Классический IDP и VLM в обработке документов: почему выигрывает комбинация подходов

В прошлых материалах мы уже рассказывали о том, как мультимодальные модели (VLM) справляются с извлечением данных из финансовых документов, и показывали, что в ряде сценариев они могут конкурировать с оптимизированными классическими IDP-решениями. Однако мы решили не ограничиваться одним типом документов и продолжили исследование, сравнив технологии на широком спектре материалов. В пул вошли сканы высокого качества и фотографии со сложным фоном, структурированные табличные формы и документы с элементами рукописного текста, русскоязычные и англоязычные тексты.
Сегодня мы готовы поделиться сводными итогами.
И сразу спойлер: наш главный вывод подтвердился. Будущее — не в выборе одной технологии, а в их грамотной интеграции. Но теперь у нас есть точные цифры, которые показывают, когда и почему один подход выигрывает у другого, и как построить гибридную систему, которая сочетает надежность классики с интеллектуальной мощью нейросетей.
Как проводилось сравнение: инфраструктура и условия тестирования
Как и на первой стадии исследования, большинство облачных моделей мы запускали через OpenRouter. Это позволило работать с единым интерфейсом вызова, одинаковыми настройками инференса и сопоставимыми лимитами контекста.
Подход снизил влияние инфраструктурных различий и позволил сравнивать именно качество распознавания, а не особенности конкретного API.
Часть open source моделей запускали локально через Ollama. В этом случае использовали квантованные версии – q4, q8. Это важно учитывать при интерпретации результатов: такой запуск дает представление о практической применимости моделей, но может влиять на скорость и итоговое качество по сравнению с облачным инференсом.
Для оценки классического OCR использовали продукты Content AI:
-
OCR SDK ContentReader Engine как референс для печатных документов;
-
IDP-платформу ContentCapture как референс для рукописных материалов.
Универсальные VLM и русский язык: результаты сравнения с классическим OCR
На простых печатных документах формата A4 (одноколоночные тексты) ContentReader Engine показал лучший результат. При этом большинство VLM продемонстрировали близкие значения по метрикам Char F1 и Word F1, что говорит о том, что на базовых сценариях извлечения текста разрыв между подходами заметно сократился.
-
Char F1 отражает точность распознавания на уровне отдельных символов и показывает, насколько корректно модель восстанавливает текст посимвольно.
-
Word F1 оценивает качество на уровне слов и измеряет совпадение распознанных слов с эталонным текстом, учитывая как пропуски, так и лишние слова.
В совокупности метрики позволяют понять, читается ли текст в целом и подходит ли для дальнейшей автоматической обработки.
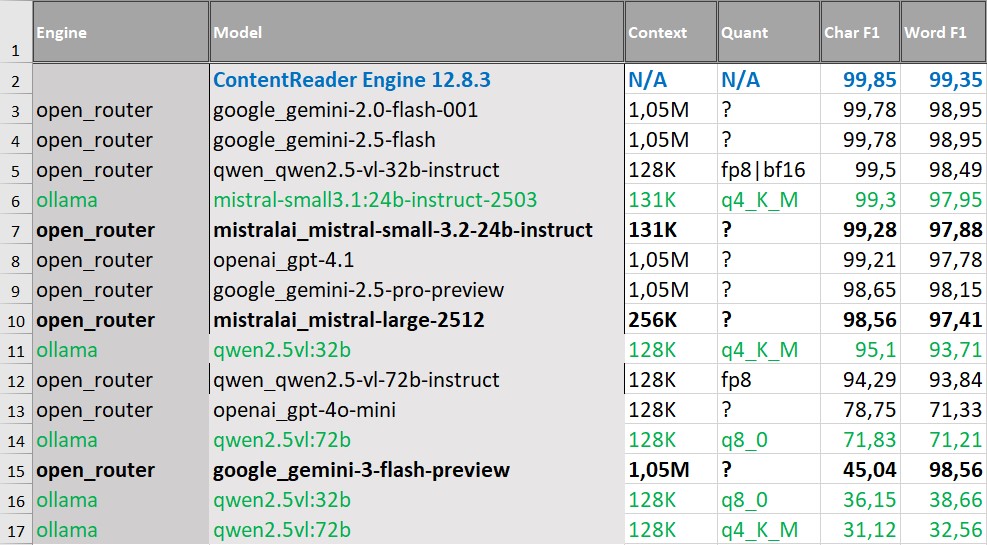
Вывод: для документов простой структуры классический OCR обеспечивает максимальное качество распознавания.
Когда точность символов не решает задачу обработки документа
В распознавании документов со сложной структурой единственной моделью, которая опередила классический OCR по метрикам, стала Gemini 2.5 Pro Preview. В этом сценарии она показала более высокие итоговые значения по сравнению с ContentReader Engine — 96,07% против 93,9%.
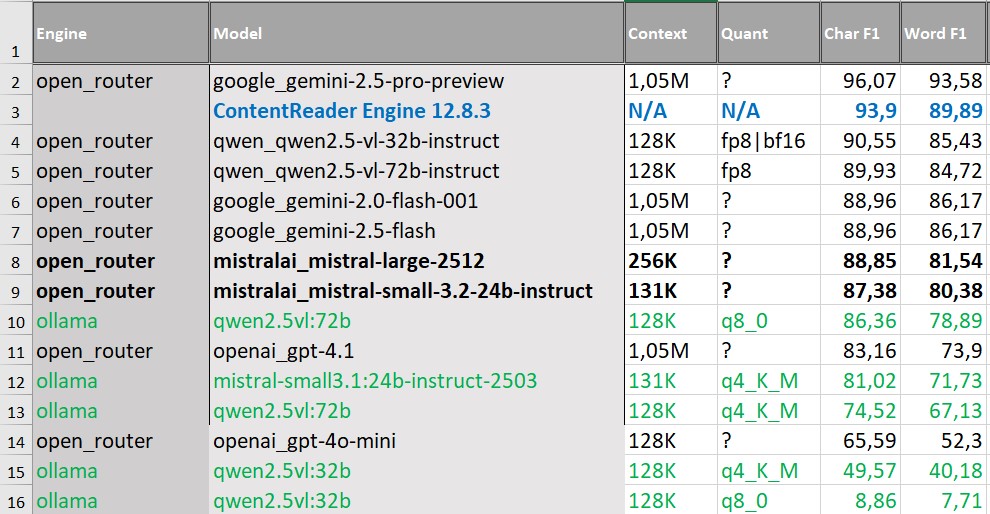
При этом результат не означает преимущества VLM как класса в целом. Кроме Gemini, Word F1 у всех моделей находится ниже 86%. Это означает, что символы распознаются корректно, но качество текста на уровне слов ухудшается.
Даже при высоком Char F1, когда отдельные буквы модель распознала верно, ошибки в разбиении строк и колонок приводят к тому, что слова теряются, склеиваются или дублируются. В таких случаях текст формально распознан, но использовать его дальше — для поиска, извлечения полей или автоматической обработки — уже сложно.
Англоязычные документы с простой и сложной структурой
На англоязычных документах со сложной, многоколоночной версткой лучшие результаты располагаются в одном диапазоне. Лидируют здесь VLM — Gemini 2.5 Pro Preview и Qwen2.5-VL-72B-Instruct. Однако разрыв с классическим OCR составляет менее одного процента.
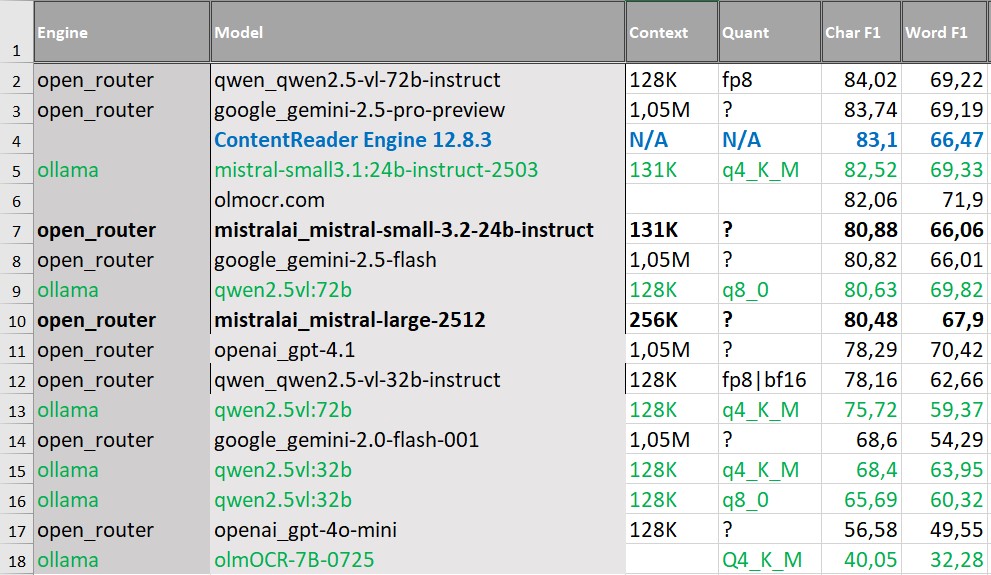
При этом ключевым ограничением для всех решений остается Word F1. Даже у моделей из верхней части таблицы этот показатель не превышает ~70%, что указывает на сложности с восстановлением структуры текста при плотной и многоколоночной верстке. Символы в целом распознаются корректно, но ошибки в разбиении строк, колонок и порядке блоков приводят к ухудшению качества текста на уровне слов.
VLM хорошо справляются с извлечением текста, и выбор подхода определяется скорее требованиями к скорости, стоимости и интеграции.
На англоязычных документах простой структуры (одноколоночные A4) различия между решениями сглаживаются еще сильнее. ContentReader Engine занимает первую строку таблицы, однако большинство VLM располагаются рядом и показывают сопоставимые значения метрик — разница составляет доли процента.
В верхней части списка находятся модели семейств Gemini, Qwen и Mistral, которые демонстрируют близкие результаты как по Char F1, так и по Word F1.
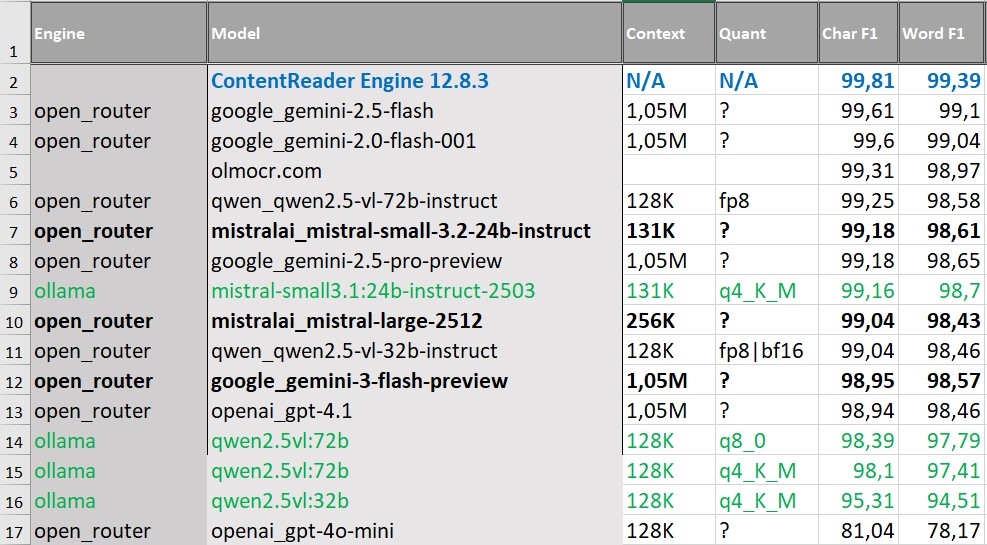
Подводя промежуточные итоги, можно сказать, что для документов простой структуры задача полнотекстового распознавания фактически решена. Как классический OCR, так и современные VLM уверенно распознают текст.
Фотографии инвойсов и сложный визуальный фон
Фотографии документов со сложным визуальным фоном — отдельный тип данных, где на качество распознавания влияют искажения. Например, неравномерное освещение, фон, водяные знаки, ламинация, шум и другие дефекты.
По результатам сравнения в этом сценарии на верхних позициях находятся VLM и, в первую очередь, модели семейства Gemini.
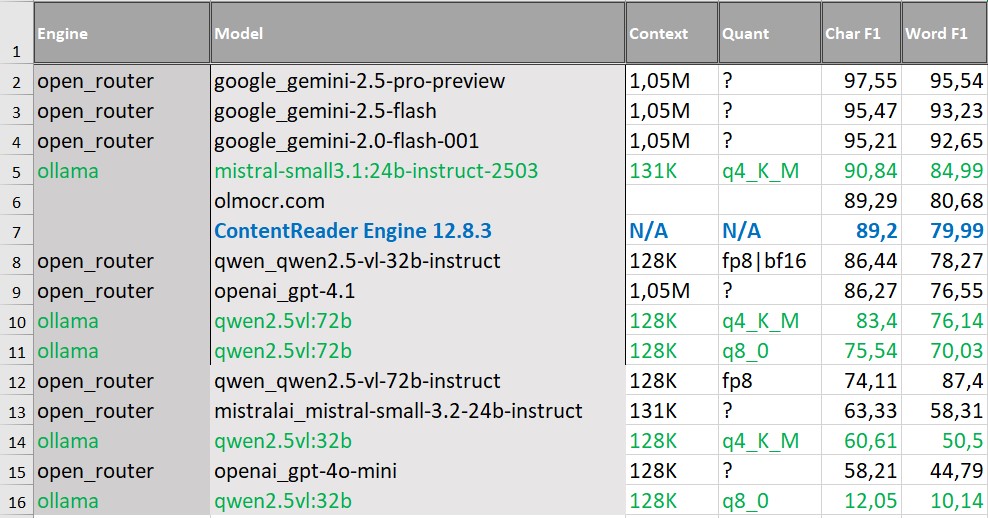
При этом мы видим высокую вариативность качества между разными VLM: разрыв между верхней и нижней частью списка значителен. Это означает, что выбор конкретной модели критичен, а сам класс VLM не гарантирует стабильного результата на всех типах изображений.
С практической точки зрения этот сценарий подчеркивает необходимость комбинированного подхода при реальном внедрении.
-
VLM выигрывают за счет работы с контекстом и статистических языковых закономерностей, что позволяет восстанавливать текст даже при сильных визуальных искажениях.
-
Классический OCR, напротив, опирается только на имеющееся изображение и потому остается надежной базой для потоковой обработки структурированных сканов и документов.
Таблицы и формы: роль классического OCR в обработке
Специфика обработки табличных документов и форм, например, русскоязычных счетов и счетов-фактур, отличается тем, что в них важно не только распознать символы, но и корректно восстановить структуру строк, колонок, повторяющихся блоков, взаимосвязанных полей.
При распознавании таких документов лидирующие позиции занимают отдельные VLM, а именно модели Google Gemini. ContentReader Engine уступает по метрикам полнотекстового распознавания.
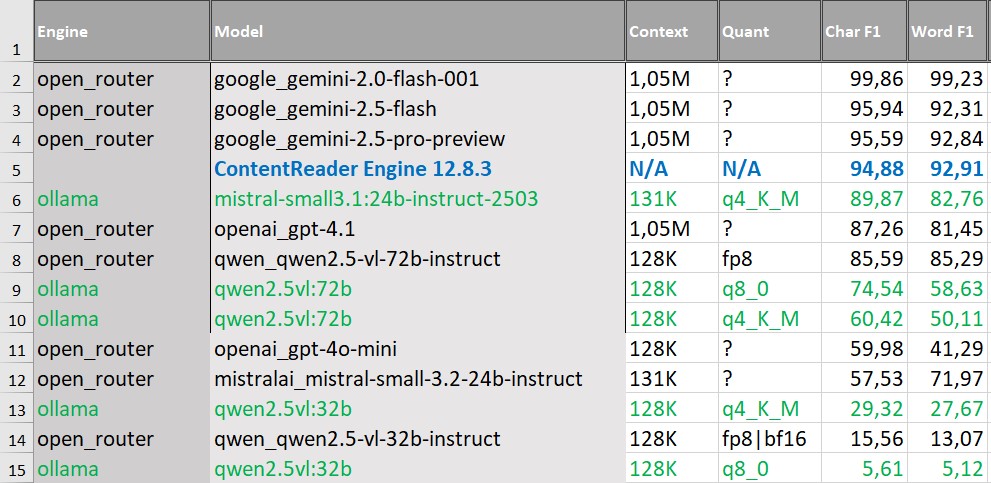
Ключевой фактор здесь — пригодность результата для дальнейшей автоматической обработки. Универсальные VLM хорошо распознают содержимое таблиц, но чаще допускают ошибки в восстановлении структуры, что требует дополнительной постобработки. Классический OCR обеспечивает здесь более предсказуемый результат.
Наша практика показывает, что именно сочетание классического OCR и последующих этапов воссоздания таблиц и других структурных элементов позволяет надежно работать с документами такого типа. Этот же принцип распространяется и на другие типы документов: VLM усиливают обработку сложных случаев, но устойчивое качество достигается за счет архитектуры, в которой классический OCR и VLM дополняют друг друга.
Российские ID-документы: точность чтения против пригодности результата
Обработка ID-документов — паспортов, свидетельств о рождении, ИНН, СНИЛС — относится к наиболее чувствительным сценариям. Здесь критично важна корректность распознавания текста и высокая точность извлечения данных из формализованных полей, типовых шаблонов.
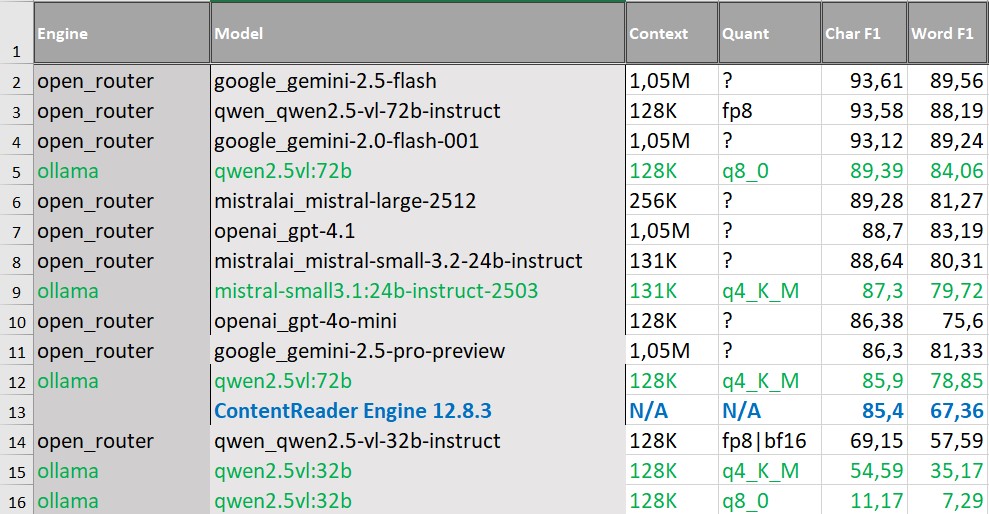
Gemini, Qwen, GPT и Mistral показывают более высокие значения метрик полнотекстового распознавания. При этом результаты отражают важную особенность ID-документов. Для таких форм качество потоковой обработки определяется не столько классическим полнотекстовым OCR, сколько корректным извлечением полей: ФИО, дат, серий и номеров, кодов подразделений. Ошибка даже в одном символе или неверно выделенное поле делает результат непригодным, независимо от того, насколько хорошо распознан остальной текст.
VLM способны распознавать ID-документы, но без дополнительной проверки и верификации их результат не может считаться надежным. Для таких сценариев важны контроль форматов, проверка допустимых значений и сопоставление полей между собой.
Устойчивое качество достигается за счет связки, в которой классический OCR и последующие этапы структурной обработки и верификации играют ключевую роль, а VLM используются как дополнительный инструмент для сложных случаев.
Рукописные документы: где универсальные модели дают преимущество
Финальные этапы исследования касались распознавания рукописного текста — сканов сочинений ЕГЭ. Это один из самых сложных сценариев для автоматической обработки, так как в отличие от печатных форм, здесь резко возрастает вариативность почерка и проявляются дефекты сканирования.
Дополнительную сложность в этом корпусе создает языковая неоднородность: рукописные тексты могут содержать орфографические и стилистические ошибки. В таких условиях VLM, опирающиеся на вероятностную языковую модель, склонны восстанавливать текст до наиболее статистически вероятных словоформ. Это повышает читаемость результата, но может приводить к искажению исходного содержания — что критично, когда требуется строгое соответствие оригиналу, а не его интерпретация.
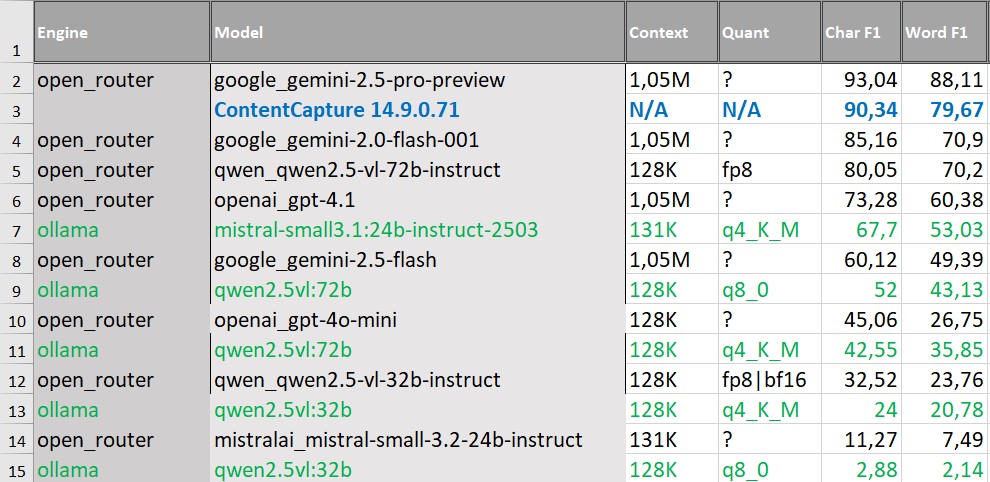
Наилучшие результаты демонстрируют крупные VLM, в частности Gemini 2.5 Pro Preview. IDP-платформа ContentCapture занимает вторую позицию, а разрыв между лидерами и остальной частью таблицы здесь значительно больше, чем в тестах на печатных документах. Это показывает, что рукописный текст остается областью, где VLM действительно дают преимущество за счет работы с контекстом и способности восстанавливать смысл при низком качестве отдельных символов.
Общий вывод исследования:
В 2026 году классический IDP и VLM перестают рассматриваться как альтернативные подходы. По отдельности каждый из них решает лишь часть задачи обработки документов.
-
Классический IDP остается фундаментом: он обеспечивает стабильное распознавание текста, корректную работу со сложной структурой, высокую производительность и предсказуемые затраты при потоковой обработке документов. Эти характеристики критичны для корпоративных заказчиков.
-
VLM предпочтительны в тех случаях, где для корректного распознавания требуется использовать контекст. Здесь модели демонстрируют преимущества. Однако побочным эффектом могут быть галлюцинации. Кроме того, стоимость автоматизации обработки документов на основе VLM и последующее обслуживание инфраструктуры гораздо выше, чем при использовании классических IDP-систем.
-------------------------------------------------------------------
Это блог компании Content AI. Мы помогаем работать с информацией умнее — автоматизировать обработку документов, извлекать данные и повышать качество бизнес-процессов с помощью собственных технологий и современного ИИ. Здесь рассказываем, как разрабатываем продукты и делимся опытом, архитектурными решениями и кейсами внедрения интеллектуальной автоматизации.
Наш Telegram-канал со всеми новостями: https://t.me/chatgptdom_telegram_bot>










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое