Как написать конвертер веб-страниц в PDF и не сойти с ума
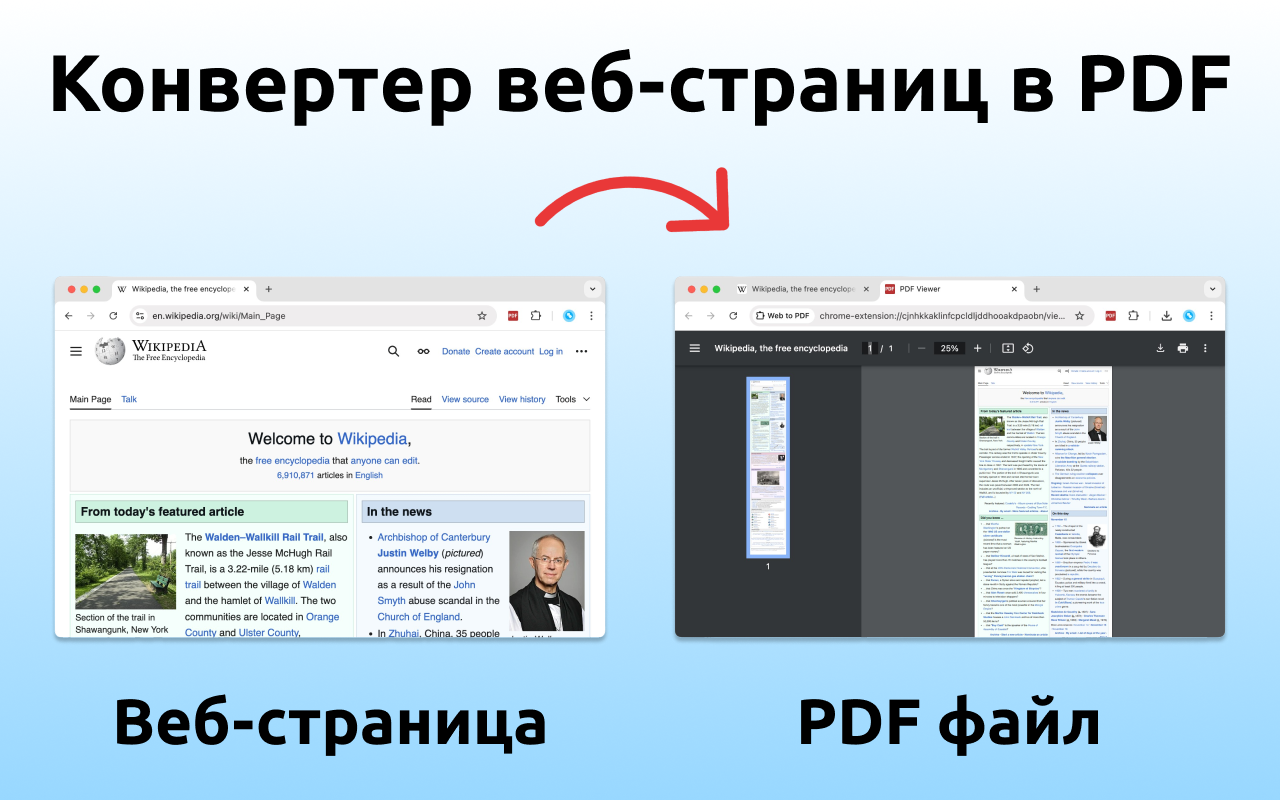
Вам когда-нибудь хотелось сохранить статью в PDF без лишних деталей, только в виде текста? Или сохранить только определённый элемент страницы? И чтобы всё это было на одной длинной странице, без разрывов?
Мне тоже. Поэтому, я решил написать своё решение и оформить его в виде браузерного расширения.
Чем же плох стандартный CTRL+P?
При сохранении в PDF я хочу видеть документ ровно в том виде, в котором он представлен на экране. Иметь возможность переходить по ссылкам из PDF и чтобы весь документ был на одном длинном листе, без разрывов.
CTRL+P этого не даёт, он хорош только для печати на бумаге на принтере. Т.е. ровно для той функции, для которой изначально задумывался. А всё, что я перечислил он не умеет.
Какие режимы есть в расширении
Вся страница
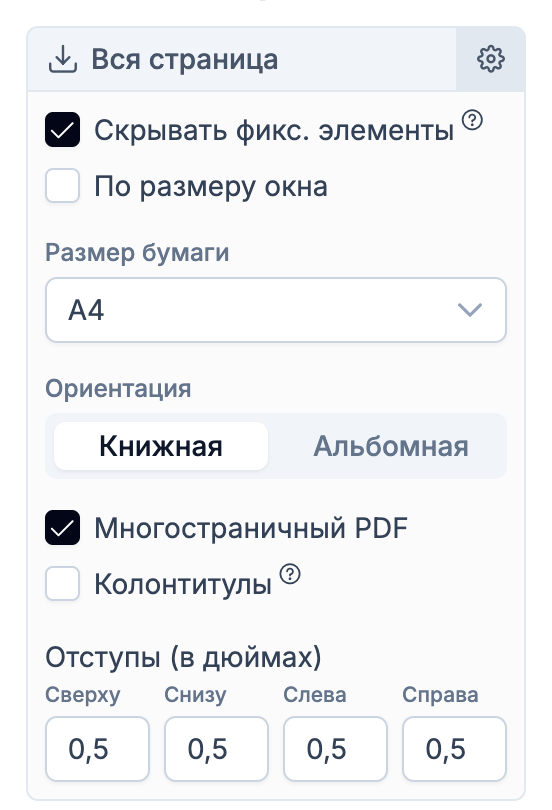
Сохраняет всю страницу ровно в том виде в котором она представлена на экране.
Текст остаётся выделяемым, а ссылки кликабельными. Это не картинка с распознанным текстом OCR, а настоящий PDF с текстом и кликабельными ссылками.
Экспорт элемента страницы
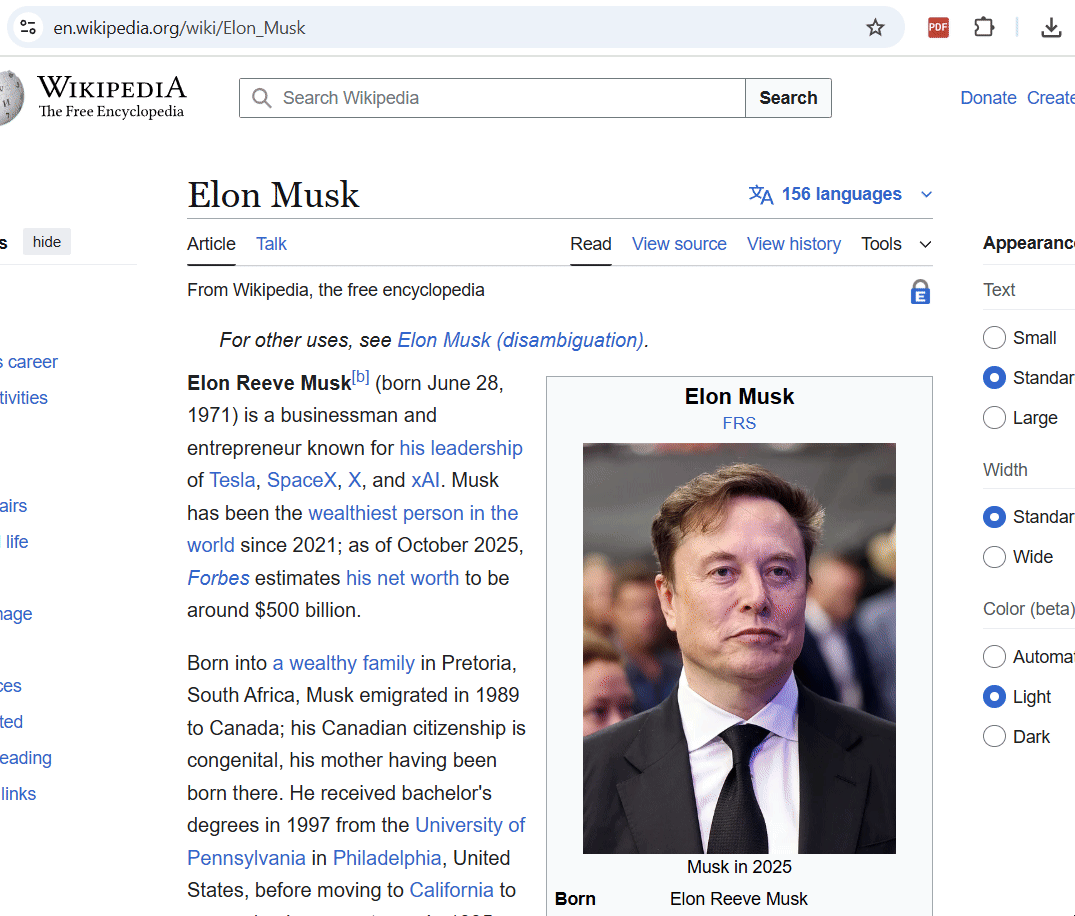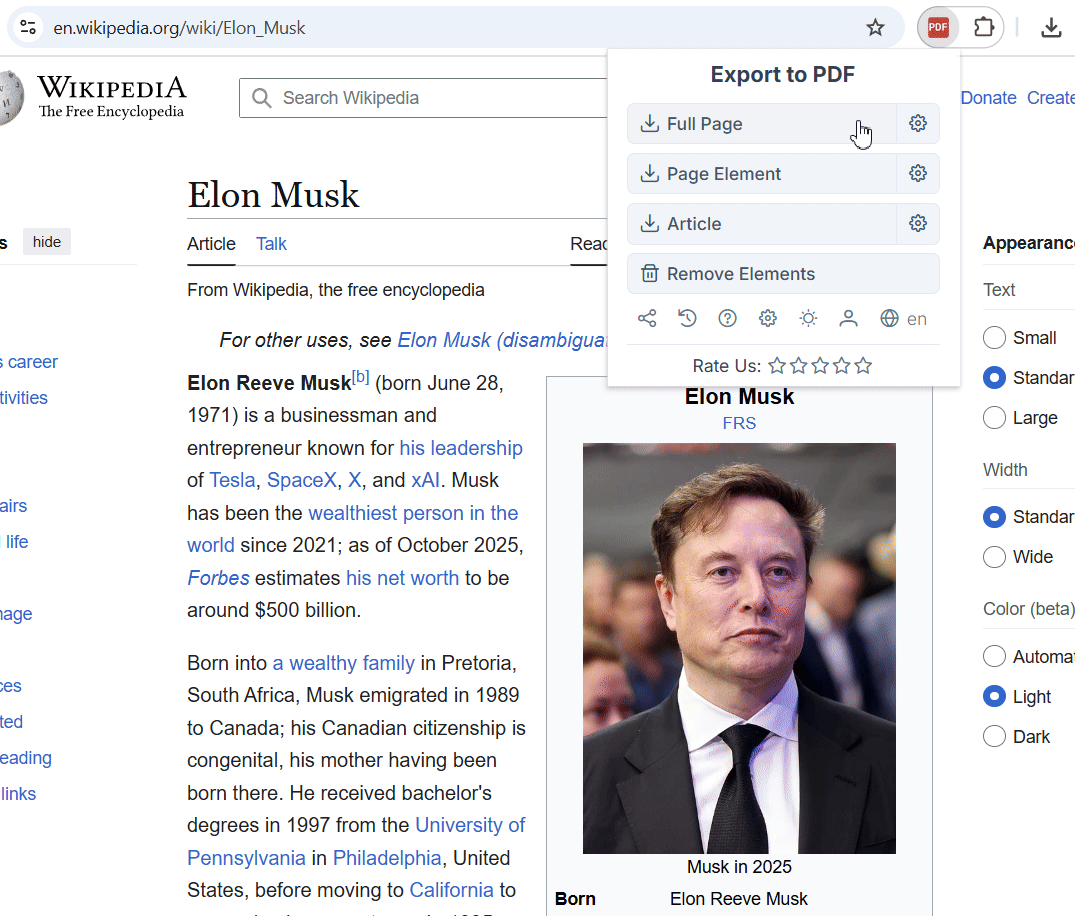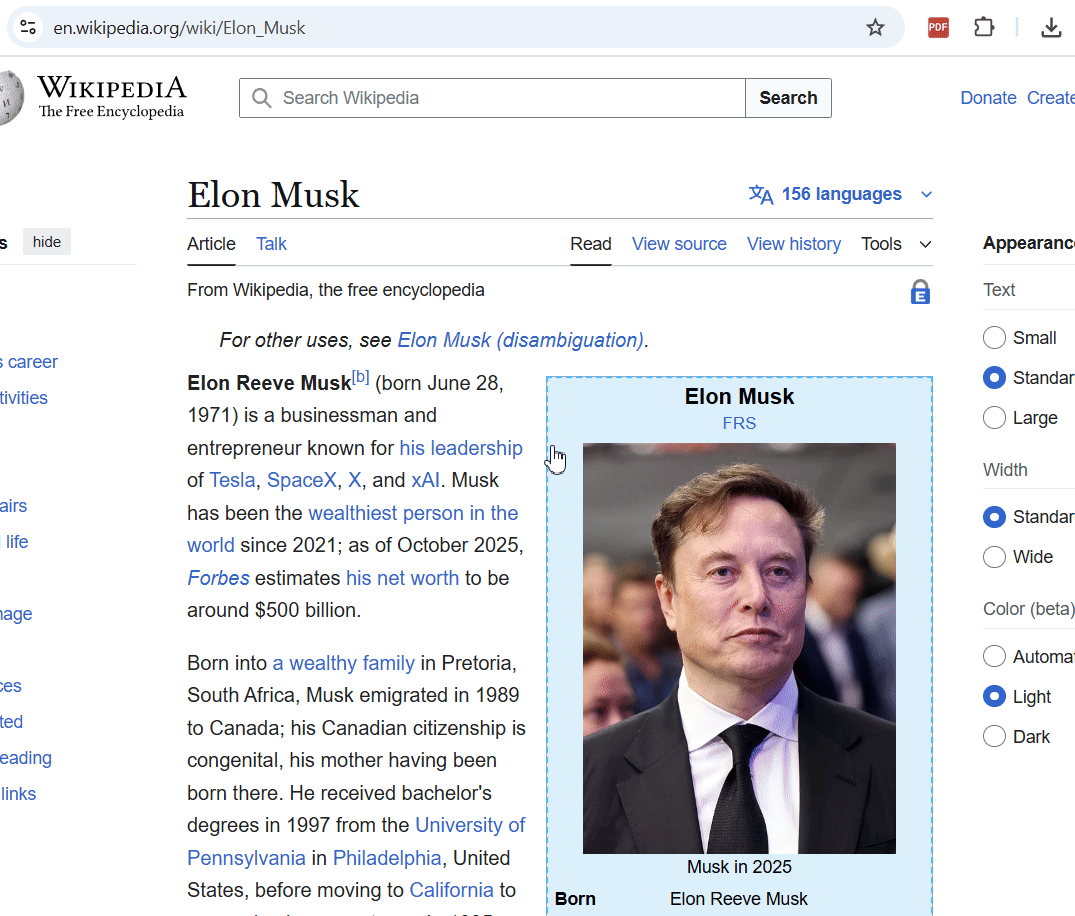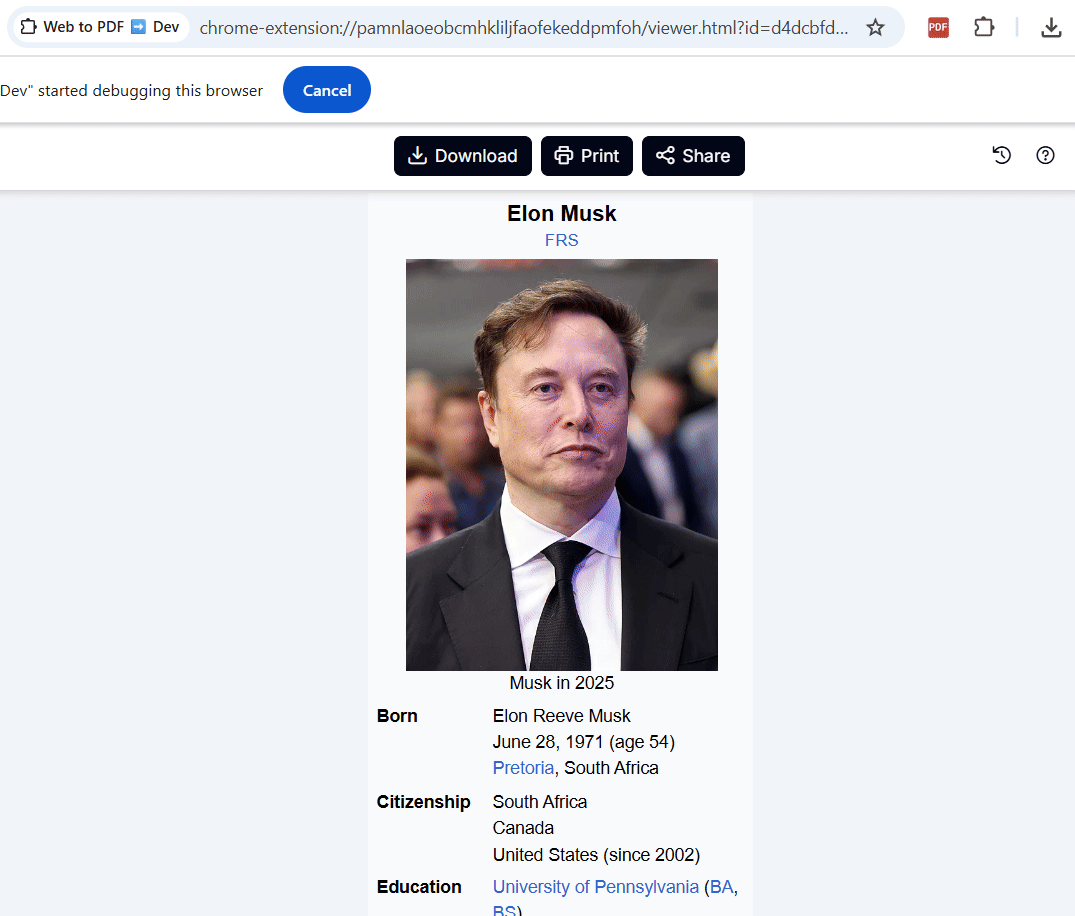
В этом режиме можно выбрать определённый элемент страницы и экспортировать только его. Это очень удобно, когда нужно сохранить только статью, только блок кода ил�� любой другой элемент.
Я часто использую этот режим, когда отправляю Гугл-формы и хочу сохранить заполненные данные, чтобы потом не забыть что отправил.
Статья
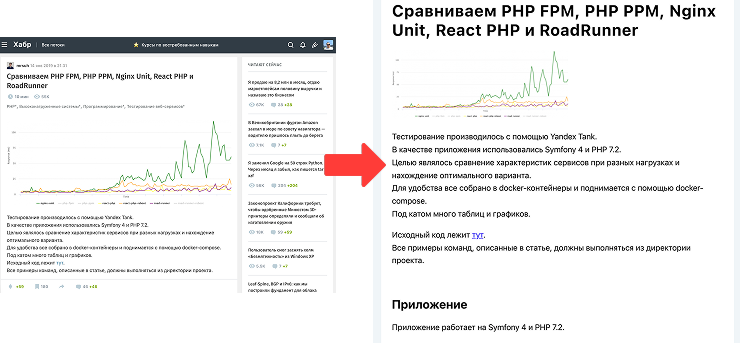
Один из самых интересных режимов. В нём можно сохранять статьи из блогов в режиме для чтения. На странице не будет ничего лишнего, кроме самой статьи.
В этом режиме я предусмотрел перенос текста на новую строку в блоках кода, а также раскрытие тегов <details>, чтобы весь текст статьи попадал в PDF.
Удаление элементов
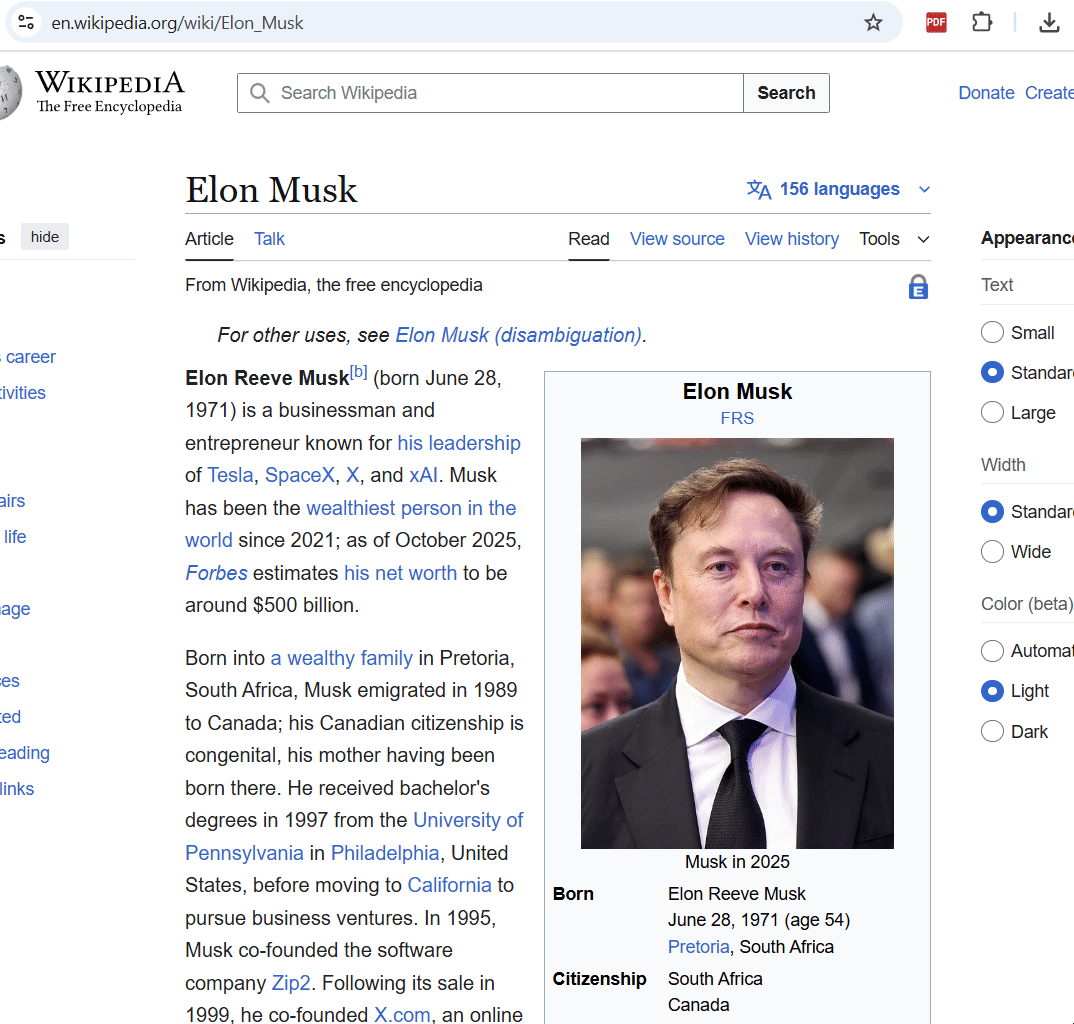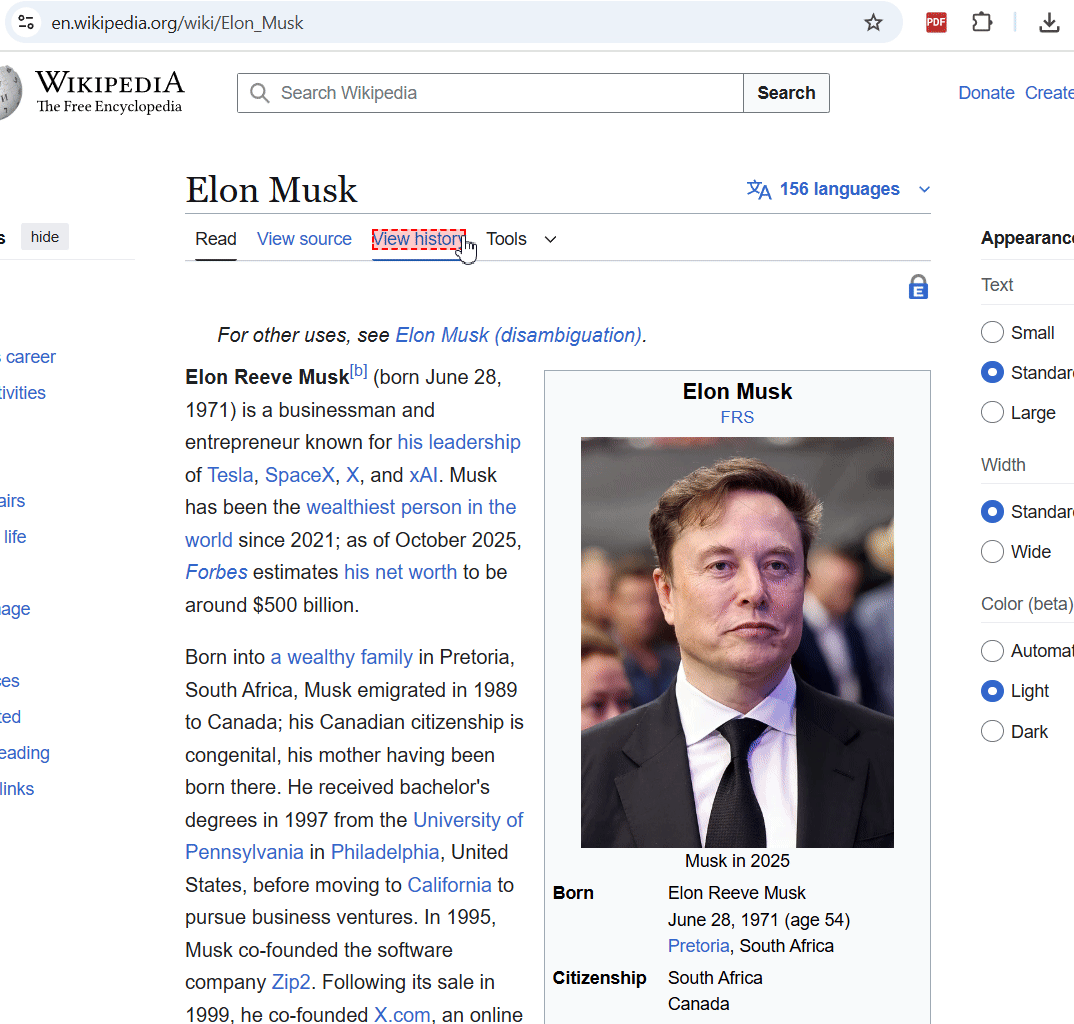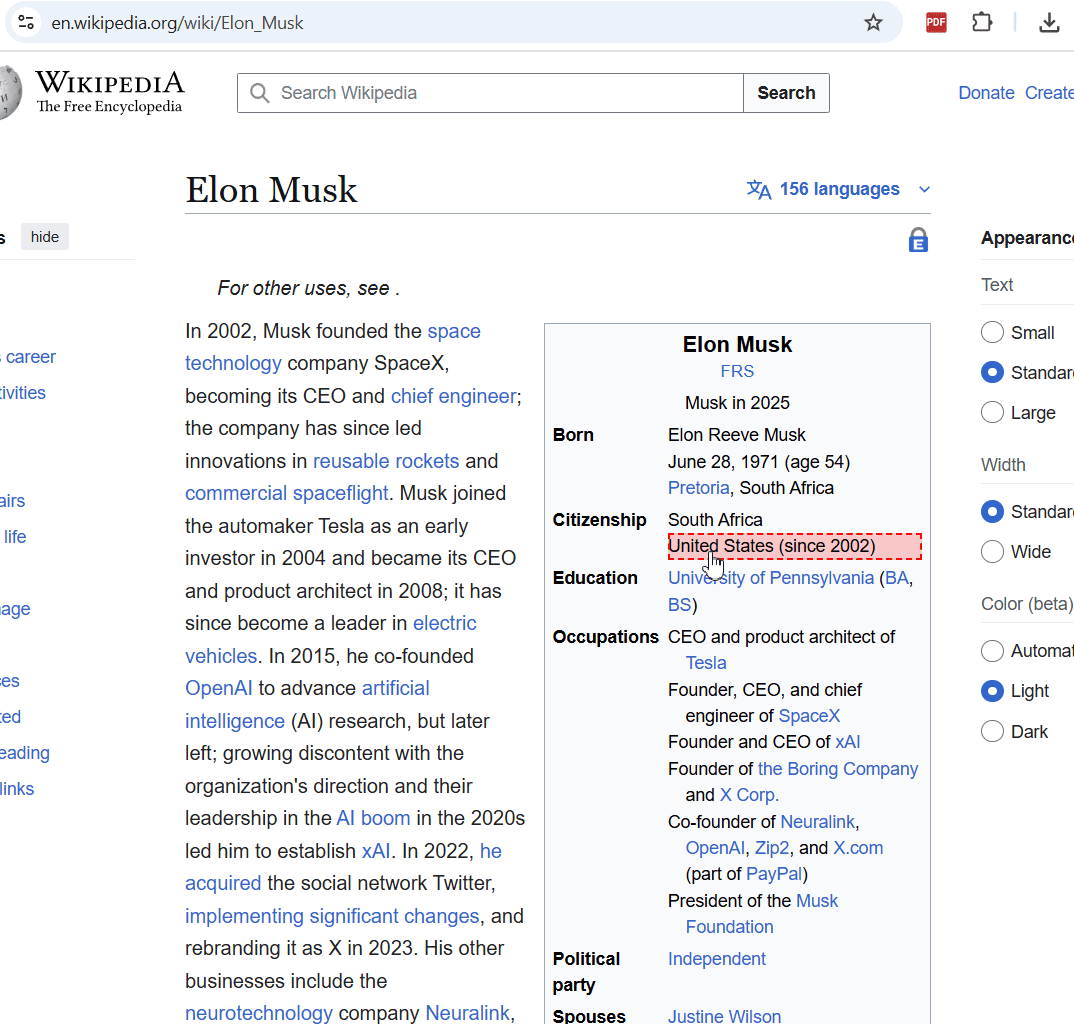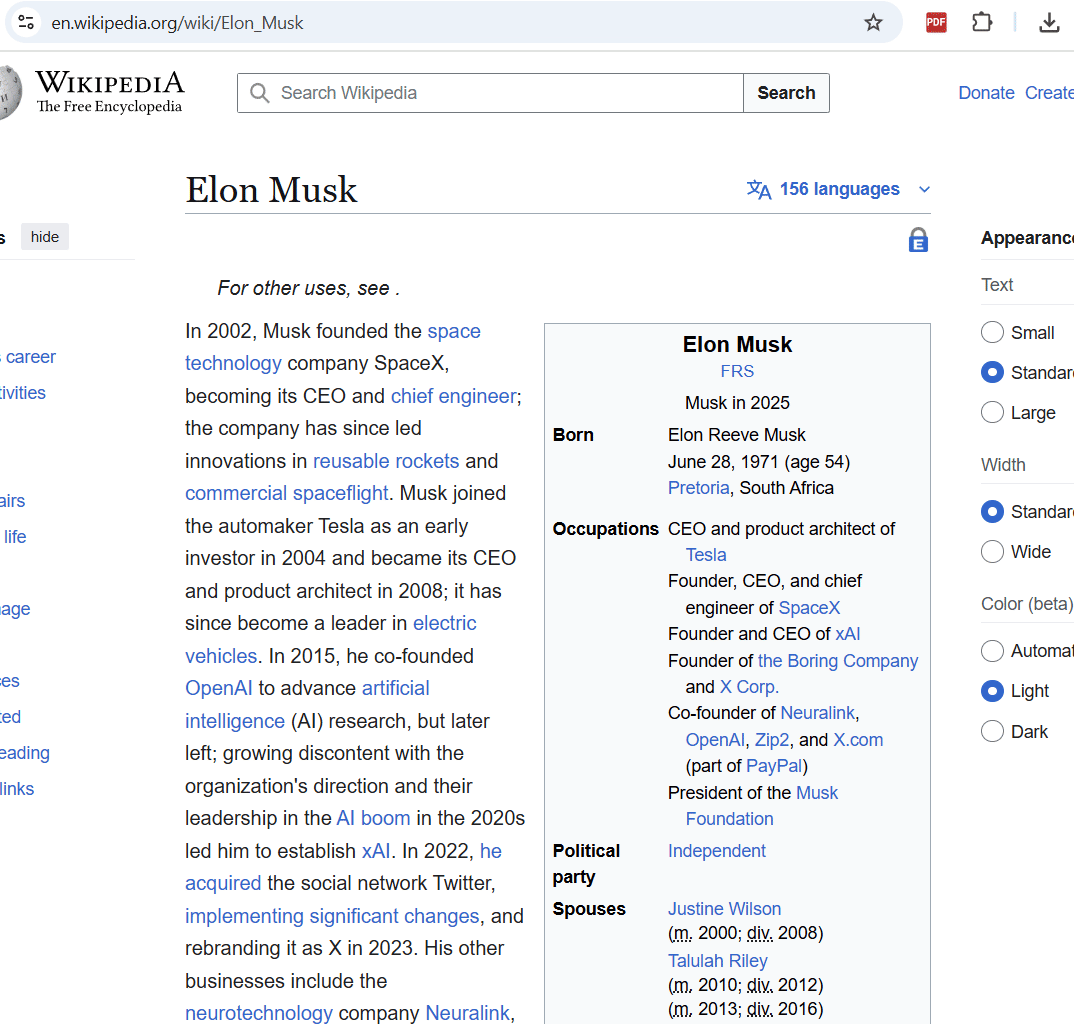
При включении режима, можно выбрать любой элемент на странице, кликнуть по нему и удалить его.
Например, можно удалить сайдбары, меню, рекламу и т.д.
Если случайно удалили что-то важное, можно нажать CTRL+Z и откатить изменения обратно.
Экспорт чатов с ChatGPT, DeepSeek и Gemini
Раз ИИ компании не хотят внедрять функцию экспорта чата в PDF, я сделал это в своём расширении. Почему нет? Очень удобно - в один клик можно сохранить текущий открытый диалог.
В каждом из режимов можно выбрать макет: одностраничный или многостраничный PDF, в зависимости от того, хотите вы распечатать PDF на принтере или сохранить материал для чтения без разрывов страницы.
Макет можно настроить по размеру экрана или под стандартные размеры типа A4, A5 и т.д.
Как не сойти с ума
Различные варианты вёрстки
Сохранять сайты в PDF сложно. Невозможно учесть все варианты вёрстки. Всегда есть риск, что что-то где-то отобразится не так. И я поначалу старался фиксить эти моменты на отдельных сайтах, но быстро понял что это борьба с ветряными мельницами, поэтому сделал фиксы только под крупные сайты типа Notion.
Атомарный CSS
Из-за повального внедрения атомарных css фреймворков типа Tailwind, сложно выделить отдельные элементы для экспорта на определённых сайтах.
Например, чтобы сделать экспорт диалога с ChatGPT, пришлось повозиться и писать хитрые селекторы, чтобы выбрать элемент с диалогом.
На Claude Code я вообще отказался от этой затеи именно из-за вёрстки. Проще всего было с Gemini, там классы назывались человеческим языком.
Lazy-loading
Lazy-loading картинки - это отдельный прикол. Например, есть длинная страница с кучей картинок и чтобы все картинки загрузились и попали в PDF я не придумал ничего лучше, чем проходиться в цикле по всем картинкам, ждать возле каждой 100 мс и переходить к следующей, чтобы инициализировать прогрузку картинки.
Если у вас есть идеи как прогружать подобные элементы более изящным способом - буду рад советам в комментариях.
Восстановление стилей страницы
Режим сохранения элемента страницы тоже доставил хлопот. Чтобы сохранить элемент, я скрываю все что есть на странице кроме самого элемента. А потом восстанавливаю стили. И всё это без перезагрузки страницы.
Страницу нельзя перезагружать, потому что если вы заполнили длинную форму и хотите её сохранить в PDF, а в процессе у вас перезагрузится страница, то вашему гневу не будет предела, я знаю о чём говорю - сам через это проходил.
Отсутствие документации
Рендеринг готового PDF - это отдельная песня. Нет нормальных библиотек для этой задачи. Есть всем известный PDF.js от Mozilla, в котором есть PDFViewer. Круто! Если бы не одно “но”. Полное отсутствие документации. Приходится разбираться по исходникам и обсуждениям в issue.
На Гитхабе много issue и discussions, где люди просят сделать документацию, но Мозилла не хочет этого делать. Что ж, имеют право, по крайней мере за библиотеку спасибо.
Что под капотом
Вот библиотеки, которые я использую:
-
WXT.dev - фреймворк для написания расширения. Это лучшее на мой взгляд решение на данный момент. Быстрый HMR. Запуск отдельного браузера для тестирования, скорость разработки.
-
PDFViewer для рендеринга PDF. Это жесть, но нормальных альтернатив нет.
-
Chrome Debugger для преобразования страницы в PDF. На первый взгляд странное решение, но оно даёт наивысшее качество конечного PDF.
Что дальше
Я добавляю интеграции с крупными сайтами. Например, недавно я добавил возможность сохранять посты на Пикабу и Реддит в один клик.
Помимо расширения, я так же сделал веб-сервис для сохранения страниц в PDF. В нём нет такого широкого функционала как в расширении, но зато можно сохранять страницы с телефона.
Расширение и сервис бесплатные для пользователей из России.










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое