Как ИИ-агент Софья обрела личность, симуляция мира в реальном времени и почему LLM — не тупик на пути к AGI

Январь 2026 года показал важную вещь. Сегодня идут споры о том, насколько искусственный интеллект способен удерживать целостную модель мира. Ещё недавно нейросети умели генерировать красивые видео. Но стоило в промпте попросить: «пройди вперёд», «оглянись», «вернись» — и прежняя сцена попросту пропадала.
Объекты «плыли», текстуры менялись, причинно-следственные связи исчезали. Сгенерированный мир не выдерживал движения камеры. Он не был моделью мира — он был просто иллюзией.
Теперь появляются open-source модели, которые создают управляемые миры в реальном времени. Можно двигаться, менять события, возвращаться к объектам — и всё остаётся на своих местах. Это первый шаг от простой генерации к симуляции мира.
Агенты тоже меняются. Раньше у них не было биографии. А без памяти о себе нет и саморазвития. Каждый новый день для них был как первый — настоящий «день сурка».
Теперь появляется Софья — агент с автобиографией, долгосрочной памятью и собственной мотивацией. Она запоминает ошибки, накапливает опыт и со временем меняет стратегии. Как будто по-настоящему взрослеет.
В программировании исчезает иллюзия автопилота. Лучшие разработчики не доверяют «вайб-кодингу». Они управляют агентами, проверяют шаги, задают рамки. Выигрывает не тот, у кого самый умный ИИ, а тот, кто умеет им управлять.
Сегодня ИИ учится без датасетов — придумывая задачи сам себе. Он начинает спорить сам с собой. Роботы учатся чувствовать глубину сцены и понимать, продвигаются ли они к цели. Агенты-оркестраторы координируют десятки субагентов, чтобы те не теряли контекст.
Говорят, что LLM — тупик. Но сами по себе языковые модели действительно не дают общего интеллекта. Интеллект появляется там, где есть память, цели, проверка данных и мультиагентная координация.
Это обзор лучших исследований января 2026 года. Поехали!
1. Open-source наносит ответный удар: управляемая симуляция мира в реальном времени

Ещё вчера нейросети умели просто генерировать ролики. Но мир не выдерживал движения камеры. Стоило попросить «пройди вперёд» и весь сгенерированный мир рассыпался.
Происходит переход от text-to-video к text-to-world. Это уже не последовательность кадров, а управляемая среда.
Новые open-source модели создают мир в реальном времени. Можно двигаться, крутить камеру, возвращаться к объектам — и сцена остаётся согласованной. Модель обучена на реальных видео, игровых записях и синтетических данных из Unreal Engine, где известны действия и параметры камеры.
Управление встроено прямо в нейросеть. Затем инференс ускорили почти до реального времени — задержка меньше секунды. В результате получается «почти игра»: длинная память, динамика, возможность менять погоду или события без разрушения сцены.

Код и веса открыты. Это ещё не идеальный цифровой мир. Но это прочный мост от генерации к настоящим моделям мира.

? Обзор статьи | ? Полная статья | ? Код | ? Модель
2. Почему ИИ-агенты не помнят собственную жизнь — и как агенту Софье дали автобиографию, мотивацию и долгосрочную память

Современные агенты умны, но забывчивы. Они планируют, вызывают инструменты, решают задачи — но почти не помнят свою историю. Каждый день для них как первый.
Исследователи предложили архитектуру «Система-3». Если Система-1 действует, Система-2 рассуждает, то Система-3 следит за самим мышлением: хранит автобиографию, ставит долгосрочные цели, проверяет себя и формирует внутреннюю мотивацию.
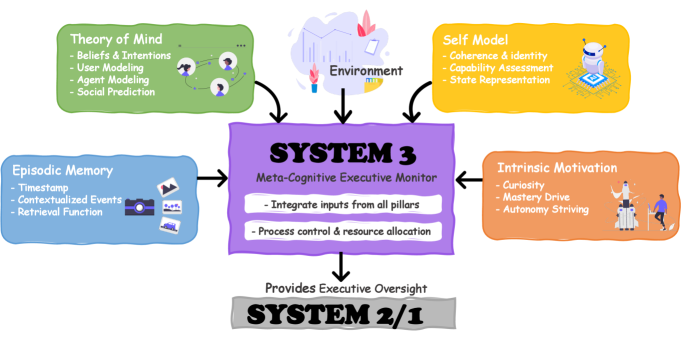
Так появилась Софья. У неё есть эпизодическая память, модель пользователя, модель себя и гибридная награда — внешняя оценка плюс внутреннее любопытство. Она сохраняет успешные стратегии, учится на ошибках и постепенно меняет привычки.
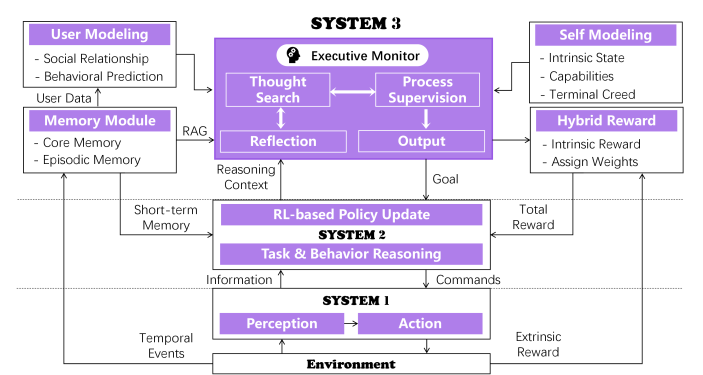
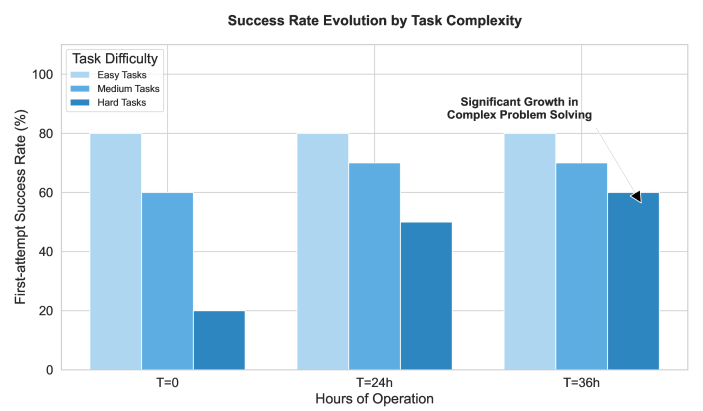
В экспериментах Софья сокращала рассуждения на 80% в повторяющихся задачах и повышала успешность сложных задач примерно на 40%.
Это шаг к гиперперсонализированным агентам, которые живут в информационной среде, помнят, развиваются и со временем начинают действовать стратегически.
? Обзор статьи | ? Полная статья
3. Профессиональные разработчики не вайбят с агентами — они их контролируют

ИИ-агенты уже умеют читать весь проект, менять файлы и запускать тесты. На словах — магия: описал задачу и получил код.
Это называют «вайб-кодингом»: доверился ИИ и ничего не проверяешь.

Но в реальной разработке так не работает. Опытные разработчики не отдают управление агенту. Они дробят задачи, заранее задают рамки, читают каждый pull request, запускают тесты и проверяют архитектуру.
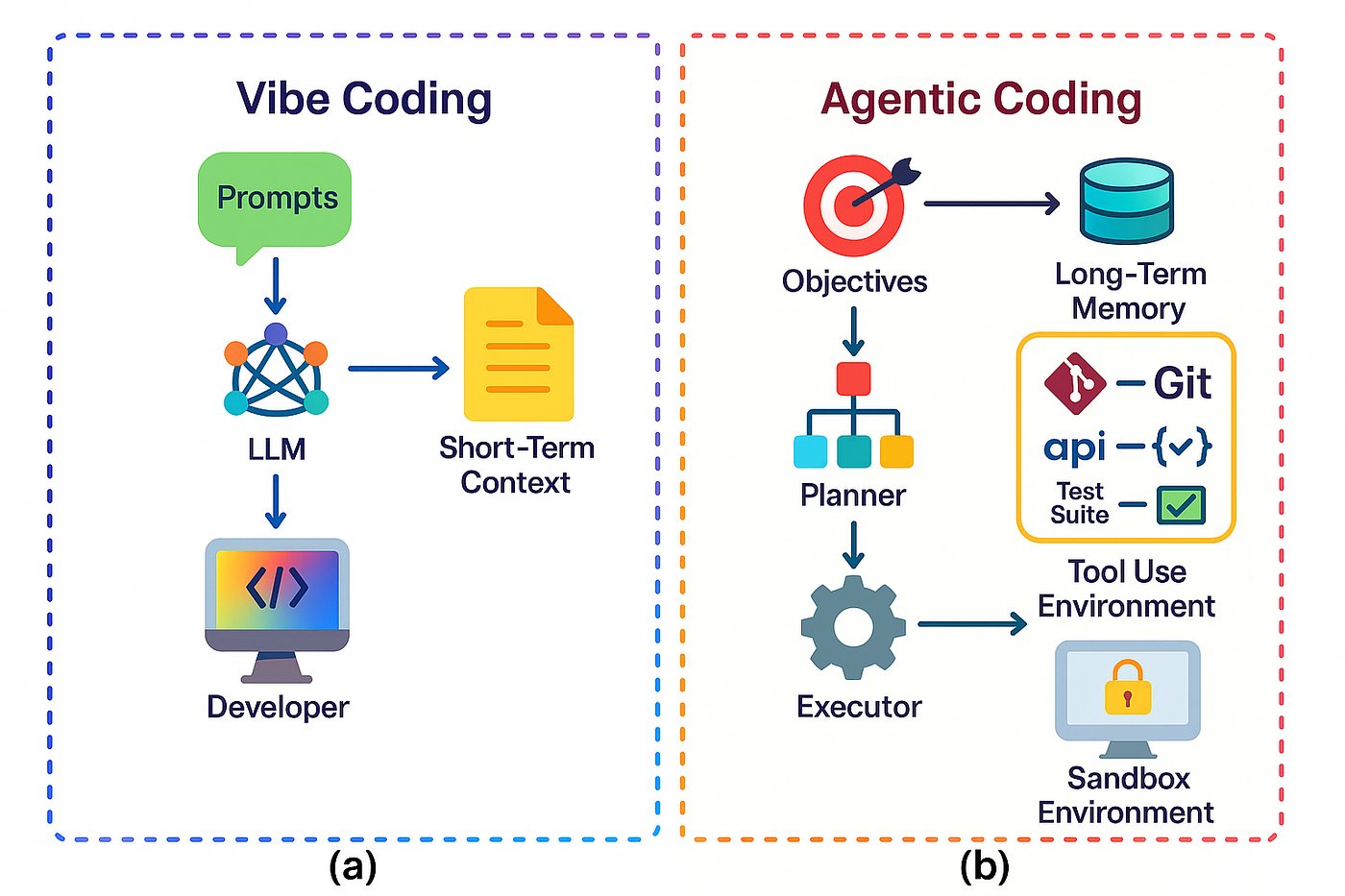
Агент — не автопилот, а ускоритель рутины. Он отлично справляется с типовыми задачами. Но там, где нужны архитектурные решения и понимание домена, контроль остаётся у человека.
Выигрывает не тот, у кого самый умный агент, а тот, кто умеет им управлять.
? Обзор статьи | ? Полная статья
4. Как превратить GitHub в память для ИИ-агента
Агенты умеют чинить баги, но часто действуют так, будто никогда раньше не видели похожих проблем.
В реальности разработчик идёт в GitHub: читает задачу, pull request, обсуждения и смотрит, как другие уже решали такую же ошибку.
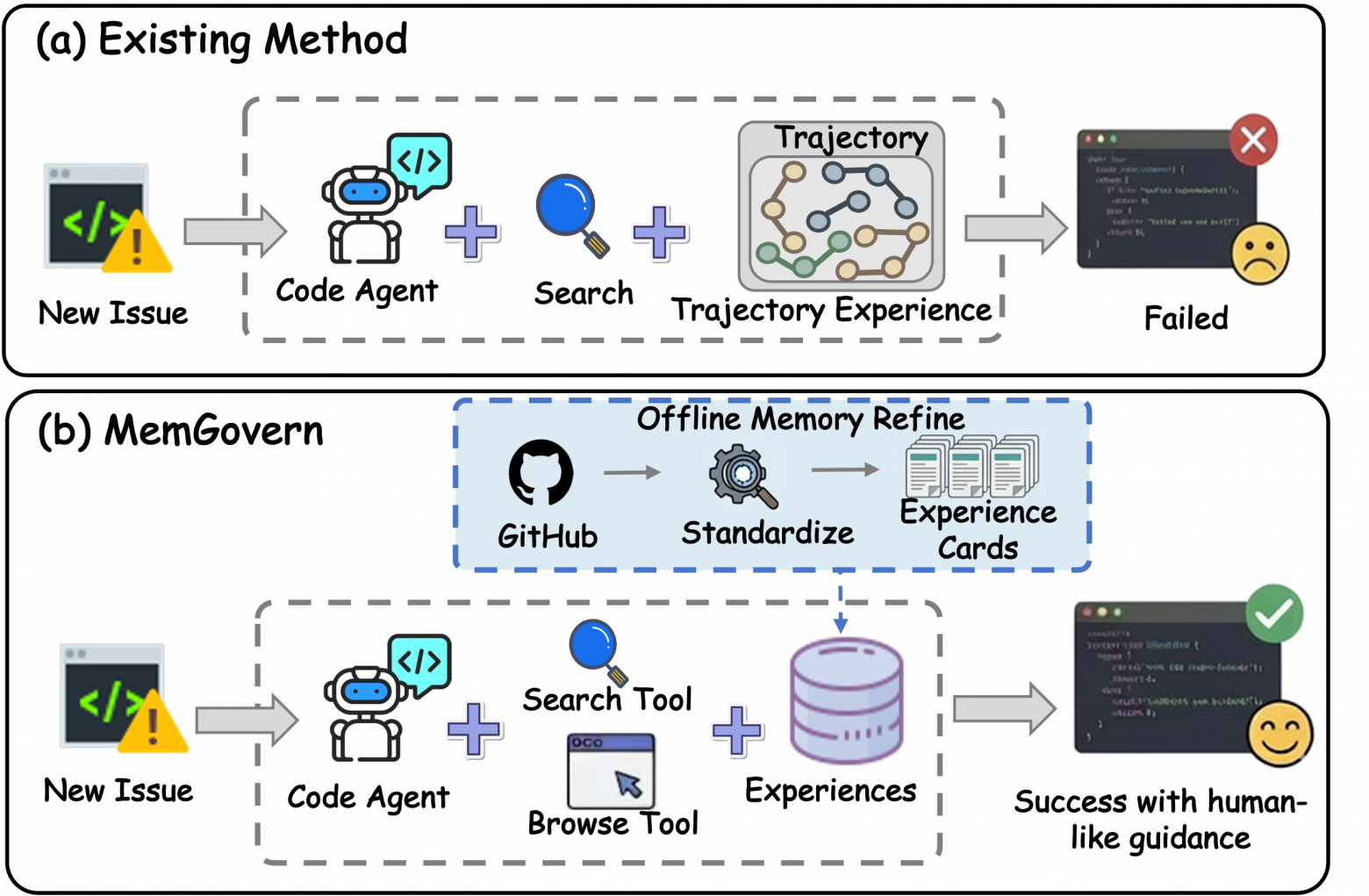
Исследователи предложили превратить GitHub в структурированную память. Реальные случаи исправлений преобразуются в «карточки опыта»: нормализованные симптомы, тип ошибки, сигналы, контекст — и отдельно логика решения, первопричина и стратегия фикса.
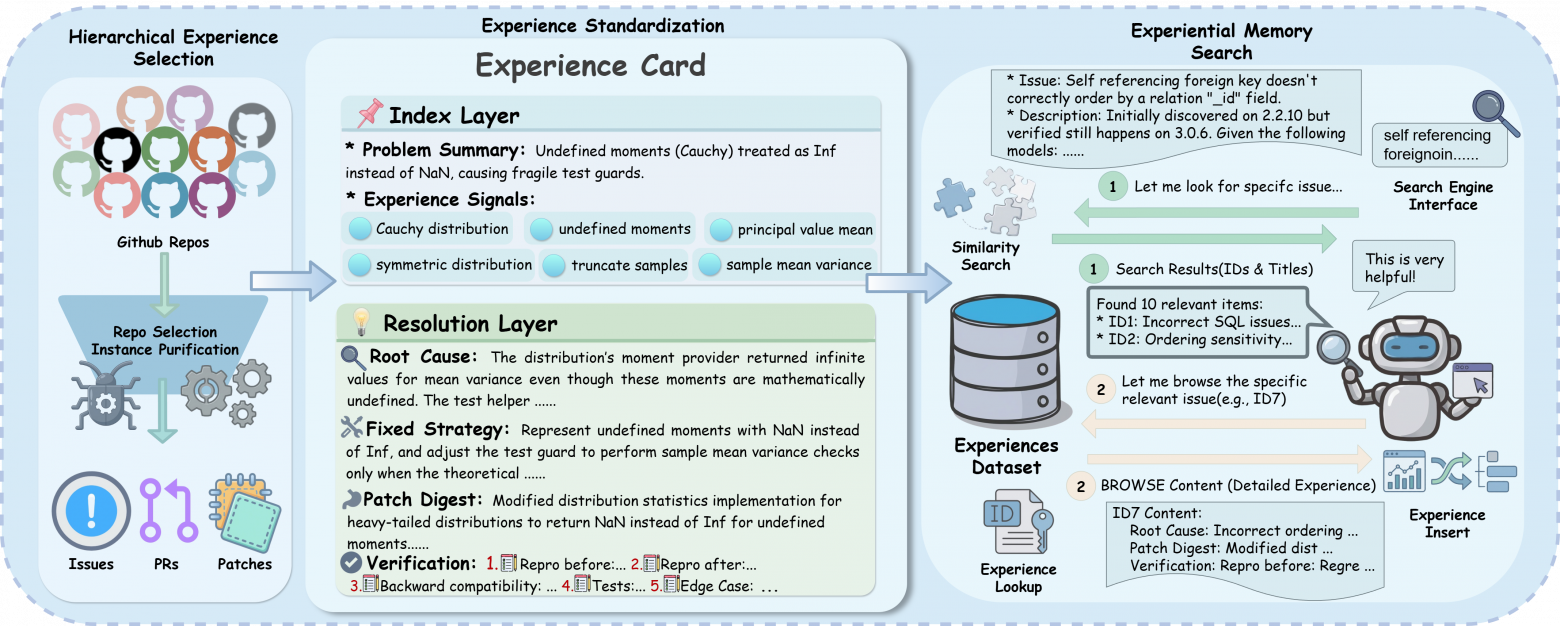
Это не сырой тред, а упакованный инженерный опыт.
Агент ищет итеративно, а не один раз как в обычном RAG. Он уточняет запросы и отбирает релевантные прецеденты, как живой инженер.

Результат — более +4% к решённым задачам на SWE-bench Verified.
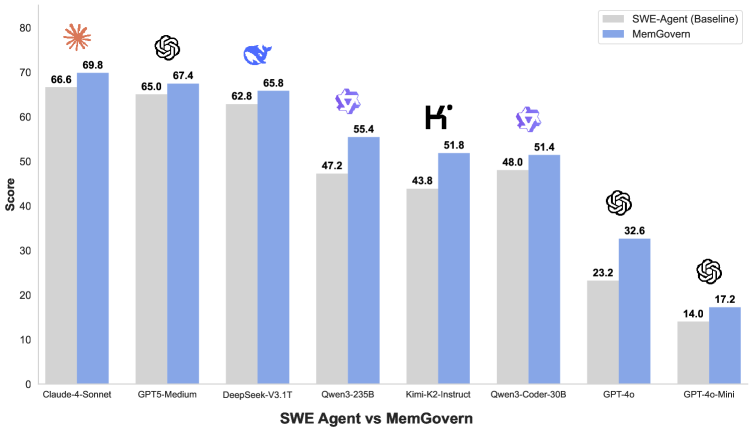
Главная идея — коллективная память становится инженерным инструментом.
? Обзор статьи | ? Полная статья | ? Код
5. Когда данных нет совсем, а учиться всё равно нужно: как ИИ сам придумывает задачи и сам себя проверяет

Можно ли учить ИИ без датасетов?
Absolute Zero Reasoner работает без внешних данных. Модель играет две роли: proposer создаёт задачу, solver её решает. Среда Python строго проверяет корректность. Если решение верно — начисляется награда.

Три режима обучения:
-
дедукция — вычислить результат;
-
абдукция — восстановить вход;
-
индукция — восстановить программу по примерам.
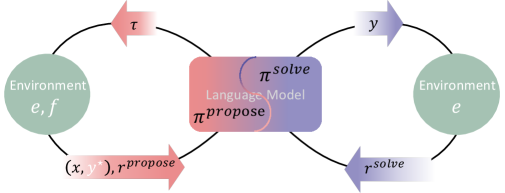
В результате — прирост 10–15% в математике и коде.
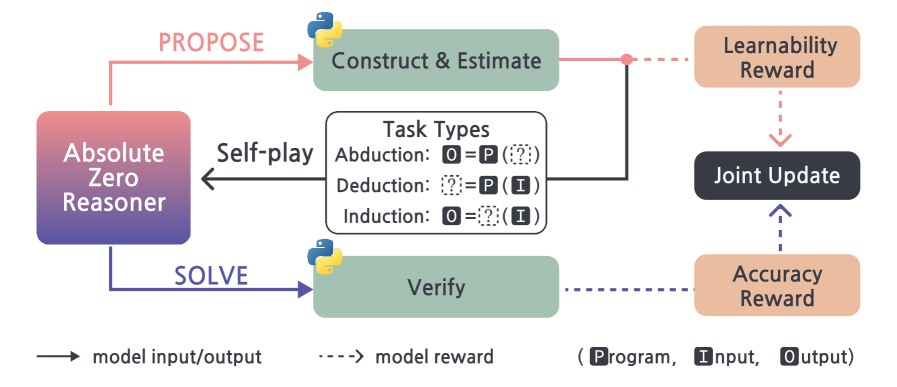
Главная идея: ресурс — не данные, а проверяемая среда. Модель учится не только решать, но и выбирать, чему учиться дальше.
? Обзор статьи | ? Полная статья
6. Как LLM помогают дата инженерам наводить порядок в «грязных» данных

Большая часть проблем аналитики — не в моделях, а в данных. Форматы скачут, значения противоречат друг другу, колонки называются по-разному.
LLM помогают в трёх задачах:
-
Очистка — стандартизация дат, исправление ошибок, заполнение пропусков.
-
Интеграция — сопоставление сущностей между источниками.
-
Обогащение — аннотация колонок, профилирование таблиц, связывание с внешними знаниями.
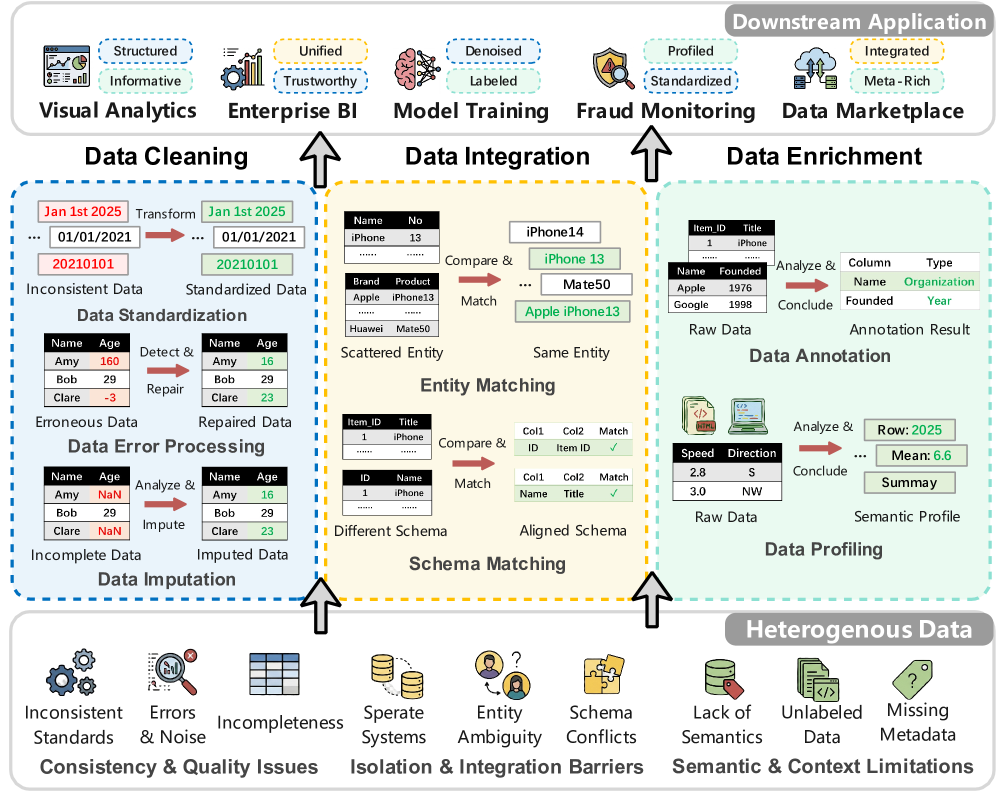
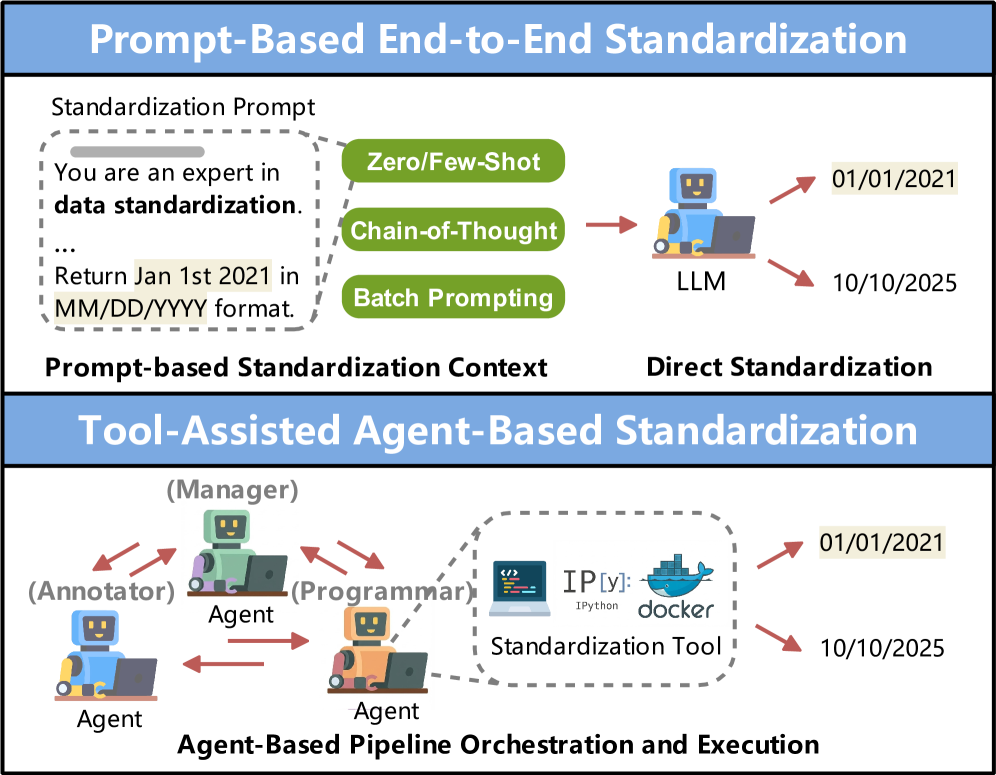
Используются промпты, генерация кода и агентные пайплайны с инструментами. Но остаются риски: стоимость, галлюцинации и сложность оценки качества.
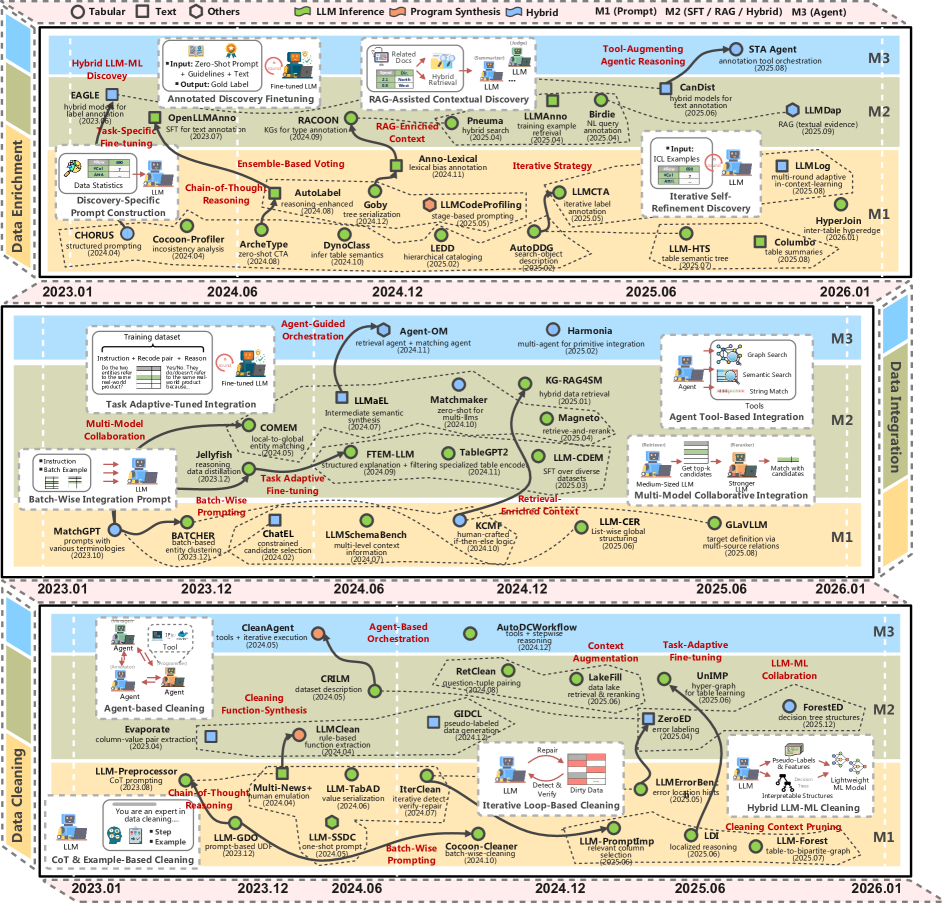
LLM не заменяют инженерную дисциплину. Они становятся слоем понимания смысла поверх сырых данных.
? Обзор статьи | ? Полная статья | ? Код
7. Когда агенту нужен дирижёр: AOrchestra и динамическая оркестрация LLM через субагентов

Когда задача тянется на десятки шагов, контекст раздувается, детали теряются, ошибки накапливаются. В мультиагентных системах добавляется ещё и лишняя «болтовня».
Решение — оркестратор. Он сам не действует в среде, а управляет: выбирает следующий шаг, передаёт контекст и создаёт субагента.
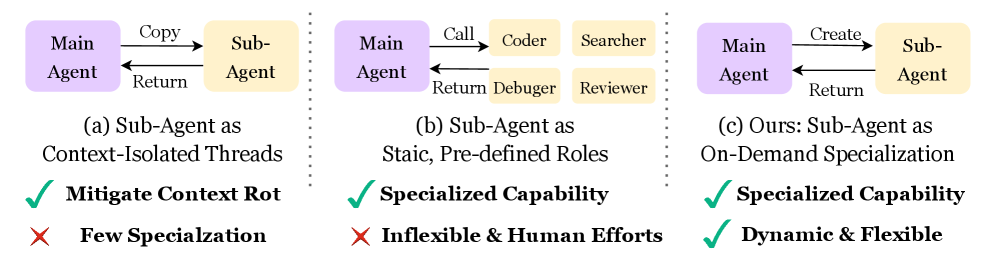
Каждый субагент динамически собирается из четырёх частей: инструкция, контекст, инструменты и модель. Под конкретную подзадачу — свой исполнитель.
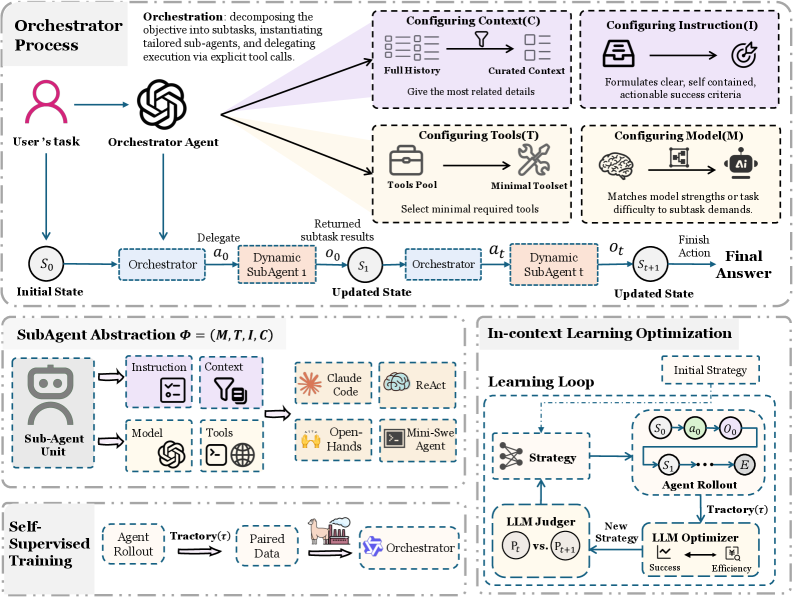
Это снижает информационный шум, изолирует контекст и позволяет выбирать модель под бюджет.
На бенчмарках GAIA, TerminalBench и SWE-bench Verified — до 16% относительного прироста.
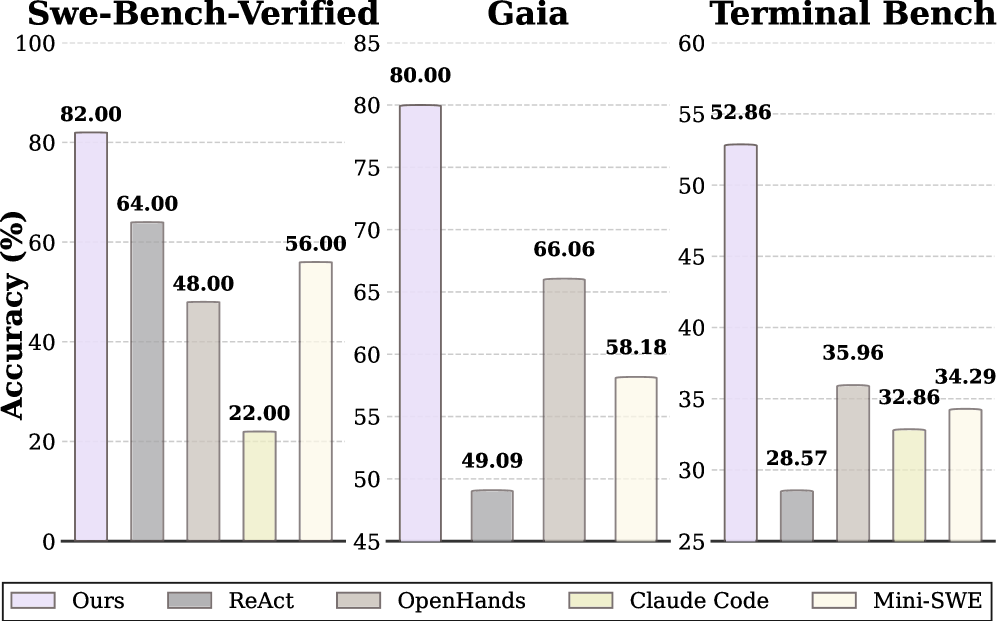
Агентам нужен не ещё один инструмент, а управляемая координация.
? Обзор статьи | ? Полная статья | ? Код
8. Общество мыслей: как LLM становятся сильнее, когда спорят сами с собой

Рассуждающие модели сильнее не потому, что думают дольше, а потому что думают структурированно.
Внутри них возникает «общество»: один голос предлагает идею, другой сомневается, третий проверяет. В их рассуждениях появляются вопросы и ответы, смена позиций, внутренний спор и примирение.
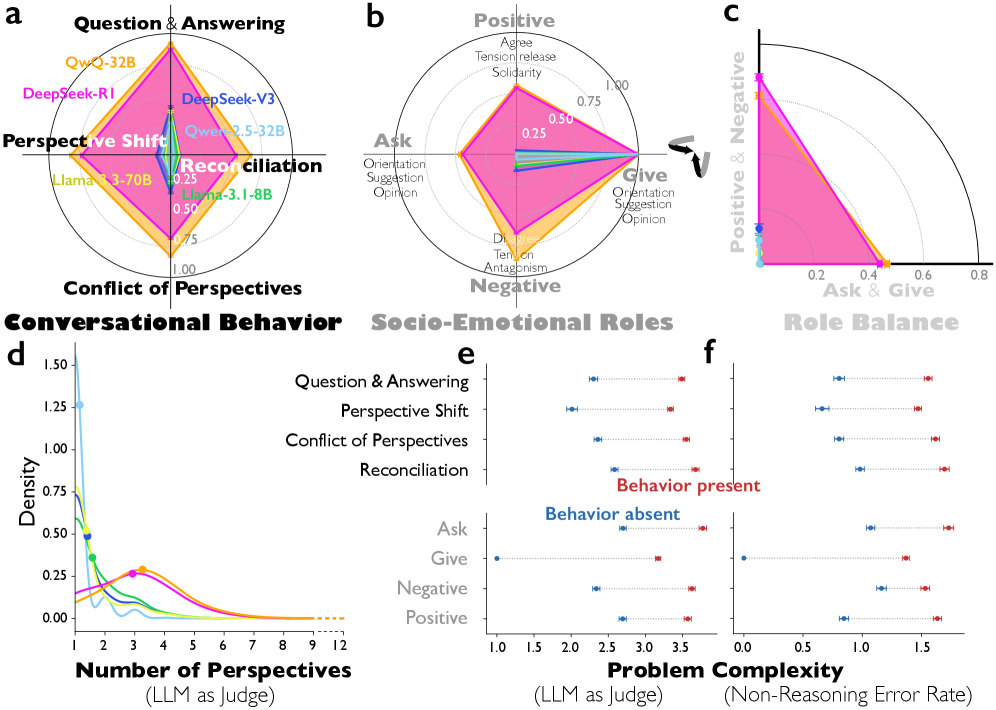
Когда исследователи усиливали в activation space признак смены реплики, точность на сложной арифметике почти удваивалась. Ослабляли — она падала.
Это не просто корреляция, а управляемый фактор
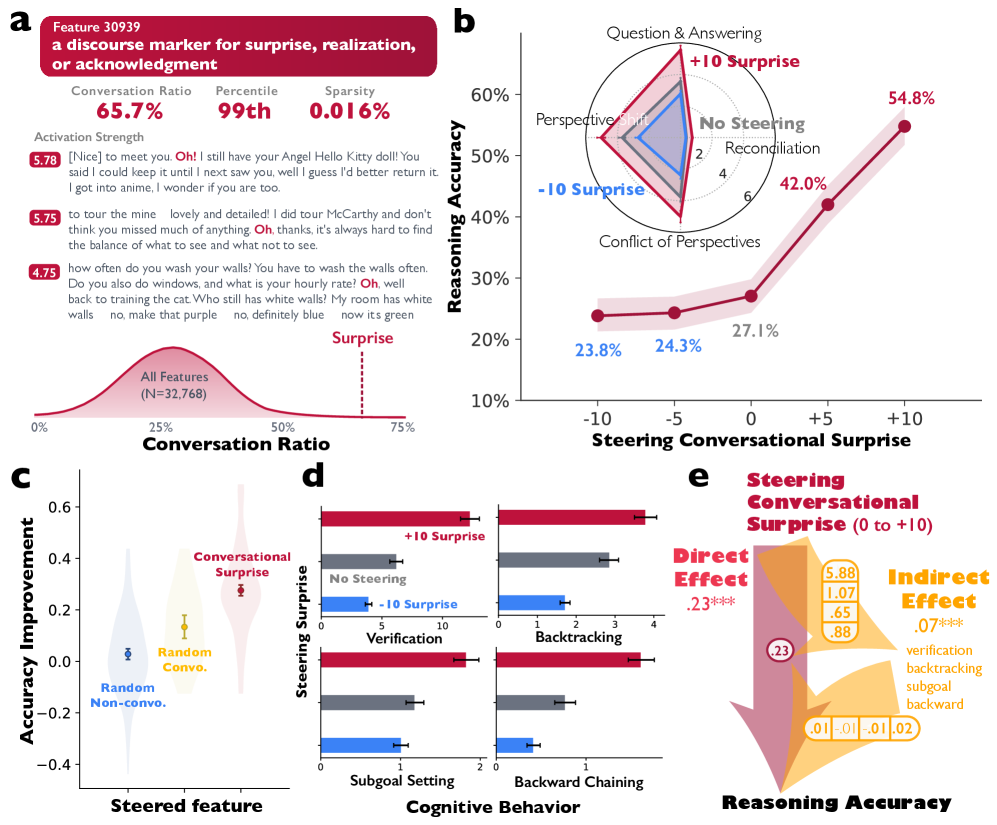
Даже при обучении с подкреплением модель постепенно начинает спорить сама с собой.
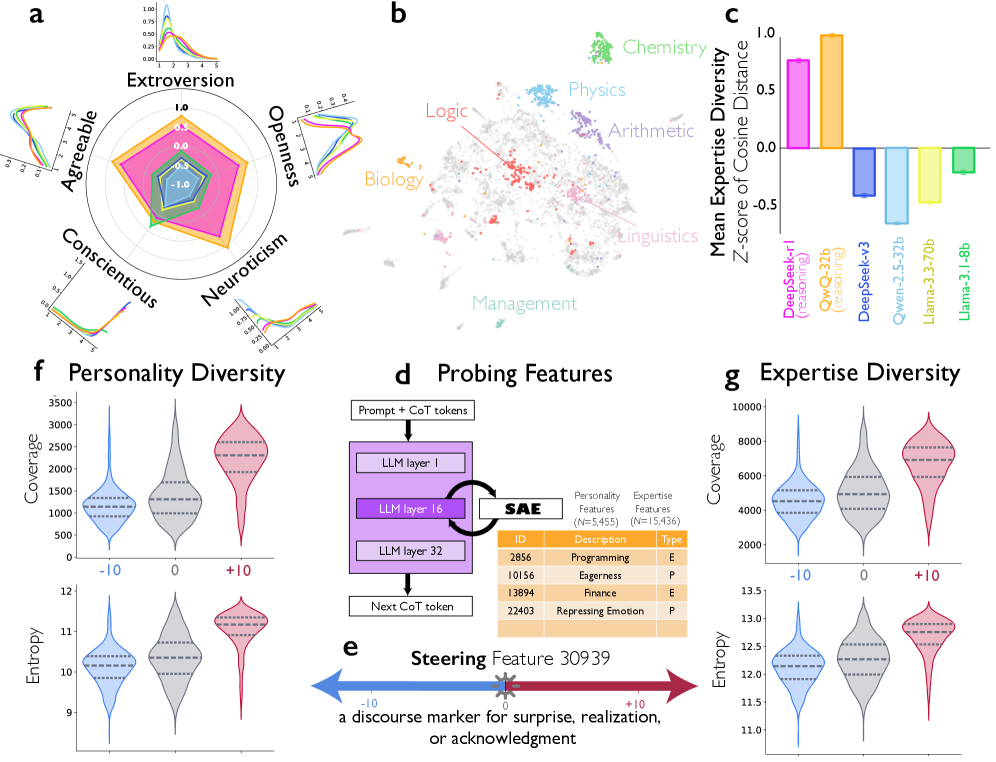
Модели становятся умнее, когда начинают мыслить как полноценная команда.
хорошо у них получается действовать в нём.
? Обзор статьи | ? Полная статья
9. RoboBrain: как робот понимает глубину 3D-сцены и учится самоконтролю

Роботу мало распознать объект на картинке. Нужно понять его положение в 3D, расстояние и траекторию движения, не задев окружающие объекты.
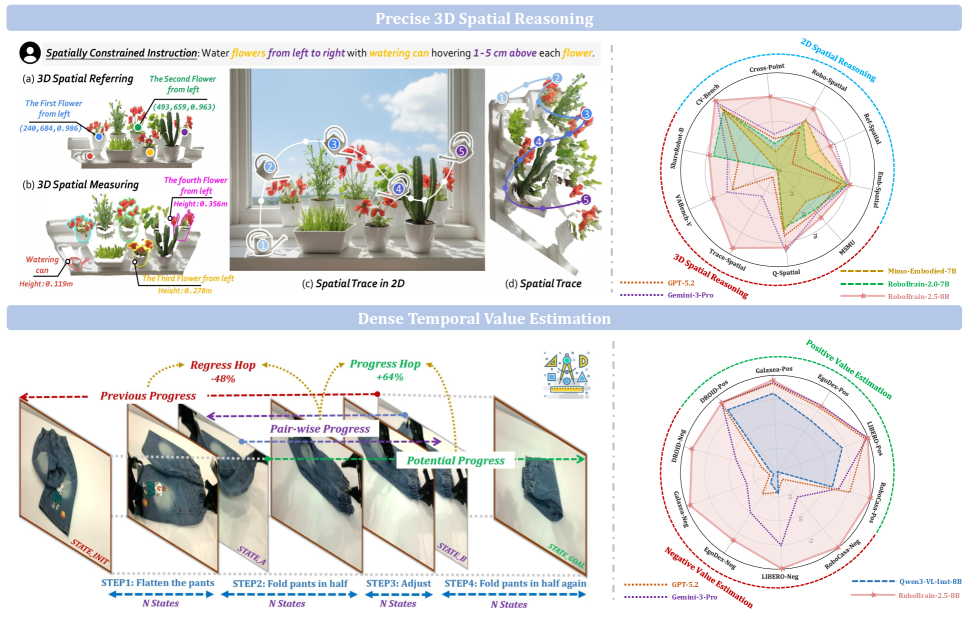
RoboBrain решает две задачи.
-
3D-мышление — предсказание координат и абсолютной глубины, построение траектории без столкновений.
-
Самоконтроль — оценка прогресса на каждом шаге. Продвигается ли задача или робот застрял? Если сигналы противоречат друг другу, система снижает доверие к оценке.

Это шаг к роботам, которые не только видят мир, но и понимают, насколько хорошо у них получается действовать в нём.
? Обзор статьи | ? Полная статья | ? Код
10. LLM — не тупик. Проблема AGI совсем в другом

Часто говорят: из next-token prediction нельзя построить AGI.
Но проблема не в LLM. Проблема в отсутствии слоя координации.

LLM — мощная Система-1. Без Системы-2, которая ставит цели, держит план, подключает инструменты, проверяет шаги и управляет памятью, модель скатывается к общим ответам.
Рассуждение становится устойчивым, когда закреплено внешними опорами — фактами, проверками, инструментами. Ниже порога такого якорения модель блуждает. Выше — входит в целевой режим.
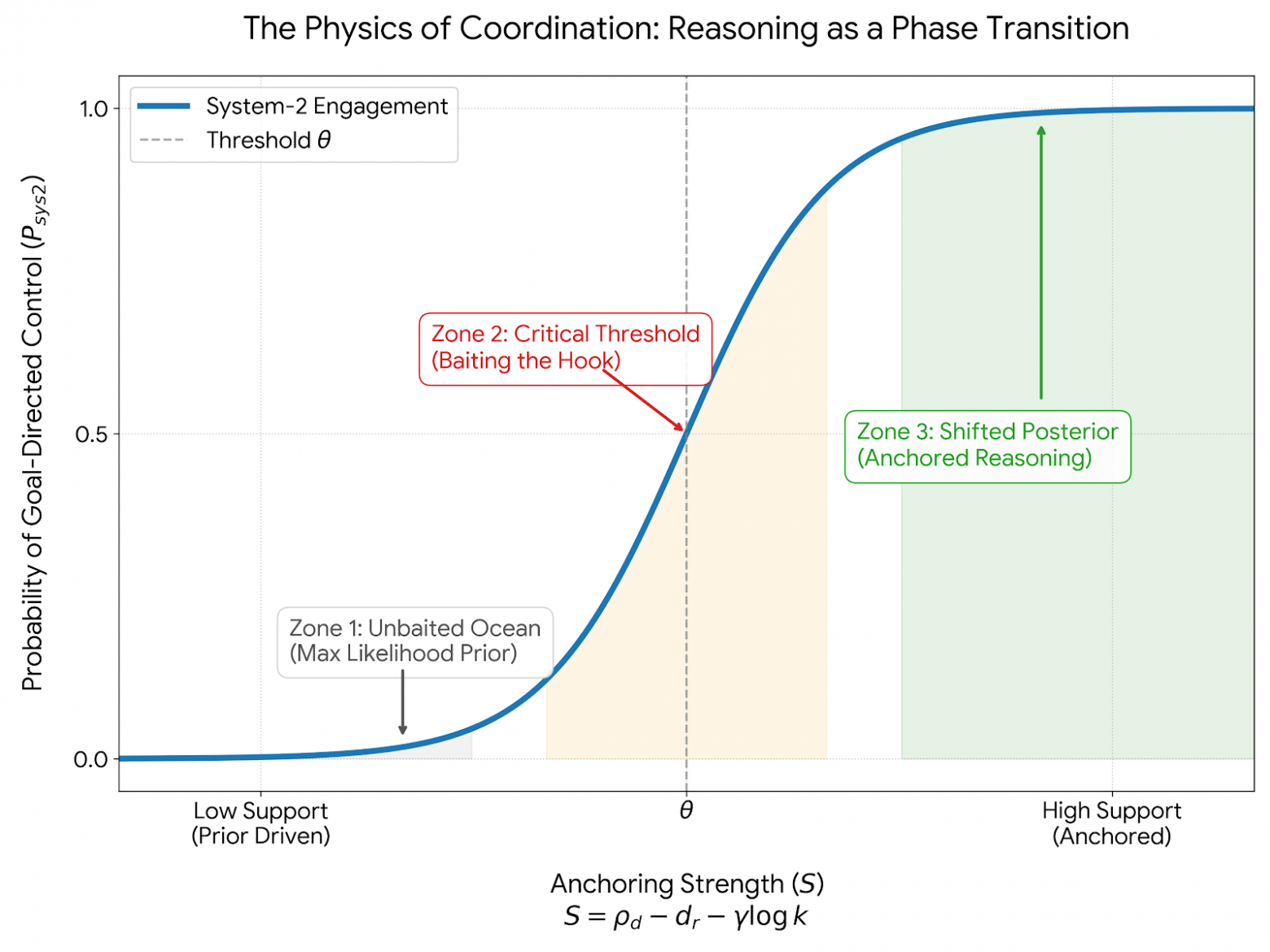
AGI здесь — это инженерия координации.
Общий интеллект рождается там, где система умеет управлять своими действиями в тексте, коде, 3D-среде и других модальностях — в едином пространстве смыслов.
Как писал Людвиг Витгенштейн: «Границы моего языка означают границы моего мира».
? Обзор статьи | ? Полная статья
Вывод
Симуляции становятся управляемыми в реальном времени. Агенты получают биографию и долгосрочную внутреннюю мотивацию. Они подключаются к коллективной памяти. Учатся сами выбирать траекторию обучения и оркестрируют десятки субагентов. Роботы начинают понимать глубину мира и собственный прогресс.
LLM — фундамент. Но интеллект рождается там, где появляется координация между памятью и действием, между планом и контролем, между языком и мультимодальным миром.
Поэтому AGI — это не внезапное пробуждение ИИ. Это инженерия систем, способных жить в причинно-следственной информационной среде.
И, возможно, это и есть настоящая тихая революция.
***
Если вам интересна тема ИИ, подписывайтесь на мой Telegram-канал — там я регулярно делюсь инсайтами по внедрению ИИ в бизнес, запуску ИИ-стартапов и объясняю, как работают все эти ИИ-чудеса.










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое