": "Установка зависимостей без кеша",
"recommendation": "Используйте Docker image с pre-installed зависимостями"
}
Конкретно и actionable.
Часть VIII: Что даёт observability на практике
Видимость = Возможность оптимизации
Без трейсинга вы слепы. С трейсингом вы видите:
Что читает AI:
-
Какие файлы
-
Сколько токенов
-
Релевантны ли они задаче
Что выполняет AI:
-
Какие команды
-
Сколько времени
-
Можно ли быстрее
Как думает AI:
-
Какие решения принимает
-
Где ошибается
-
Где зацикливается
TraceDebugger как AI-наставник
Вместо того чтобы самому анализировать трейсы, вы получаете:
✅ Автоматическую детекцию 5 типов ситуаций (HEALTHY/ERROR/BOTTLENECK/COST/LOOP)
✅ Объяснение первопричины
✅ Конкретные рекомендации с примерами
✅ Моментальный feedback (2-5 секунд на анализ)
Это как pair programming, но с AI который знает observability.
Применимость за пределами Cursor
Хотя я фокусировался на Cursor IDE, подход универсален:
Cursor Hooks можно заменить на:
-
LangChain callbacks
-
LlamaIndex observers
-
Vercel AI SDK telemetry
-
Кастомные обёртки над LLM API
Chrome Extension работает с:
-
Любым Langfuse инстансом (cloud или self-hosted)
-
Можно адаптировать под другие observability платформы
TraceDebugger анализирует:
-
Любые LLM трейсы (не только Cursor)
-
Production приложения
-
Chatbots, agents, RAG pipelines
Заключение: будущее AI observability
Куда движется индустрия
-
2024: "LLM — это просто API, вызвал и получил ответ"
-
2025-2026: "LLM — это агенты, им нужна полноценная телеметрия"
Observability для AI переходит из "nice to have" в "must have". Причины:
-
Стоимость растёт. Счета за API становятся значительной статьёй расходов.
-
Агенты усложняются. Простой "промпт → ответ" превращается в multi-step workflows с tool calling, RAG, memory.
-
Compliance. Регуляторы интересуются AI. Нужно доказать что система работает корректно.
Выводы
Построил систему полной observability для AI-агентов:
-
Cursor Hooks — телеметрия из IDE в реальном времени
-
Chrome Extension — бесшовная интеграция в Langfuse UI
-
Go Backend — обработка и AI-анализ трейсов
-
TraceDebugger — AI анализирует AI автоматически
Ключевые достижения:
✅ Видимость всех операций агентов
✅ Автоматическая детекция аномалий
✅ Production-ready архитектура
✅ Open-source, можно адаптировать под себя
Главный инсайт: Мы не можем полностью понять почему AI принимают решения (это фундаментальная проблема нейросетей). Но мы можем видеть что они делают, измерять эффективность, оптимизировать на основе данных.
Observability — это не просто мониторинг. Это способность делать AI-системы лучше через continuous feedback loop:
измерить → проанализировать → оптимизировать → повторить
В мире где AI-агенты становятся всё более автономными, observability — не роскошь, а необходимость.
Ссылки и ресурсы
-
Langfuse: https://langfuse.com
-
Cursor Hooks: https://docs.cursor.com/context/hooks
-
GitHub репозиторий проекта: https://github.com/motokazmin/langfuse-extension
Технологии:
-
Frontend: TypeScript, Vite, Chrome Extensions Manifest V3
-
Backend: Go, Gin
-
AI: OpenRouter (Claude, Gemini), Ollama
-
Observability: Langfuse
Весь код доступен в open-source. Смотрите README в репозитории для инструкций по развёртыванию.










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое