Gemini 3 научили вглядываться в изображения как человек
Google представил Agentic Vision — новую возможность модели Gemini 3 Flash, которая превращает анализ изображений из одномоментного "взгляда" в пошаговое исследование. Если раньше модель могла пропустить мелкую деталь вроде серийного номера или отдаленного дорожного знака и была вынуждена угадывать, то теперь она способна сама решить, куда приблизиться и что рассмотреть внимательнее.
Технически это работает через цикл "думай — действуй — наблюдай". Модель анализирует запрос, формулирует план, а затем генерирует Python-код для манипуляций с изображением — обрезает нужный фрагмент, поворачивает, рисует поясняющие метки. Результат возвращается в контекстное окно, и модель продолжает анализ уже с новыми данными. По сути, изображение становится не входными данными, а рабочей средой.
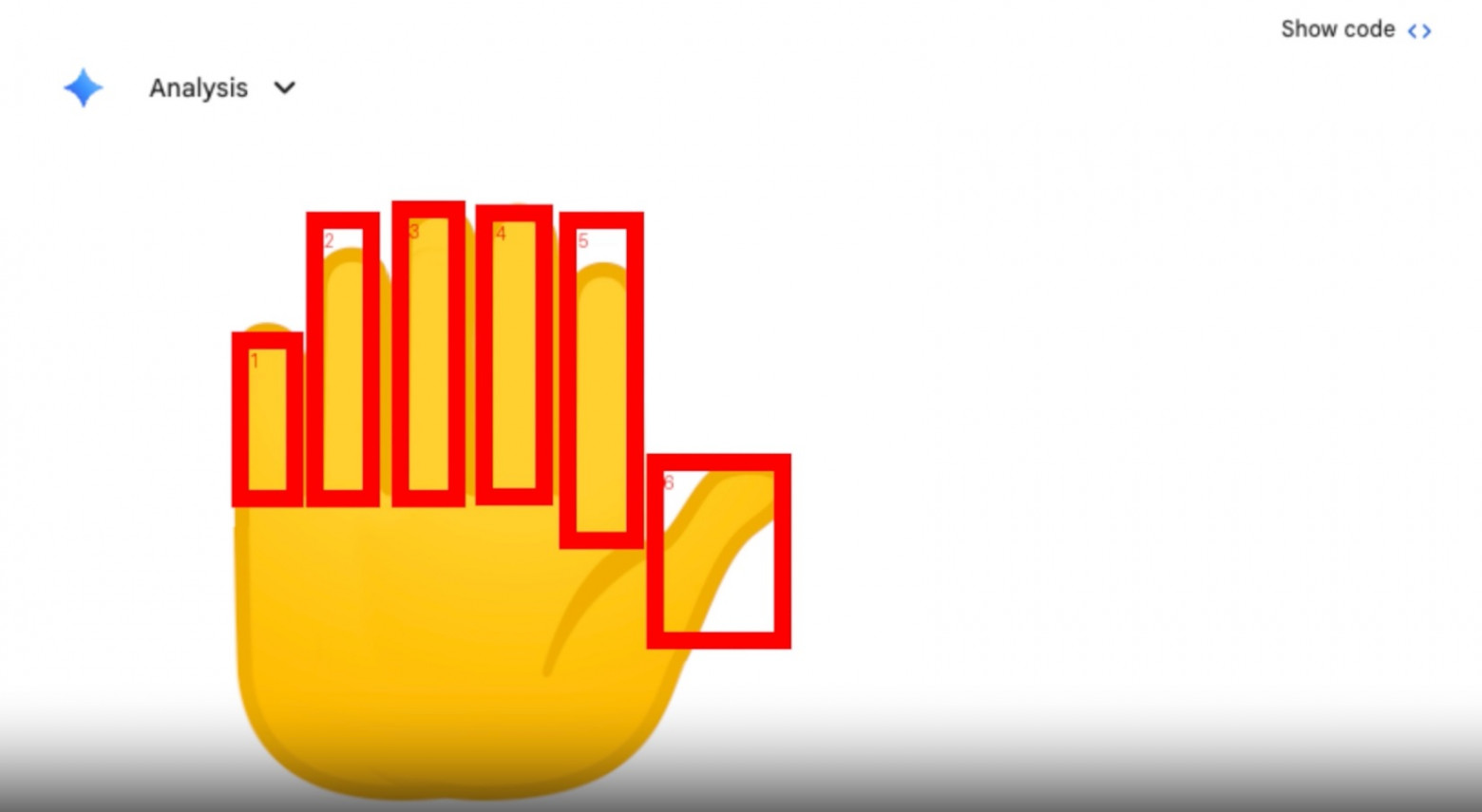
Google приводит несколько примеров. Платформа PlanCheckSolver для проверки строительных чертежей повысила точность на 5%, используя итеративный зум по участкам плана. В приложении Gemini модель при подсчете пальцев на фото рисует bounding box вокруг каждого, чтобы не сбиться. А при работе с таблицами — парсит данные и строит график в Matplotlib вместо того, чтобы пересказывать цифры словами.
По данным Google, включение code execution дает стабильный прирост 5–10% на большинстве визуальных бенчмарков. Agentic Vision уже доступен через Gemini API в Google AI Studio и Vertex AI, а также появляется в приложении Gemini в режиме Thinking.
P.S. Поддержать меня можно подпиской на канал "сбежавшая нейросеть", где я рассказываю про ИИ с творческой стороны.










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое