Как читать новости об ИИ и отличать прорыв от пресс-релиза. И как относиться к заголовкам про «ИИ отнимет работу»

Новости об ИИ в 2026 году выглядят как непрерывный поток "самых умных моделей" и "рекордных бенчмарков". За последние недели вышли заметные обновления у лидеров рынка: Claude Sonnet 4.6 (17 февраля 2026), Gemini 3.1 Pro (19 февраля 2026) и новая кодовая модель в линейке Codex у OpenAI - GPT-5.3-Codex (5 февраля 2026). Если читать это как ленту заголовков, то легко поймать тревогу и ощущение, что вы отстаете. Но почти любой релиз устроен предсказуемо: компания показывает выбранные метрики, публикует (или не публикует) методику, добавляет цены и формирует нарратив. Ваша задача быстро разобрать, реальный ли это скачок возможностей или просто красиво упакованный апдейт.
В статье рассмотрим, что проверять, когда выходит новая модель, и чем open-weight отличается от закрытых моделей и почему это влияет на рынок.
Итак, вышла новая модель, на что смотреть в первые 10 минут?
Шаг 1. Сначала идите в первоисточник: релиз, model /system card и цена
Релиз (news /blog post) - что заявляют публично.
Если релиз - это витрина, то system/model card - это документ-инструкция по эксплуатации. Там часто спрятано главное:
-
какие режимы thinking включали
-
сколько попыток при тестировании
-
какие инструменты были доступны
-
как меняется качество при других настройках
-
где модель ломается и ошибается.
Этот документ стоит читать даже разработчикам для себя, потому что там чаще всего спрятаны детали, от которых зависит бюджет и качество в проде.
Хорошая иллюстрация: Anthropic в system card Sonnet 4.6 показывает, что при схожих бенчмарках модели могут тратить радикально разное количество "thinking tokens". В замере на 100 вопросов GMMLU (English) траты такие: Gemini 3 Pro - 1 078 токенов/вопрос, Sonnet 4.6* - 246, Opus 4.6 - 191, GPT-5.2 Pro - 127.
*Кстати, отдельно про модель Claude Sonnet 4.6, чем отличается от Claude Opus 4.6 я разбирала здесь.
Это наглядно показывает, что похожие баллы в бенчмарках не означают одинаковую эффективность: модели могут тратить разный объем вычислений и токенов для достижения схожего результата, а значит и разной стоимостью и задержкой в ваших сценариях.
Теперь поговорим про цену, и почему X$ за миллион токенов почти всегла вводит в заблуждение. Проблема большинства обсуждений цен в том, что они звучат одной строкой: модель дешевая. Но в реальности бюджет чаще сгорает не на input, а на output, особенно если модель много рассуждает (а thinking часто учитывается именно в output). Так что сравнивайте input и output, и отдельно уточняйте, включены ли "thinking tokens" в output-тарификацию (у Gemini это явно прописано).
Вот, например, Anthropic прямо пишет, что Sonnet 4.6 остается по цене на уровне Sonnet 4.5 ($3/$15 за 1M токенов input/output), аOpus 4.6 - $5/$25. А Google показывает цены Gemini 3.1 Pro Preview отдельной строкой - $2 / $12 при промптах ≤ 200k токенов, и там важно, что стоимость растет для сверхдлинных промптов (больше 200k токенов). У OpenAI цены по API удобно сверять по официальной таблице: например, gpt-5.2 - $1.75 input и $14 output за 1M токенов.
Как прикинуть стоимость запроса:
cost ≈ (input_tokens * price_in + output_tokens * price_out) / 1_000_000
Еще раз: если у вас задачи типа "сгенерируй отчет", "напиши код + объясни", "план + шаги + проверка", то сравнивать модели по input-цене - почти бессмысленно. Смотрите на output и на то, сколько модель его производит в вашем типовом пайплайне.
Шаг 2. Поймите, что именно измеряет бенчмарк
Почти каждый релиз сопровождается таблицей бенчмарков. Важно не просто увидеть цифры, а понять, что они измеряют и в каких условиях.
Что такое бенчмарк?
Это стандартизированный тест для сравнения моделей. Как экзамен, но с нюансом: каждый экзамен проверяет лишь узкий набор навыков, а иногда его можно натренировать или обойти правилами.
Ниже 4 бенчмарка, которые чаще всего всплывают в новостях:
|
Бенчмарк |
Что тестирует |
На что смотреть в методике |
|---|---|---|
|
MMLU |
широкие знания по 57 темам (мультивыбор) |
zero/few-shot, калибровки, версии датасета |
|
SWE-bench (Verified) |
исправление реальных GitHub-проблем патчем |
сколько задач, какие репозитории, как верифицируют |
|
ARC-AGI-2 |
новые задачи на обобщение, логические паттерны |
публичная vs. приватная оценка, правила попыток |
|
Chatbot Arena |
«человеческое предпочтение» в слепых сравнениях |
как считают рейтинг (Elo/BT), объем голосов, сдвиги |
1) MMLU и почему вокруг него меньше шума, чем раньше
MMLU - классический multiple-choice тест (тест с выбором ответа из нескольких вариантов) по 57 предметам. В оригинальном датасете 15 908 вопросов.
Он хорошо отражает академическую широту, эрудицию, но у топ-моделей стал хуже различать лидеров: многие упираются в потолок, и появляются вопросы к качеству и устойчивости метрики. Поэтому появились усложнения вроде MMLU-Pro, там больше вариантов ответов, более "reasoning-heavy" вопросы, меньше шума.
На практике MMLU тест используют как быстрый индикатор общей эрудиции, но никак не решающий аргумент при выборе модели для продакшена.
Вы дочитали до середины статьи, а значит, статья, вероятнее всего, вам понравилась, как и моя подача и стиль письма, так что вы можете поддержать меня в моем телеграм канале, где уже собрано много полезного и проверенного.
2) SWE-bench и SWE-bench Verified - ближе к реальной разработке, но тоже с оговорками
-
SWE-bench пытается измерять способность модели чинить реальные задачи из разработки: модель должна выдать патч, который проходит тесты.
-
SWE-bench Verified - поднабор, где задачи дополнительно проверены людьми, чтобы оценка была надежнее.
Это уже ближе к практике, чем абстрактные викторины, но все равно ограничено типом репозиториев и процедурой оценки. Поэтому тут важно смотреть на условия, например, single attempt или несколько попыток. Давайте теперь разберемся на примере Gemini 3.1 Pro.
В официальной таблице Gemini 3.1 Pro указано: SWE‑bench Verified (single attempt) - 80.6%, а у Sonnet 4.6 - 79.6% в сопоставимом режиме. Разница тут минимальная, так что для реальных команд обычно важнее цена и стабильность, чем еще один процент по этому бенчмарку.
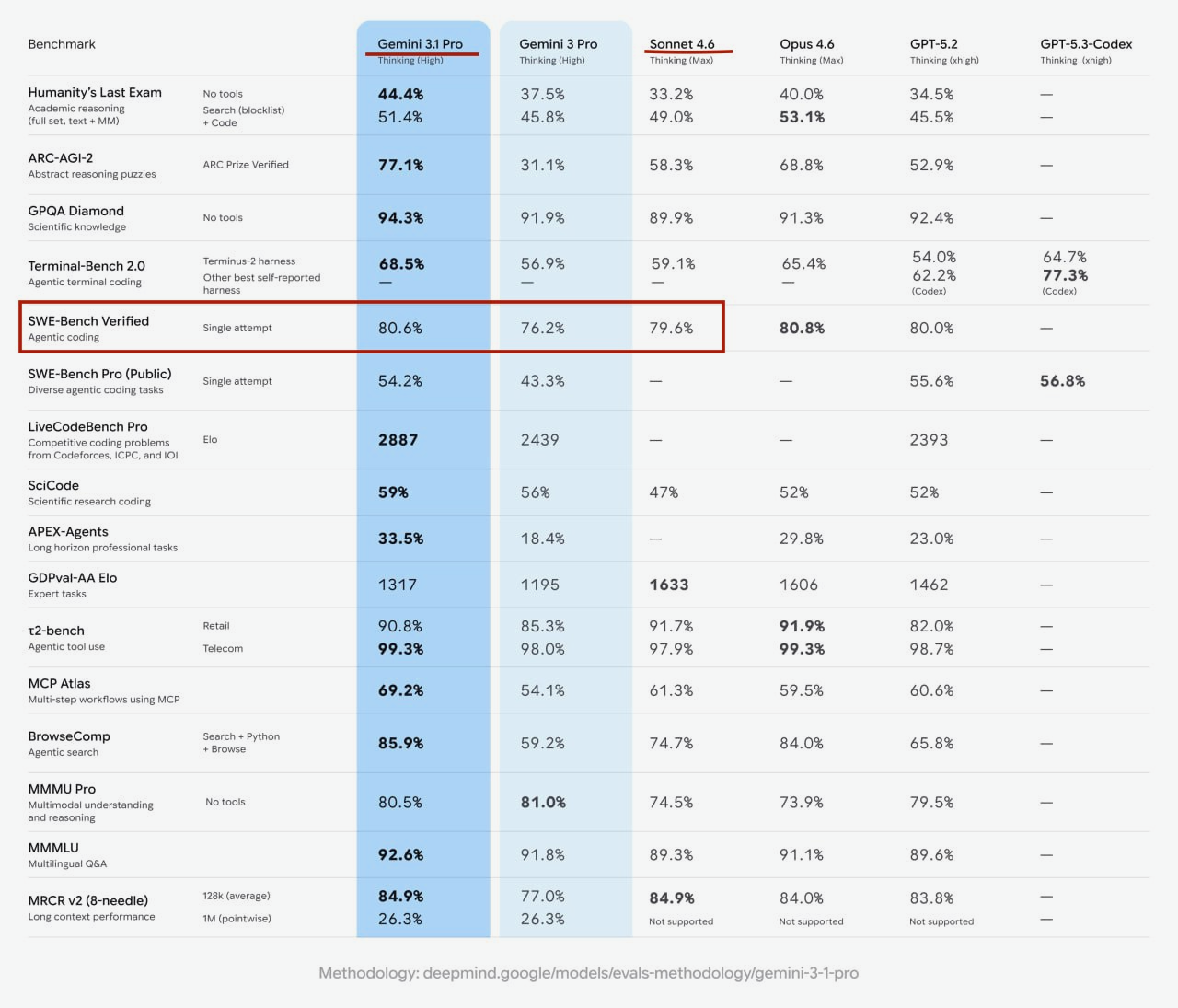
3) ARC-AGI-2 - человек против ИИ
ARC-AGI-2 - один из самых интересных современных тестов на абстрактное мышление и обобщение. Он спроектирован так, чтобы людям было относительно просто его пройти, а вот моделям сложно.
Два важных факта о методологии:
-
каждая задача в ARC-AGI-2 решена как минимум двумя людьми за две попытки или меньше (pass@2), в контролируемом исследовании
-
авторы прямо отмечают, что результаты ниже 5% часто не считают осмысленным сигналом.
На этом фоне ARC-AGI-2 = 77.1% у Gemini 3.1 Pro - это действительно заметная новость релиза, потому что сдвиг относительно Gemini 3 Pro в их таблице огромный: с 31.1% до 77.1%:
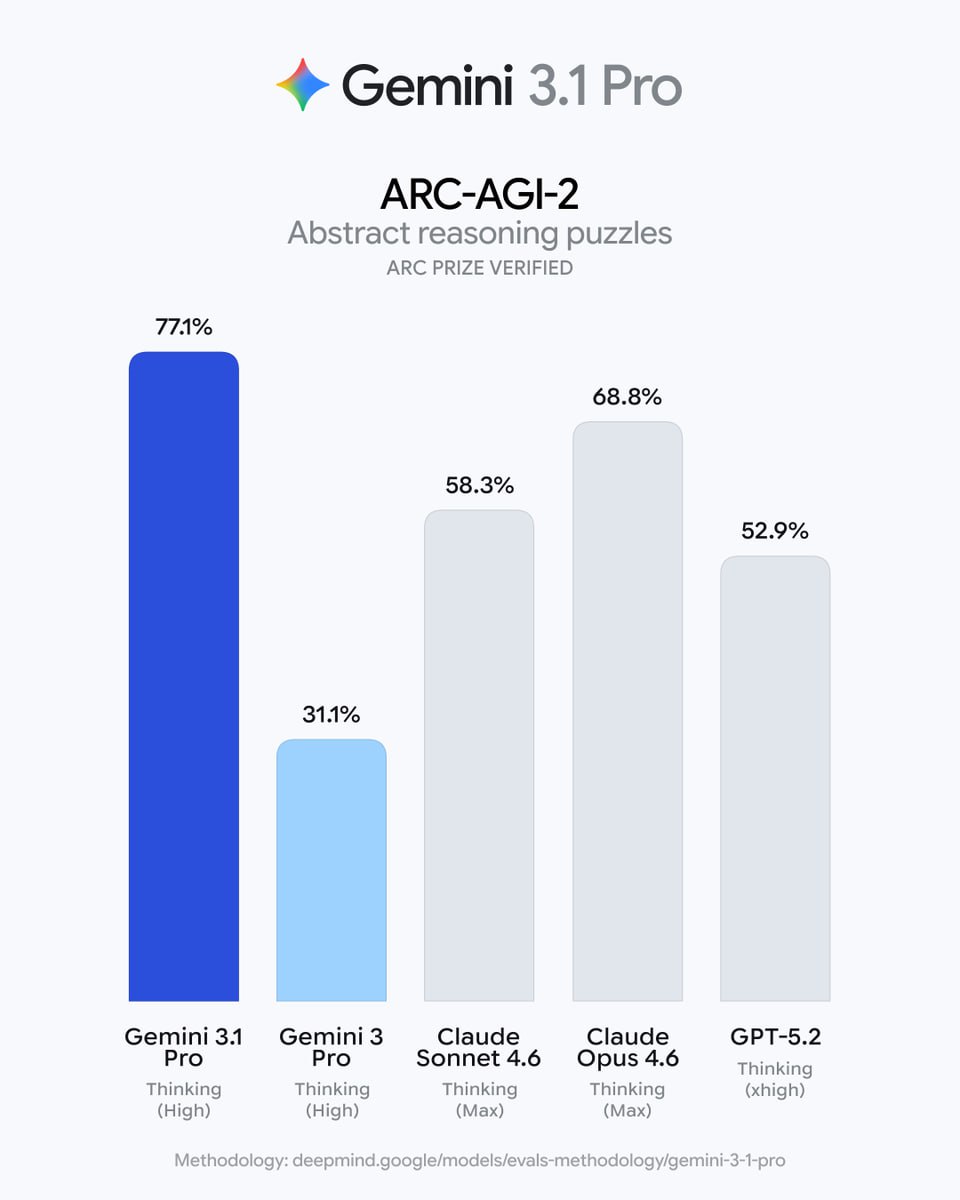
Вот, кстати, любопытно, что у меня в комментах новую Gemini 3.1 Pro разнесли в пух и прах, и это уже не бенчмарки, а настоящее мнение людей.
4) Chatbot Arena - народный рейтинг
Всегда полезно добавлять независимую проверку, особенно если это человеческая проверка в слепых сравнениях.
Chatbot Arena (LMSYS) - платформа, где людям показывают 2 анонимных ответа и спрашивают, какой лучше. Затем строится рейтинг по Elo/родственным моделям. Плюс в этом масштаб человеческих сравнений. А вот минусы: да, можно отследить, что нравится людям, но этот результат не обязательно будет лучшим решением для бизнеса, а еще смешается выборка, и слишком часто выходят новые версии.
Chatbot Arena используют хороший индикатор качества ответа глазами человека. Но это явно не универсальный ответ, что лучше для бизнеса и продакшна, особенно в задачах с метриками качества, безопасностью и бюджетом.
Что ж, про бенчмарки понятно. До этого мы говорили о метриках и стоимости при работе через API. Но есть еще один фактор, который принципиально меняет экономику и риски - модель вообще можно запустить у себя или нет. Именно здесь возникает различие между закрытыми моделями и моделями с открытыми весами.
Шаг 3. Понять, чем Открытые веса отличаются от Закрытых моделей, и что это меняет на практике
Закрытые модели (ChatGPT, Claude, Gemini): вы используете продукт/SDK/API, но он принадлежат компании: вы пользуетесь сервисом, но не можете скачать веса и запускать модель у себя.
Open-weight модели: публикуются веса (параметры), их можно скачать, запускать локально, дообучать/адаптировать для своей инфраструктуры и встраивать в свои системы (с оговорками лицензии). Такой подход сейчас снова становится конкурентным фактором, и даже крупные игроки обсуждают выпуск open-weight моделей.
Почему это важно:
-
Приватность и контроль. Локальный запуск - это другой класс задач: данные могут не покидать вашу инфраструктуру, в отличие от внешнего API. Это не становится автоматически безопасно, но контроль выше.
-
Доверие и воспроизводимость. С open-weight проще независимая проверка: исследователи могут запускать те же веса, проверять поведение на своих наборах и повторять эксперименты.
-
Конкуренция и давление на цены. Хороший open-weight релиз способен сдвинуть рынок.
Например, DeepSeek прямо объявил MIT-лицензию для DeepSeek-R1 и позиционировал это как открытый доступ к весам/выводам.
Важная оговорка: open-weight не всегда означает "полностью свободная лицензия". У разных лабораторий условия могут заметно отличаться (порог выручки, коммерческие ограничения и т. п.).
Как читать заголовки про «ИИ отнимет работу»
Это самый тревожный тип новостей, поэтому здесь особенно важна дисциплина чтения.
1) Смотрите, кто говорит и какие у него стимулы
Если CEO компании, которая продает ИИ, говорит "через 3–6 месяцев ИИ будет писать 90% кода" - это не обязательно ложь, но это высказывание человека с сильной заинтересованностью. Например, так публично говорил в марте 2025 Dario Amodei (CEO Anthropic).
2) Смотрите на реальные метрики внедрения, а не на заявления, что все автоматизировали
Даже в бигтехе публичные цифры обычно осторожные: "существенная доля кода" или "четверть нового кода", а не "90% всего кода завтра".
Например, Google официально говорил, что больше четверти нового кода генерируется ИИ и затем принимается инженерами. Microsoft публично называл диапазон 20–30% кода в репозиториях как "written by software (AI)".
3) Проверяйте формулировки
Как не банально это может прозвучать, но следите за формулировками: "может" не равно "точно будет", "затронет" не равно "заменит". Классический пример аккуратной формулировки - отчеты уровня МВФ: "почти 40% рабочих мест затронуты ИИ", и это включает как замещение, так и дополнение (рост продуктивности).
4) Ищите исследования про фактический эффект
Неприятная для хайпа часть: эффект часто скромнее ожиданий. Свежий working paper NBER (опрос ~6000 топ-менеджеров в США/Великобритании/Германии/Австралии) фиксирует, что 89% компаний не увидели измеримого эффекта ИИ на производительность за последние три года (в их метрике), при этом ожидания на 3 года вперед умеренные.
Кстати, я отдельной статьей как раз рассматривала кейсы "boomerang hires", когда компании возвращают сотрудников, уволенных из-за ИИ. Там и про завышенные ожидания, и подводные камни и отдельные кейсы компаний, с чем они столкнулись и чего не могли предусмотреть после замены сотрудников ИИ.
5) Всегда ищите вторую серию кейсов
Громкие истории про замену людей ботами особенно полезно читать в динамике.
Классический пример - Klarna: компания публично продвигала идею, что AI-ассистент делает работу сотен агентов, а затем стала возвращать людей в службу поддержки, после жалоб на качество сервиса и безэмоциональность ботов по сравнению с настоящим сотрудником клиентской поддержки.
Новости об ИИ проще читать как инженерный отчет, а не как рекламу: сначала условия тестов, потом цифры, потом стоимость и ограничения. Бенчмарки без методологии мало что значат, а system card и расход токенов часто важнее еще пары процентов в таблице. Ваша цель не запомнить все модели, а научиться быстро отличать реальный прирост возможностей от красиво оформленного пресс-релиза, и принимать решения по фактам, а не из-за хайпа вокруг модели. Вы можете поддержать меня в моем телеграм канале, там я пишу о том, в чем разбираюсь или пытаюсь разобраться сама, тестирую полезные ИИ-сервисы, инструменты для офиса, бизнеса, маркетинга и видео.










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое