ITAMforLLM-1. Специализированные решения для ИИ-кластеров
Всем привет! Меня зовут Дмитрий Крупенин, я создаю внутренние и B2B ИТ-решения. Специализируюсь на цифровых продуктах для внутреннего использования в корпорациях.
Сейчас очень активно развиваются продукты и решения с использованием ИИ, однако не всегда удается легко посчитать экономику таких проектов, если мы говорим о необходимости развертывания этих решений внутри. Это может быть необходимо для крупных компаний (особенно банков и биг.теха), где законодательно нельзя отдавать персональные и корпоративные данные в облачные модели ЛЛМ. Хочется разобраться, как посчитать совокупную стоимость владения таким проектом, с учетом инфраструктуры, модели, данных для обучения и т.д. Так как это потребовало довольно объемного изучения предметной области - пришлось разбить материал на несколько статей:
-
Статья 1: "Специализированное оборудование". Исследовательская статья, как эволюционировали решения для ИИ и почему. LLM-1. Специализированные решения для ИИ-кластеров [Вы здесь]
-
Статья 2: "Архитектура ИИ-инфраструктуры: от GPU-кластеров до облачных решений" Комплексный обзор современных подходов к построению инфраструктуры для ИИ. LLM-2. Архитектура ИИ-инфраструктуры: от GPU-кластеров до облачных решений
-
Статья 3: "Total Cost of Ownership (TCO) для ИИ-проектов: полная методология расчета". Комплексная методология оценки совокупной стоимости владения ИИ-решениями. LLM-3. Total Cost of Ownership (TCO) для ИИ-проектов: полная методология расчета
-
Статья 4: "Аллокация затрат на ИИ: модели распределения и тарификации" Разработка справедливых моделей распределения затрат на ИИ-ресурсы. LLM-4. Аллокация затрат на ИИ-кластер: методология расчета
-
Статья 5: "Управление ИТ-активами в эпоху ИИ: эволюция ITAM". Адаптация практик управления ИТ-активами под специфику ИИ-решений.LLM-5. Управление ИТ-активами в эпоху ИИ: эволюция ITAM. Адаптация практик управления ИТ-активами под специфику ИИ-решений
Давайте разбираться вместе. В этой статье поймем откуда такой спрос на видеокарты (которые изначально делались для игр)и причем тут ИИ.
Эволюция требований к вычислительным ресурсам: от единичных GPU до суперкомпьютерных кластеров
Развитие инфраструктуры для искусственного интеллекта демонстрирует беспрецедентную динамику роста вычислительных мощностей, когда требования к ресурсам увеличиваются экспоненциально с каждым поколением моделей. Эволюция от единичных графических процессоров к масштабным суперкомпьютерным кластерам отражает фундаментальные изменения в архитектурных подходах, методологиях распределенного обучения и инженерных решениях, необходимых для эффективной работы современных систем искусственного интеллекта. Данная статья представляет детальный анализ ключевых этапов этой трансформации, рассматривая технологические прорывы, архитектурные решения и практические вызовы, с которыми сталкиваются инфраструктурные архитекторы при проектировании систем следующего поколения.
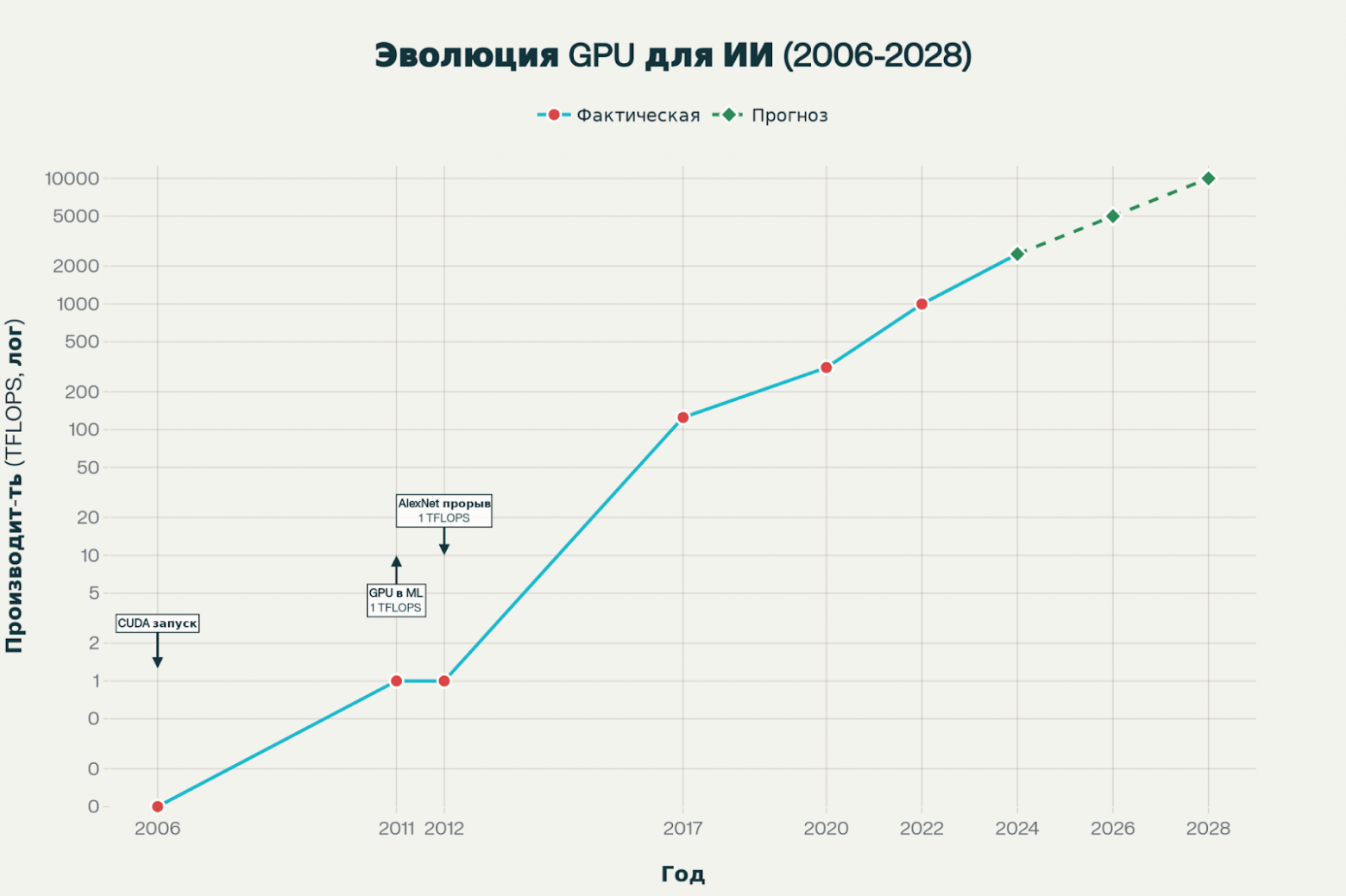
Зарождение эпохи GPU в машинном обучении (2006-2012)
Революция в применении графических процессоров для задач искусственного интеллекта началась с выпуска NVIDIA CUDA в 2006 году, что стало переломным моментом в истории вычислительных технологий. CUDA предоставила разработчикам возможность писать параллельный код для GPU, открыв эру программируемых вычислений общего назначения на графических процессорах. Эта инновация позволила исследователям использовать тысячи ядер GPU для одновременной обработки данных, что оказалось идеальным решением для матричных операций, лежащих в основе нейронных сетей.
При чем тут видеокарты вообще спросите вы? Параллельная вычислительная мощность, которая когда-то изменила игровые графику, привлекла внимание исследователей. Они осознали, что графические процессоры способны раскрыть огромный вычислительный потенциал и в сфере искусственного интеллекта, открывая возможности далеко за пределами игр. Глубокое обучение - программная модель, основанная на миллиардах «нейронов» и триллионах связей, - ��ребует колоссальных вычислительных ресурсов. Обычные процессоры (CPU), изначально предназначенные для последовательных операций, не могли эффективно справляться с такой нагрузкой. Зато графические процессоры (GPU) с их архитектурой массового параллелизма оказались идеально подходящим инструментом для этой задачи.
Первые массовые эксперименты по использованию GPU для машинного обучения начались около 2009-2010 годов, когда появились первые библиотеки, связывающие нейросетевые пакеты с графическими процессорами. Однако подлинный прорыв произошел в 2012 году, когда Алекс Крижевский использовал всего две видеокарты NVIDIA GeForce для обучения глубокой сверточной нейронной сети AlexNet. Эта модель одержала сокрушительную победу в конкурсе ImageNet, продемонстрировав улучшение точности на 9,4% по сравнению с предыдущими лучшими результатами. Успех AlexNet запустил революцию глубокого обучения и доказал, что GPU могут обеспечить вычислительную мощность, ранее доступную только суперкомпьютерам.
На этом этапе типичная исследовательская установка включала от одного до восьми GPU, что было достаточно для обучения моделей с несколькими миллионами параметров на относительно небольших датасетах. Энергопотребление таких систем составляло менее 50 киловатт, а сложность инфраструктуры оставалась управляемой для небольших исследовательских групп.
Становление распределенного обучения (2015-2018)
К 2015 году AI достиг сверхчеловеческого уровня восприятия в задачах распознавания изображений и понимания речи, причем все эти достижения были реализованы на глубоких нейронных се��ях, работающих на GPU. Однако рост сложности моделей и объемов данных быстро превысил возможности отдельных графических процессоров, что потребовало разработки методологий распределенного обучения.
Распределенное обучение решает фундаментальную проблему: как распределить возрастающую вычислительную нагрузку по множеству аппаратных ресурсов, сохраняя при этом эффективность обучения, численную стабильность и разумное время выполнения. Основными стратегиями стали параллелизм по данным (data parallelism) и параллелизм по модели (model parallelism). При параллелизме по данным обучающие данные разделяются на пакеты, обрабатываемые одновременно на нескольких GPU, каждый из которых хранит полную копию модели. После вычисления градиентов на каждом устройстве они синхронизируются, и параметры модели обновляются идентично на всех репликах.
В этот период типичные коммерческие кластеры насчитывали от 100 до 500 GPU, что позволяло обучать модели уровня BERT и первых версий Transformer с сотнями миллионов параметров. Появление архитектуры Volta в 2017 году с GPU V100 и специализированными Tensor Core стало значительным шагом вперед. Tensor Core были специально разработаны для ускорения операций глубокого обучения и обеспечивали 125 терафлопс производительности в формате FP16. Это позволило значительно ускорить обучение нейронных сетей и открыло путь к более крупным моделям.
-
Модель BERT (Bidirectional Encoder Representations from Transformers) - это языковая модель на основе архитектуры трансформер, разработанная Google для обработки естественного языка. Ключевая особенность BERT - двунаправленное обучение, которое позволяет учитывать контекст слова одновременно слева и справа от него. Это даёт модели более глубокое понимание смысла текстов по сравнению с однонаправленными моделями.
-
Transformer - это архитектура искусственного интеллекта, основанная на механизме внимания (attention). Модель Transformer позволяет последовательно анализировать и генерировать тексты, обрабатывать большие массивы данных, и стала основой для современных языковых моделей, например GPT, BERT и других.
-
Tensor Core - это специальный вычислительный блок в графических процессорах NVIDIA, созданный для ускорения операций над тензорами, особенно при обучении и работе с нейронными сетями. Tensor Core оптимизированы для матричных вычислений, что позволяет значительно увеличить скорость задач глубокого обучения.
-
Терафлопс - это единица измерения вычислительной мощности, равная одному триллиону операций с плавающей точкой в секунду. Чем больше терафлопс у устройства, тем больше оно способно обрабатывать сложных вычислений параллельно.
-
Формат FP16 (half precision) - это 16-битный формат чисел с плавающей запятой, который используется для представления чисел с меньшей разрядностью по сравнению с более распространённым 32-битным (FP32). FP16 позволяет значительно ускорить вычисления и снизить объём используемой памяти, при этом сохраняя достаточную точность для многих задач, особенно в машинном обучении и нейросетях.
Эра массового масштабирования (2020-2022)
Период 2020-2022 годов ознаменовался взрывным ростом размеров языковых моделей и соответствующим увеличением масштабов вычислительной инфраструктуры. Выпуск архитектуры Ampere с GPU A100 в 2020 году принес 312 терафлопс производительности в формате FP16 и существенно улучшил энергоэффективность. A100 стал основным рабочим инструментом для обучения крупномасштабных моделей трансформеров следующего поколения.
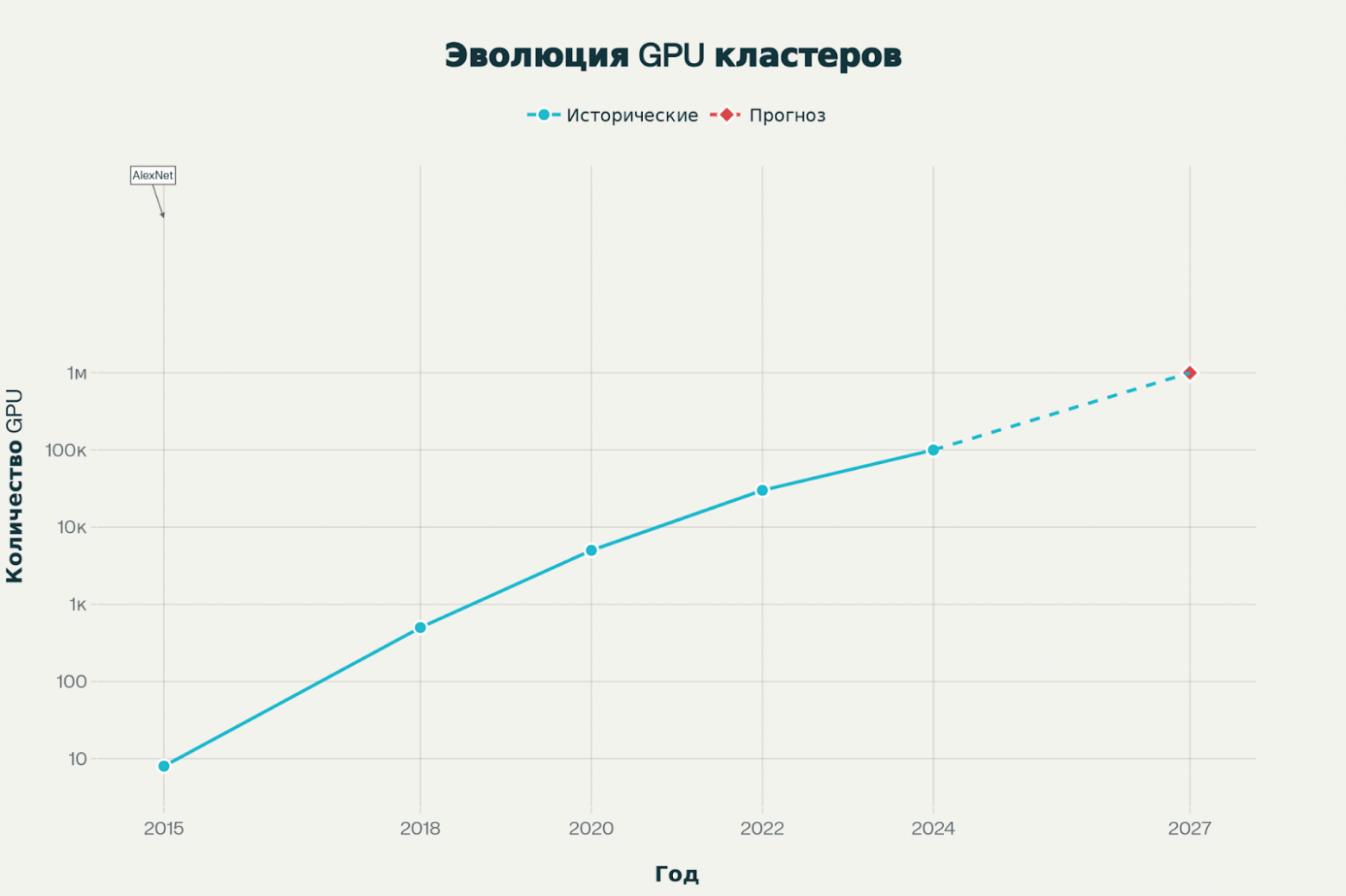
Обучение GPT-3 со 175 миллиардами параметров потребовало кластера из примерно 10,000 GPU и заняло несколько недель при стоимости в несколько миллионов долларов. Модель была обучена на датасете объемом 570 ГБ текстовых данных, что потребовало не только массивных вычислительных ресурсов, но и тщательно спроектированной распределенной архитектуры. На этом этапе стали критически важными гибридные подходы, сочетающие параллелизм по данным и модели для эффективного использования ресурсов.
Архитектура Hopper с GPU H100, представленная в 2022 году, совершила качественный скачок в производительности, обеспечивая 1000 терафлопс в формате FP8. Это 30-кратное ускорение по сравнению с предыдущим поколением для больших языковых моделей. H100 стал доминирующим решением для обучения самых продвинутых моделей, включая GPT-4, для которого потребовалось порядка 25,000-30,000 GPU.
Ключевым техническим вызовом стало управление коммуникационными издержками в кластерах такого масштаба. Появление NVLink 4.0 обеспечило агрегированную пропускную способность около 900 ГБ/сек на GPU, что позволило эффективно синхронизировать градиенты между тысячами устройств. (NVLink 4.0 - это современная версия высокоскоростного интерфейса, созданного NVIDIA для объединения нескольких графических процессоров в суперкомпьютерах и серверных системах. NVLink 4 позволяет напрямую соединять GPU с максимальной пропускной способностью до 900 Гбит/с (или 112,5 ГБ/с) на один ускоритель.) Энергопотребление таких кластеров достигло 130-150 мегаватт, что потребовало специализированных центров обработки данных с продвинутыми системами охлаждения.
Эпоха суперкластеров и мегамасштабных систем (2024-настоящее время)
Современный этап характеризуется развертыванием суперкластеров с более чем 100,000 GPU, что представляет собой качественно новый уровень инфраструктурной сложности. Суперкомпьютер Colossus компании xAI с более чем 100,000 GPU H100 стал одной из крупнейших AI-систем в мире. Этот кластер потребляет 280 мегаватт энергии и требует использования мобильных генераторов, поскольку локальная электросеть не обладает достаточной мощностью для такого объема оборудования.
Архитектура Blackwell с GPU B200, представленная в 2024 году, обеспечивает 2500 терафлопс производительности в формате FP4 для инференса, что в 2.5 раза превосходит H100. Система GB200 NVL72 объединяет 72 стойки с 144 GPU-чиплетами и обеспечивает 1100 петафлопс производительности FP4 и 360 петафлопс производительности FP8 для обучения. NVLink 5.0 удвоил пропускную способность до 1.8 ТБ/сек, обеспечив эффективную коммуникац��ю в массивных кластерах.
Критические технические вызовы на этом уровне масштаба включают обеспечение стабильности оборудования, управление отказами системы и поддержание стабильности обучения модели. Обучение в течение недель на кластере из более чем 100 узлов неизбежно сталкивается с аппаратными или системными сбоями. Автоматическое восстановление после сбоев и эффективное сохранение контрольных точек стали критически важными компонентами архитектуры. Эмпирически доказано, что с автоматическим восстановлением эффективная утилизация вычислительных часов достигает 98.81% по сравнению с 77.83% при ручном восстановлении.
Архитектурные компоненты современных GPU-кластеров
Теперь давайте посмотрим из чего состоит современный кластер. Что-то похожее (но меньшего масштаба) мы будем строить в крупном энтерпрайзе для решения бизнес-задач.
Современный GPU-кластер представляет собой сложную многоуровневую систему, где каждый компонент критически важен для общей производительности. Базовым элементом является GPU-узел, включающий один или несколько GPU, CPU, память и хранилище. Эти узлы взаимодействуют через высокоскоростные сетевые соединения, обеспечивающие эффективное распределение данных и обработку.
Ключевые компоненты включают сами GPU, обрабатывающие вычислительную нагрузку, CPU для управления системными операциями и координации задач, высокопропускную память (HBM) и оптимизированные интерконнекты для быстрой передачи данных. Высокоскоростные интерконнекты, такие как NVLink, InfiniBand или специализированные Ethernet-решения, обеспечивают быструю передачу данных между узлами. Программное обеспечение управления кластером, включая Kubernetes, Slurm или NVIDIA GPU Cloud, оптимизирует распределение ресурсов и планирование рабочих нагрузок.
Критическим аспектом является архитектура хранения данных. Традиционные файловые системы и устаревшие архитектуры хранения не были созданы для той интенсивности данных или уровней параллелизма, которые требуют AI-рабочие нагрузки. В AI-конвейерах GPU-кластеры часто простаивают в ожидании поступления данных из-за задержек метаданных в устаревших NAS-архитектурах, разрозненных датасетов в облачных и on-premise окружениях, недостаточного параллелизма в доступе к неструктурированным данным и негибких уровней хранения.
Будущее: путь к мегакластерам (2026-2028)
До недавнего времени практический лимит для GPU-кластеров считался около 30,000 GPU из-за ограничений сетевой пропускной способности, задержек коммуникации и распределения энергии. Однако последние прорывы, такие как GPU H100 от NVIDIA и инновационная технология интерконнекта NVLink, позволили достичь бОльшей масштабируемости. Эти инновации в сочетании с улучшенными системами охлаждения и энергоэффективными решениями прокладывают путь к кластерам, способным поддерживать колоссальные вычислительные требования генеративного AI. Дорожная карта NVIDIA предвещает дальнейшее масштабирование вычислительной инфраструктуры.
Требования к энергопотреблению передовых AI-суперкомпьютеров удваиваются каждые 13 месяцев. В январе 2019 года Summit в Oak Ridge National Lab имел наивысшую мощность среди всех AI-суперкомпьютеров - 13 МВт, сегодня Colossus от xAI использует 280 МВт, что более чем в 20 раз больше. В будущем мы можем увидеть обучение передовых моделей на географически распределенных суперкомпьютерах для смягчения трудностей доставки огромных объемов энергии в одно место, подобно установке обучения Gemini 1.0.
Практические рекомендации
При проектировании современной AI-инфраструктуры критически важно тщательно продумать стратегию масштабирования с учетом текущих и будущих потребностей. Необходимо оценить, требуется ли модульный подход с возможностью постепенного расширения или сразу необходима крупномасштабная система. Гибридные архитектуры, комбинирующие облачные и on-premise ресурсы, часто обеспечивают оптимальный баланс между гибкостью и контролем затрат.
Оптимизация управления данными становится столь же важной, как и вычислительная мощность. GPU-кластер не может вычислить то, что не может получить - задержки в доступности данных снижают коэффициенты утилизации и замедляют получение результатов. Архитектурный фокус должен расширяться за пределы плотности вычислений, включая гибкость данных, локальность и выравнивание производительности с возможностями пропускной способности GPU.
Эволюция от единичных GPU к суперкомпьютерным кластерам с миллионами процессоров отражает фундаментальную трансформацию в подходах к проектированию AI-инфраструктуры. Успешная реализация требует глубокого понимания не только аппаратных возможностей, но и сложных взаимодействий между распределенными алгоритмами обучения, сетевой архитектурой, управлением данными и энергетической инфраструктурой. По мере того как индустрия движется к еще более масштабным системам, способность эффективно проектировать и управлять этой сложностью становится ключевым конкурентным преимуществом для организаций, стремящихся лидировать в эпоху искусственного интеллекта.
Специализированное оборудование: GPU (H100, H200, B200), TPU и нейроморфные процессоры
Революция в области искусственного интеллекта движется не только алгоритмическими инновациями, но и стремительным развитием специализированного аппаратного обеспечения, способного эффективно обрабатывать массивные вычислительные нагрузки современных AI-систем. Современный ландшафт ускорителей для искусственного интеллекта характеризуется разнообразием архитектурных подходов, каждый из которых оптимизирован для специфических типов рабочих нагрузок и предлагает уникальное сочетание производительности, энергоэффективности и экономических характеристик. Данная глава представляет комплексный анализ ведущих классов специализированного оборудования для AI, включая графические процессоры последних поколений от NVIDIA, тензорные процессоры Google и перспективные нейроморфные архитектуры.
NVIDIA GPU: доминирующая платформа для AI
Графические процессоры NVIDIA захватили доминирующее положение на рынке AI-ускорителей благодаря сочетанию высокой производительности, широкой экосистемной поддержки и непрерывных архитектурных инноваций. Эволюция от поколения Ampere к Hopper и далее к Blackwell демонстрирует экспоненциальный рост вычислительных возможностей при одновременном улучшении энергоэффективности и расширении архитектурных возможностей.
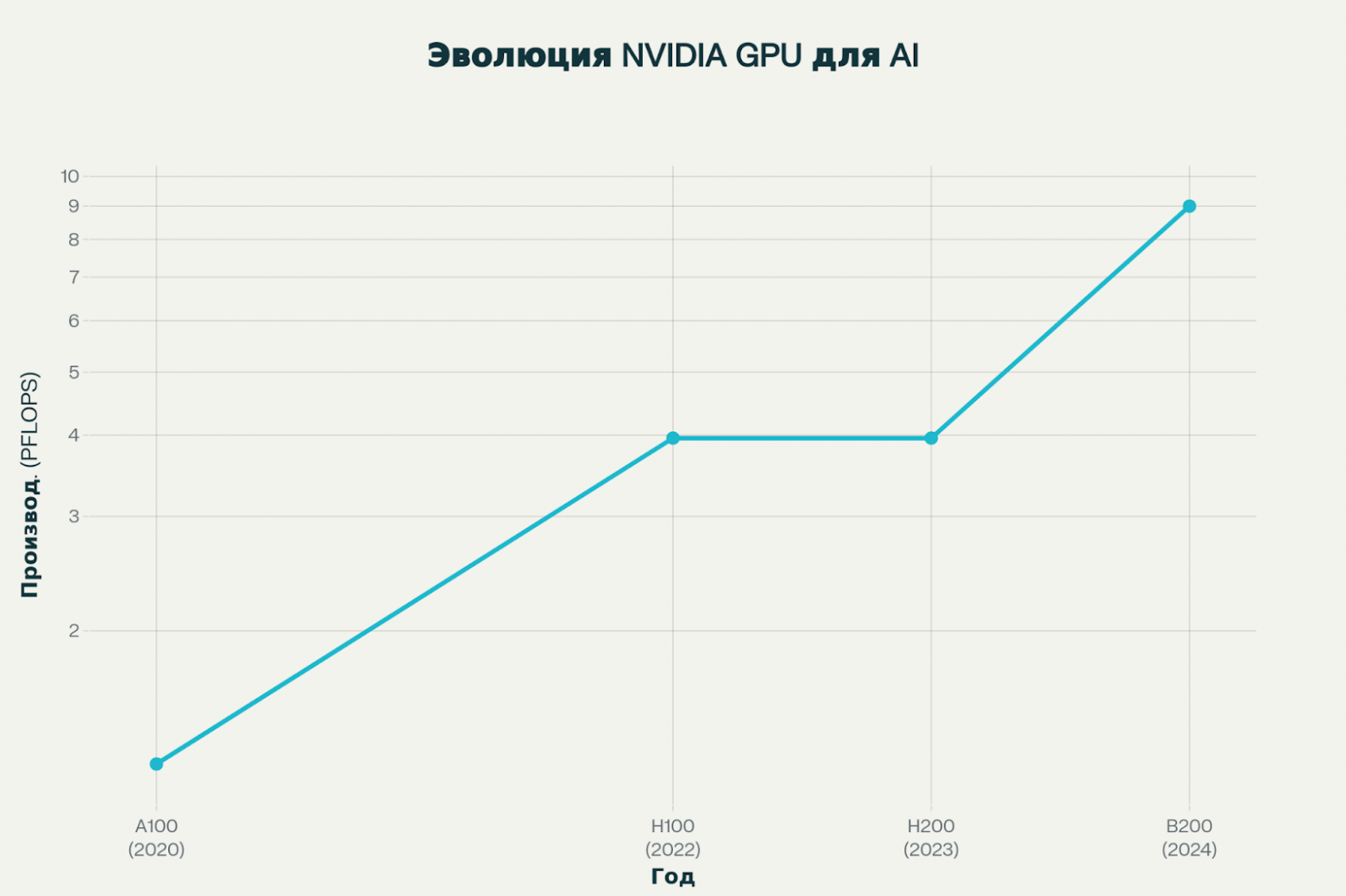
A100: фундамент современного AI
NVIDIA A100, представленная в 2020 году на архитектуре Ampere, заложила фундамент для обучения крупномасштабных языковых моделей и остается широко используемой в производственных системах. GPU обеспечивает 624 терафлопс производительности FP16 и 1248 терафлопс INT8, что было революционным на момент выпуска. Карта оснащена 80 ГБ памяти HBM2e с пропускной способностью 2 ТБ/с и потребляет 400 Вт энергии.
Ключевой инновацией A100 стали тензорные ядра третьего поколения, специально оптимизированные для операций глубокого обучения. Технология Multi-Instance GPU (MIG) позволяет разделить один физический GPU на два - семь независимых инстансов, каждый с выделенными вычислительными ресурсами и памятью. Это критически важно для облачных провайдеров и организаций, стремящихся максимизировать утилизацию дорогостоящего оборудования.
H100: прорыв архитектуры Hopper
NVIDIA H100, выпущенная в 2022 году на архитектуре Hopper, представила значительный скачок в производительности AI-рабочих нагрузок. Карта обеспечивает 1979 терафлопс для FP16 и впечатляющие 3958 терафлопс для нового формата FP8. Тензорные ядра четвертого поколения внедрили поддержку FP8 и формата TF32, обеспечивающих оптимальный баланс между производитель��остью и численной точностью для обучения больших языковых моделей.
Память H100 составляет 80 ГБ HBM3 с пропускной способностью 3.35 ТБ/с, что на 67% выше чем у A100. Энергопотребление увеличилось до 700 Вт, отражая значительный рост вычислительных возможностей. Критическим улучшением стал NVLink 4го поколения, обеспечивающий 900 ГБ/с пропускной способности для межпроцессорной коммуникации, что критически важно для эффективного распределенного обучения.
H100 стал основным рабочим инструментом для обучения современных крупномасштабных моделей. Обучение GPT-4 потребовало примерно 25,000-30,000 карт H100, работающих в тесной координации. Карта обеспечивает 30-кратное ускорение по сравнению с предыдущим поколением для задач обучения больших языковых моделей.
H200: эволюция с акцентом на память
H200, представленная в 2023 году, сохраняет архитектуру Hopper, но фокусируется на драматическом увеличении емкости и скорости памяти. Карта оснащена 141 ГБ памяти HBM3e с пропускной способностью 4.8 ТБ/с, что на 76% больше емкости и на 43% выше пропускной способности по сравнению с H100. Вычислительная производительность остается идентичной H100, но увеличенная память позволяет размещать значительно более крупные модели на одном GPU.
Примечательно, что H200 сохраняет энергопотребление на уровне 700 Вт, идентичном H100. Это означает существенное улучшение энергоэффективности на единицу доступной памяти. Технология Multi-Instance GPU теперь поддерживает до семи инстансов по 18 ГБ каждый, по сравнению с 10 ГБ у H100.
H200 особенно эффективна для задач инференса больших языковых моделей с длинным контекстом. NVIDIA заявляет о возможности до 2x раз ускорения инференса LLM по сравнению с H100 благодаря улучшенной пропускной способности памяти. Для моделей с параметрами 100B+ и контекстными окнами в сотни тысяч токенов H200 становится предпочтительным выбором.
B200: революция Blackwell
NVIDIA B200, представленная в 2024 году на новой архитектуре Blackwell, представляет собой квантовый скачок в производительности AI-ускорителей. Карта оснащена 208 миллиардами транзисторов и обеспечивает ошеломляющие 9 петафлопс производительности FP8 и 18 петафлопс в разреженном режиме. Это в 2.3 раза превосходит производительность H100 для обучения и до 15 раз для задач инференса.
Память B200 составляет 192 ГБ HBM3e с пропускной способностью 8 ТБ/с - в 2.4 раза больше емкости и в 2.4 раза выше пропускной способности чем у H100. Тензорные ядра пятого поколения внедрили поддержку сверхнизких форматов точности FP4 и FP6, критически важных для эффективного инференса. Dual transformer engines позволяют параллельно обрабатывать различные компоненты трансформерных архитектур.
NVLink 5 удваивает пропускную способность до 1.8 ТБ/с на узел, обеспечивая эффективную коммуникацию в масштабных кластерах. Энергопотребление увеличилось до 1000 Вт, что отражает массивное увеличение вычислительных возможностей. Система GB200 NVL72 объединяет 72 GPU в стойке и обеспечивает 1.1 экзафлопс плотной производительности FP4.
B200 спроектирована для самых амбициозных AI-проектов следующего поколения. Карта поддерживает обучение моделей с триллионами параметров и контекстными окнами в миллионы токенов. Улучшенная поддержка моделей Mixture-of-Experts (MoE) с обновленным transformer engine и новыми форматами квантизации обеспечивает беспрецедентную эффективность для этого класса архитектур.
Google TPU: специализация для тензорных операций
Тензорные процессоры Google представляют альтернативный подход к ускорению AI-рабочих нагрузок, фокусируясь на максимальной эффективности тензорных операций, лежащих в основе нейронных сетей. TPU разработаны как специализированные интегральные схемы (ASIC), оптимизированные специально для глубокого обучения.
Тензорные операции - это вычислительные процедуры, применяемые к многомерным массивам данных (тензорам), которые широко используются в искусственном интеллекте, особенно при обучении нейронных сетей и обработке данных большой размерности
Архитектурные принципы TPU
Ключевым архитектурным компонентом TPU является систолический массив - специализированная структура для эффективного выполнения матричных умножений. В отличие от GPU с тысячами небольших универсальных ядер, TPU используют меньшее количество специализированных блоков обработки векторов (VPU) и выделенных узлов матричного умножения. Эта специализация обеспечивает превосходную энергоэффективность для специфических типов вычислений.
TPU v4 обеспечивает 275 терафлопс производительности FP16 и 550 терафлопс INT8 при энергопотреблении около 450 Вт. TPU v5e, оптимизированная для инференса, предлагает 197 терафлопс FP16 и 394 терафлопс INT8 при значительно сниженном энергопотреблении в 200 Вт. Google Cloud TPU v3 демонстрирует значительно большую энергоэффективность по сравнению с эквивалентными GPU.
Производительность и оптимизация
Для специфических рабочих нагрузок, оптимизированных для архитектуры TPU, производительность может превосходить GPU. Обучение ResNet-50 на датасете CIFAR-10 занимает около 15 минут на TPU v3 по сравнению с 40 минутами на NVIDIA Tesla V100, что демонстрирует 2.7-кратное ускорение. Обработка батча из 128 последовательностей модели BERT занимает 1.7 миллисекунды на TPU v3 против 3.8 миллисекунды на V100.
Google использует TPU для обучения и развертывания своих крупнейших моделей, включая PaLM и Gemini. TPU-поды, объединяющие тысячи процессоров в единый суперкомпьютер, обеспечивают масштаб, необходимый для обучения современных frontier-моделей. Архитектура спроектирована для минимизации латентности и максимизации пропускной способности при инференсе, что критически важно для поисковых систем и рекомендательных алгоритмов, обслуживающих миллиарды запросов.
Ограничения и компромиссы
Основное ограничение TPU - жесткая привязка к экосистеме Google и оптимизация преимущественно для TensorFlow. Хотя появилась поддержка JAX, разработчики, использующие PyTorch или другие фреймворки, сталкиваются с ограниченной совместимостью. TPU доступны исключительно через Google Cloud или Colab, что создает vendor lock-in и ограничивает возможности гибридных или мультиоблачных стратегий.
Гибкость TPU ниже по сравнению с GPU. Специализированная архитектура оптимальна для плотных матричных операций с большими размерами батчей, но может быть менее эффективной для динамических вычислительных графов, требующих частых изменений структуры. Отладка и профилирование на TPU может быть сложнее из-за ограниченного набора инструментов разработчика по сравнению с зрелой экосистемой CUDA для GPU.
Для большинства предприятий и стартапов, разрабатывающих AI/ML решения, GPU обеспечивают более сбалансированное сочетание производительности, гибкости и доступности. TPU предлагают преимущества в соотношении цена-производительность для TensorFlow-специфичных крупномасштабных задач в экосистеме Google Cloud, но для общих AI-рабочих нагрузок GPU остаются наиболее коммерчески жизнеспособным и масштабируемым вариантом.
Нейроморфные процессоры: будущее энергоэффективного AI
Нейроморфные вычисления представляют фундаментально иной подход к обработке информации, имитирующий структуру и функции человеческого мозга. В отличие от традиционных архитектур фон Неймана, где вычисления и память разделены, нейроморфные чипы интегрируют обработку и хранение информации, используя импульсные нейронные сети (spiking neural networks, SNN).
Intel Loihi 2: исследовательская платформа
Intel Loihi 2, нейроморфный процессор второго поколения, обеспечивает до 10 раз более высокую производительность обработки по сравнению с первым поколением. Чип содержит до 1 миллиона программируемых нейронов и 120 миллионов синапсов, эмулируя базовые принципы работы биологического мозга. Энергопотребление составляет около 1 Вт, что на порядки меньше традиционных GPU.
Система Hala Point от Intel представляет крупнейшую нейроморфную систему в мире с 1.15 миллиардами нейронов, обеспечивая более чем 10-кратное увеличение нейронной емкости и до 12-кратное повышение производительности по сравнению с системами первого поколения. Kapoho Point, компактная 8-чиповая плата на базе Loihi 2, позволяет разработчикам масштабироваться для решения более крупных задач и может стекироваться для крупномасштабных рабочих нагрузок.
Lava, открытая программная платформа для Loihi 2, поддерживает множественные методы AI и аппаратные платформы для разработки нейро-приложений. Это облегчает экспериментирование с нейроморфными подходами и постепенную интеграцию с существующими AI-системами.
Преимущества нейроморфных архитектур
Основное преимущество нейроморфных чипов - драматическое снижение энергопотребления. GPU потребляют значительное количество энергии, что может быть недостатком, особенно в окружениях где энергоэффективность критична. Нейроморфные вычисления могут обеспечить необходимую вычислительную мощность без истощения батарей устройств, что критически важно для edge-вычислений и IoT-экосистем.
Асинхронная, событийно-управляемая природа импульсных нейронных сетей обеспечивает естественное преимущество для задач, требующих реакции в реальном времени на непрерывные потоки входных данных. Автономные дроны, роботы и системы мониторинга выигрывают от способности быстро адаптироваться к изменяющимся условиям с минимальной задержкой.
Нейроморфные системы демонстрируют превосходную производительность при обучении на малых датасетах и обработке разреженных данных. Способность к быстрому обучению и адаптации делает их привлекательными для сценариев, где сбор массивных обучающих датасетов невозможен или непрактичен.
Практические применения и ограничения
Текущие применения нейроморфных вычислений включают распознавание образов и объектов в изображениях и видео, что делает их полезными для видеонаблюдения, автономных транспортных средств и медицинской визуализации. Робототехника использует нейроморфные чипы для создания более адаптивных и интеллектуальных роботов, способных обучаться из окружения и выполнять сложные задачи с большей эффективностью.
Edge AI представляет идеальный сценарий для нейроморфных вычислений, где критичны низкое энергопотребление и обработка в реальном времени. IoT-устройства, носимая электроника, умная сельскохозяйственная техника и системы умных городов выигрывают от энергоэффективной обработки на краю сети.
Обнаружение мошенничества, нейронаучные исследования и анализ временных рядов представляют дополнительные перспективные направления. Нейроморфные системы могут распознавать необычные паттерны в транзакционных данных, предоставляя более эффективный и точный метод детекции мошенничества.
Тем не менее, нейроморфные вычисления находятся на ранней стадии коммерциализации. Согласно недавнему обзору в Nature, опубликованному командой из 23 исследователей, нейроморфные технологии нуждаются в масштабировании для эффективной конкуренции с текущими методами вычислений. Не ожидается единого универсального решения для нейроморфных систем в масштабе, а скорее диапазон решений с различными характеристиками на основе потребностей приложений.
Энергопотребление AI-систем прогнозируется удвоиться к 2026 году, что делает нейроморфные вычисления перспективным решением для устойчивого AI. Нейроморфные чипы имеют потенциал превзойти традиционные компьютеры в энергоэффективности, пространственной эффективности и производительности, что может предоставить существенные преимущества в различных доменах, включая здравоохранение и робототехнику.
Системы охлаждения и энергопотребления
Стремительный рост вычислительных мощностей AI-инфраструктуры породил беспрецедентные вызовы в области термального менеджмента и энергообеспечения. Современные GPU-кластеры генерируют тепловые нагрузки, сравнимые с промышленными объектами, требуя инновационных подходов к охлаждению и энергоснабжению, которые выходят далеко за рамки возможностей традиционных центров обработки данных. Стойка с восемью NVIDIA H100 потребляет 44 киловатта энергии - в пять раз больше средней плотности традиционных ЦОД. Грядущие системы Blackwell GB200 NVL72 с 72 GPU в одной стойке требуют 140 киловатт и обязательного жидкостного охлаждения. Эта глава представляет комплексный анализ современных технологий термального менеджмента и стратегий энергетической эффективности, критически важных для успешного развертывания и эксплуатации AI-инфраструктуры.
Энергетические требования современных AI-систем
Энергопотребление AI-инфраструктуры демонстрирует экспоненциальный рост, создавая серьезные вызовы для операторов центров обработки данных и энергетических систем. Требования к энергии передовых AI-суперкомпьютеров удваиваются каждые 13 месяцев. В январе 2019 года Summit в Oak Ridge National Lab обладал наивысшей мощностью среди всех AI-суперкомпьютеров - 13 мегаватт, сегодня суперкомпьютер Colossus от xAI использует 280 мегаватт, что более чем в 20 раз больше.
Colossus полагается на мобильные генераторы, поскольку локальная электросеть не обладает достаточной мощностью для такого объема оборудования. В будущем мы можем увидеть обучение передовых моделей на географически распределенных суперкомпьютерах для смягчения трудностей доставки огромных объемов энергии в одно место, подобно установке обучения Gemini 1.0. Международное энергетическое агентство прогнозирует, что глобальное потребление электроэнергии центрами обработки данных может удвоиться между 2022 и 2026 годами, во многом благодаря внедрению AI.
GPU представляют основной источник энергопотребления в AI-инфраструктуре. NVIDIA H100 SXM5 работает при тепловой мощности (TDP) 700 Вт, требуя жидкостного охлаждения для оптимальной производительности. H200 сохраняет ту же энергетическую оболочку при увеличении памяти HBM3e до 141 ГБ с пропускной способностью 4.8 ТБ/с. Грядущий B200 поднимает планку еще выше: 1200 Вт для вариантов с жидкостным охлаждением против 1000 Вт для воздушных, с производительностью 20 петафлопс FP4, требующей sophisticated термального менеджмента.
Важно отметить, что вычислительная нагрузка составляет лишь часть общего энергопотребления. Охлаждение представляет из себя скрытого потребителя энергии, способного составлять до 40% общего потребления электроэнергии центром обработки данных!!! Память и системы охлаждения являются основными вкладчиками помимо непосредственно вычислений. По мере роста AI-моделей они требуют больше хранения и более быстрого доступа к данным, что генерирует дополнительное тепло.
Физические ограничения воздушного охлаждения
При 50 киловаттах потребления энергии на серверную стойку физика становится неумолимой: охлаждение требует 7850 кубических футов в минуту (CFM) воздушного потока при температурном дифференциале 20°F. Удвойте это до 100 киловатт, и вам потребуется 15,700 CFM - создавая ветры силы урагана через серверные воздухозаборники размером всего 2-4 квадратных дюйма.
Фундаментальное уравнение теплоотвода (Q = 0.318 × CFM × ΔT) раскрывает непреодолимую проблему: по мере увеличения плотности требуемый воздушный поток масштабируется линейно, но энергопотребление вентилятора масштабируется кубически к скорости вращения. Увеличение воздушного потока на 10% требует на 33% больше энергии вентилятора, создавая спираль энергопотребления, делающую высо��оплотное воздушное охлаждение экономически и практически невозможным.
Реальные свидетельства подтверждают эти теоретические ограничения. Один документированный случай показал, как 250 стоек всего при 6 киловаттах перешли с 72°F к более чем 90°F за 75 секунд при отказе охлаждения. Традиционные центры обработки данных, спроектированные для средней плотности стоек 5-10 киловатт, просто не могут справиться с современными GPU-рабочими нагрузками. Даже с продвинутым hot/cold aisle containment воздушное охлаждение испытывает затруднения за пределами 40 киловатт, в то время как неизолированные системы страдают от потерь емкости 20-40% из-за рециркуляции горячего воздуха.
Жидкостное охлаждение: технологическая необходимость
Вода может перемещать тепло примерно в 1000 раз эффективнее воздуха. Это означает, что стоечные серверы могут безопасно рассеивать около 60 киловатт или более при жидкостном охлаждении, по сравнению с гораздо меньшим пределом при использовании только вентиляторов. Direct-to-chip жидкостное охлаждение стало обязательным для современных GPU-кластеров высокой плотности. Жидкостное охлаждение теоретически продлевает срок службы GPU в 8 раз, обеспечивая при этом устойчивую максимальную производительность - критически важную для многонедельных циклов обучения AI.
Результаты бенчмаркинга подтверждают превосходство жидкостного охлаждения. Исследование, сравнивающее системы HGX с 8× NVIDIA H100 GPU, показало, что жидкостное охлаждение поддерживает температуры GPU между 41-50°C, в то время как воздушные аналоги флуктуируют между 54-72°C под нагрузкой. Эта термальная стабильность жидкостных систем обеспечивает на 17% более высокую производительность (54 против 46 терафлопс на GPU).
Архитектурные варианты жидкостного охлаждения
При жидкостном охлаждении (Direct-to-chip liquid cooling) система циркулирует хладагент через охладитель (cold plate или heat sink) в прямом контакте с чипом. Этот метод обеспечивает превосходную термальную производительность при сохранении доступа к компонентам для обслуживания. Большинство современных GPU-серверов высокой плотности используют этот подход, включая NVIDIA DGX H100 и H200 системы, которые должны работать между 5°C и 30°C.
Rear-door heat exchangers представляют промежуточное решение, заменяя стандартные задние двери стоек теплообменниками, подключенными к охлажденной воде. Этот подход может справляться со средними плотностями до 40 киловатт при меньших изменениях существующей инфраструктуры по сравнению с direct-to-chip решениями.
Single-phase immersion cooling погружает серверы в non-conductive, single-phase хладагент, такой как масла, фторуглероды или синтетические эфиры, которые поглощают тепло. Этот подход может справляться с очень высокими плотностями до 100 киловатт на стойку. Компания Penguin Solutions реализовала immersion cooling для Shell's Houston data center, увеличив производительность и снизив emissions.
Two-phase immersion cooling использует двухшаговый процесс, leveraging циклы испарения и конденсации путем погружения серверов в ванну специализированной диэлектрической жидкости, которая затем выкипает для рассеивания тепла. Это наиболее эффективный метод, способный справляться со 120+ киловатт на стойку при PUE (см. далее) близком к 1.02. Однако сложность обслуживания и высокие капитальные затраты ограничивают применение специализированными сценариями.
Энергетическая эффективность и PUE
Power Usage Effectiveness (PUE) измеряет эффективность центра обработки данных как отношение общего потребления энергии объекта к энергии, доставляемой IT-оборудованию. Идеальный PUE равен 1.0, означая, что вся энергия идет непосредственно на вычисления. Традиционные воздушные центры обработки данных типично достигают PUE 1.5-1.6, означая, что на каждый ватт IT-нагрузки тратится 0.5-0.6 ватт на охлаждение и инфраструктуру.
Direct-to-chip liquid cooling может достичь PUE около 1.05. Это представляет драматическое улучшение энергетической эффективности по сравнению с воздушным. Жидкостное охлаждение переносит нагрузку с вентиляторов на централизованные системы, обеспечивая более точные метрики эффективности инфраструктуры.
Immersion cooling системы достигают еще более низких PUE. Single-phase immersion типично достигает PUE 1.03, в то время как two-phase системы могут приближаться к 1.02. Эти системы устраняют onboard server вентиляторы и сокращают infrastructure overhead, efficiently управляя high-power CPU/GPU окружениями.
Итого
Мы посмотрели почему появилось специализированное оборудование и зачем ему не менее специализированное охлаждение. Теперь перейдем к тому, из чего состоит архитектора ИИ-решения, сколько стоит развернуть кластер для запуска ЛЛМ в совокупности для компании и как аллоцировать затраты на конкретные ИИ-инициативы.










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое