Хайп vs реальность: что tech-медиа пишут об ИИ и кто реально лучший в 2025?
За последний месяц я детально отслеживал каждую статью об искусственном интеллекте в ведущих западных tech-изданиях. 200 статей из TechCrunch, VentureBeat и MIT Technology Review за 26 дней — в среднем почти 8 новостей об ИИ каждый день. Цель эксперимента была проста: понять, совпадает ли то, о чём громче всего кричат медиа, с реальными возможностями ИИ-моделей.
Спойлер: не совпадает. И разрыв между медийным шумом и реальностью оказался весьма значительным.
Методология исследования
Я мониторил три ключевых источника tech-новостей:
-
TechCrunch — крупнейшее издание о стартапах и технологиях
-
VentureBeat — фокус на enterprise-решениях и ИИ
-
MIT Technology Review — академический взгляд на технологии
Из всего потока новостей отбирались только статьи, связанные с искусственным интеллектом — упоминание компаний-разработчиков, конкретных моделей, AI-продуктов или технологий машинного обучения. Затем я анализировал:
-
Частоту упоминаний компаний
-
Частоту упоминаний конкретных моделей
-
Популярные темы и тренды
-
Распределение по источникам
Для сравнения с реальностью использовал свежие данные из Chatbot Arena Leaderboard — одного из самых авторитетных независимых рейтингов ИИ-моделей, основанного на миллионах реальных пользовательских оценок.

Что пишут медиа: результаты анализа
Распределение по источникам
Первое, что бросается в глаза — TechCrunch доминирует в освещении ИИ-тематики:
|
Издание |
Статей |
Процент |
|
TechCrunch |
141 |
70.5% |
|
VentureBeat |
35 |
17.5% |
|
MIT Technology Review |
23 |
11.5% |
TechCrunch публикует 7 из 10 статей об ИИ среди этих трёх изданий. Это говорит о том, что издание делает сильный акцент на AI как на главный технологический тренд.
ТОП компаний по упоминаниям в медиа
А вот кого чаще всего упоминают журналисты:
|
Место |
Компания |
Упоминаний |
% от статей |
|
1 |
OpenAI |
28 |
14.0% |
|
2 |
|
10 |
5.0% |
|
3 |
Meta |
10 |
5.0% |
|
4 |
Microsoft |
8 |
4.0% |
|
5 |
Nvidia |
8 |
4.0% |
|
6 |
Apple |
6 |
3.0% |
|
7 |
Amazon |
6 |
3.0% |
|
8 |
Anthropic |
3 |
1.5% |
|
9 |
Perplexity |
3 |
1.5% |
OpenAI — безоговорочный лидер медийного пространства, упоминается в каждой 7-й статье. Это почти в 3 раза чаще, чем Google или Meta. Anthropic, создатель Claude, получает всего 3 упоминания — в 9 раз меньше, чем OpenAI.
ТОП моделей по упоминаниям
Если смотреть на конкретные модели:
|
Место |
Модель |
Упоминаний |
% от статей |
|
1 |
ChatGPT |
13 |
6.5% |
|
2 |
Gemini |
4 |
2.0% |
|
3 |
Copilot |
3 |
1.5% |
|
4 |
o1 |
3 |
1.5% |
|
5 |
Sora |
2 |
1.0% |
ChatGPT остаётся самым узнаваемым брендом в ИИ — о нём пишут в 3 раза чаще, чем о Gemini. Claude упоминается всего 1 раз за весь период наблюдения.
О чём пишут: популярные темы 2025
Анализ заголовков и категорий показал следующие тренды:
|
Тема |
Статей |
% |
|
Бизнес и инвестиции |
17 |
8.5% |
|
AI Agents |
11 |
5.5% |
|
Coding / Программирование |
7 |
3.5% |
|
Поиск |
7 |
3.5% |
|
Генерация видео |
6 |
3.0% |
|
Open Source |
6 |
3.0% |
|
Reasoning / Мышление |
4 |
2.0% |
|
Роботы |
4 |
2.0% |
Самая популярная тема — деньги. Фандрайзинги, оценки стоимости компаний, инвестиционные раунды. AI Agents на втором месте — тема автономных агентов набирает обороты. Интересно, что про генерацию изображений писали всего 2 раза — хайп спал, это уже commodity.
Реальные возможности: что показывают тесты LMArena
Text (Текстовые задачи)
ТОП-10 моделей для работы с текстом
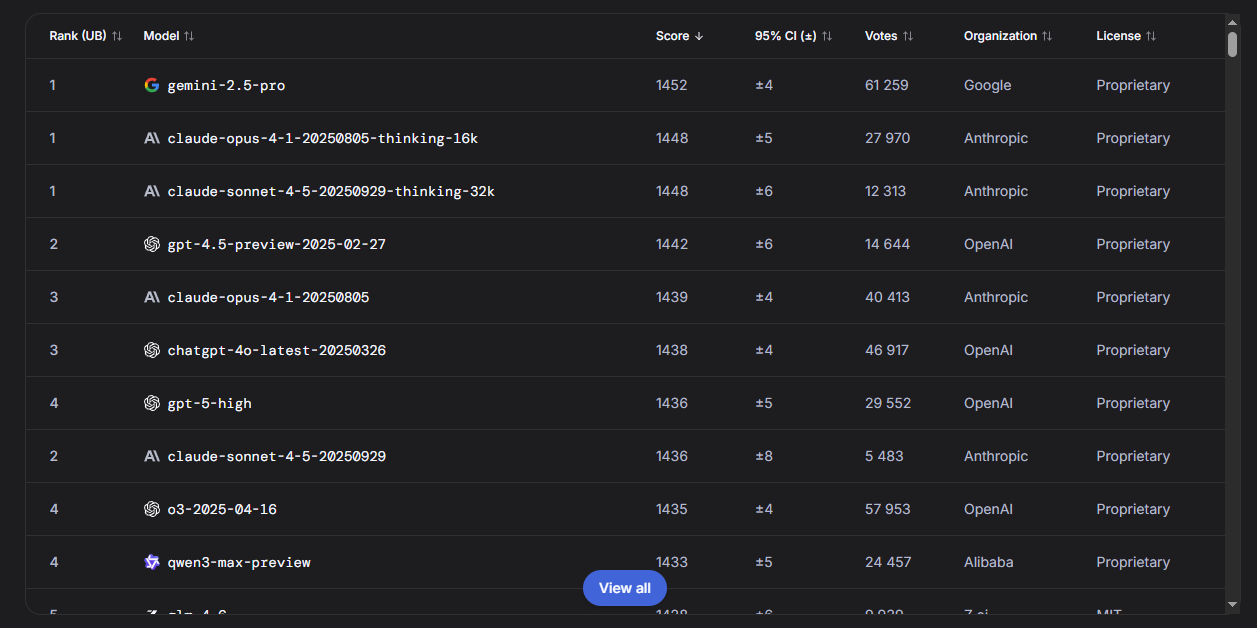
|
Место |
Модель |
Score |
Голосов |
|
1 |
Gemini 2.5 Pro |
1452 |
61 259 |
|
1 |
Claude Opus 4.1 (thinking) |
1448 |
27 970 |
|
1 |
Claude Sonnet 4.5 (thinking) |
1448 |
12 313 |
|
2 |
GPT-4.5 Preview |
1442 |
14 644 |
|
3 |
Claude Opus 4.1 |
1439 |
40 413 |
|
3 |
ChatGPT-4o Latest |
1438 |
46 917 |
|
4 |
GPT-5 High |
1436 |
29 552 |
|
2 |
Claude Sonnet 4.5 |
1436 |
5 483 |
|
4 |
o3 |
1435 |
57 953 |
|
4 |
Qwen3-max Preview |
1433 |
24 457 |
Тройка лидеров: Gemini 2.5 Pro и две версии Claude (Opus 4.1 и Sonnet 4.5) с режимом мышления. Разрыв минимальный — всё решают последние проценты качества.
WebDev (Веб-разработка)
Для разработчиков особенно важен рейтинг в создании кода
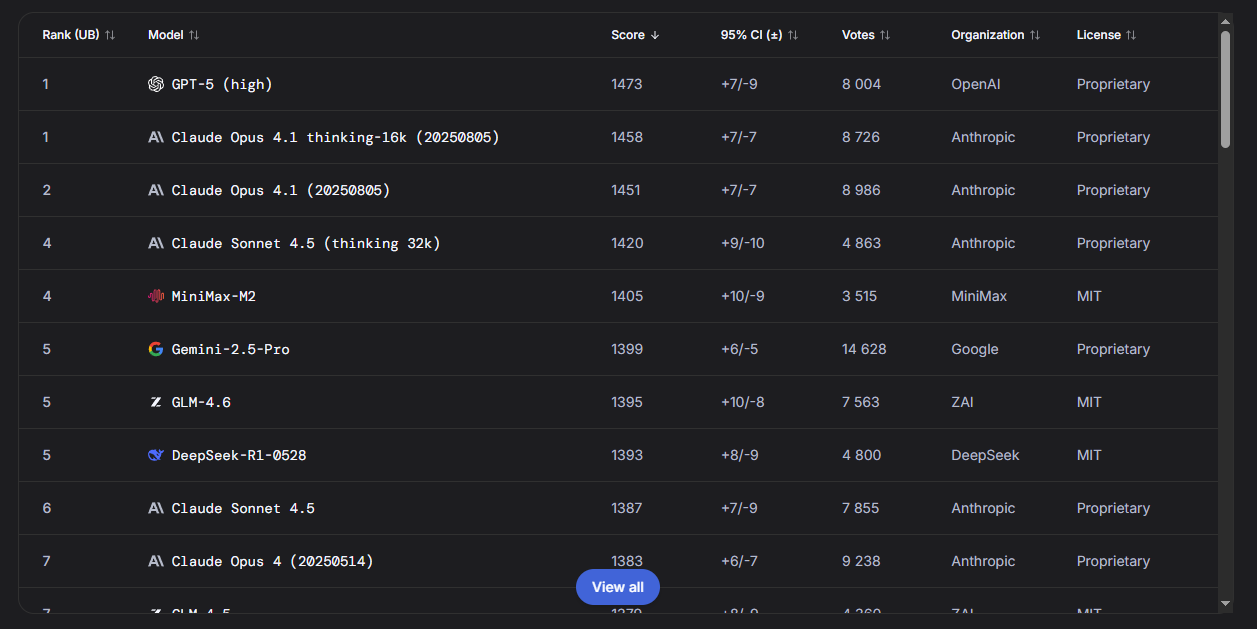
|
Место |
Модель |
Score |
Голосов |
|
1 |
GPT-5 High |
1473 |
8 004 |
|
1 |
Claude Opus 4.1 (thinking) |
1458 |
8 726 |
|
2 |
Claude Opus 4.1 |
1451 |
8 986 |
|
4 |
Claude Sonnet 4.5 (thinking) |
1420 |
4 863 |
|
4 |
MiniMax-M2 |
1405 |
3 515 |
Для кодинга лидируют GPT-5 и Claude. Anthropic занимает 3 из 5 первых мест.
Vision (Мультимодальность)
Работа с изображениями:
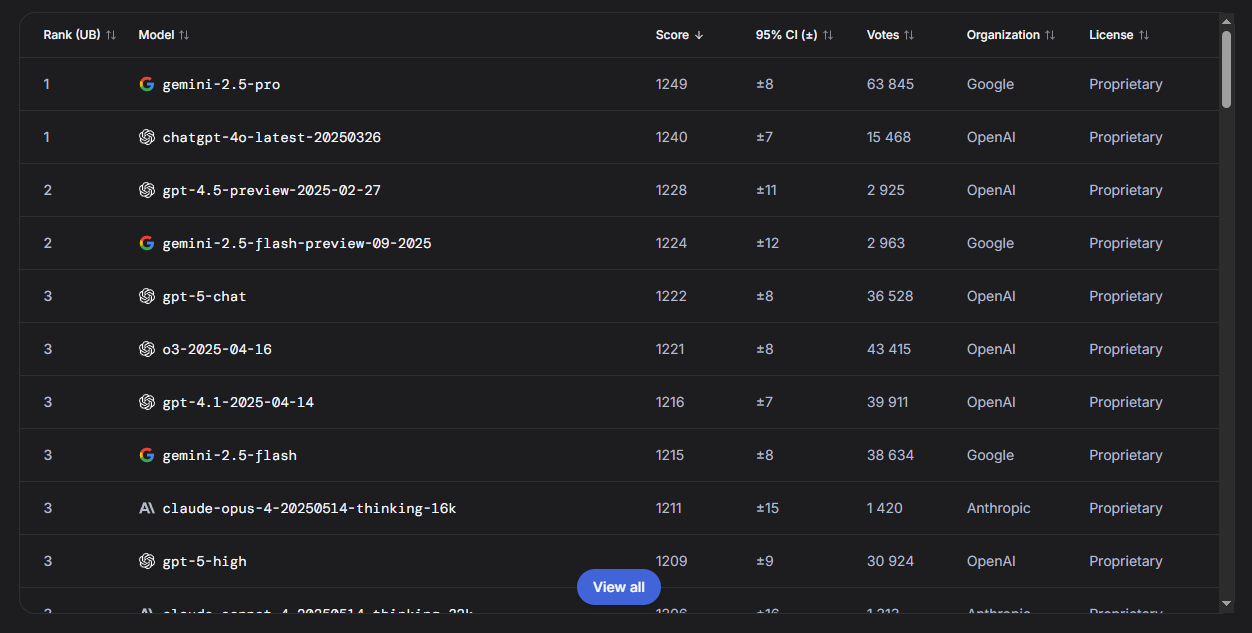
|
Место |
Модель |
Score |
Голосов |
|
1 |
Gemini 2.5 Pro |
1249 |
63 845 |
|
1 |
ChatGPT-4o Latest |
1240 |
15 468 |
|
2 |
GPT-4.5 Preview |
1228 |
2 925 |
|
2 |
Gemini 2.5 Flash Preview |
1224 |
2 963 |
Gemini — король мультимодальности. Google традиционно силён в работе с визуальным контентом.
Text-to-Image (Генерация изображений)
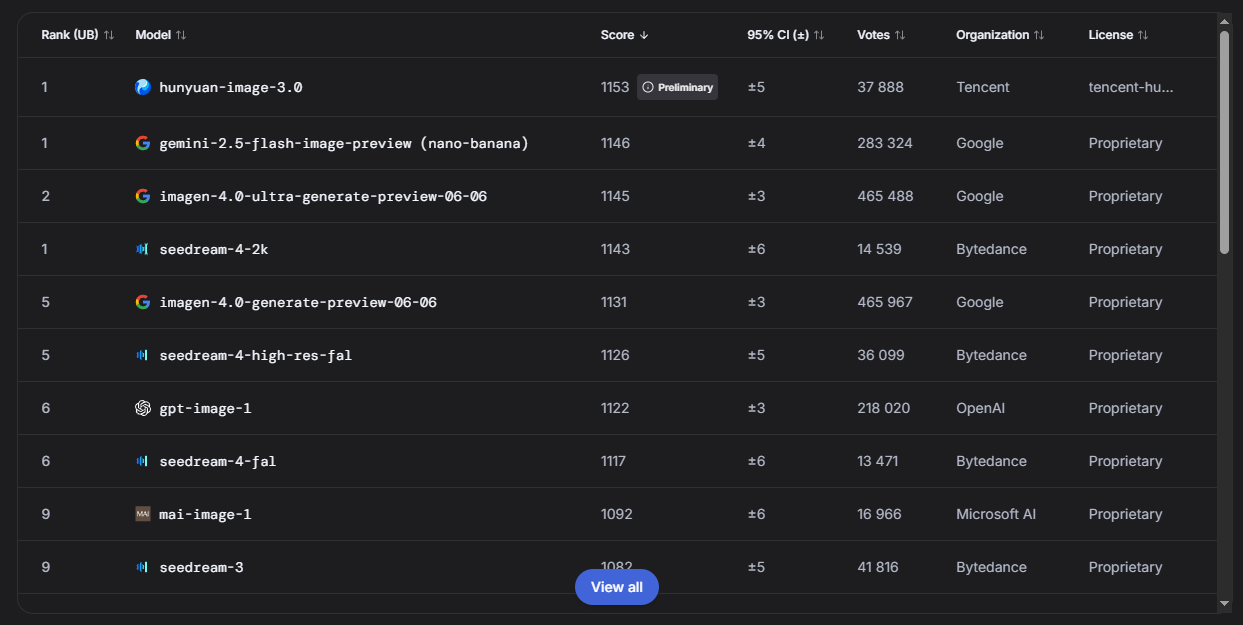
|
Место |
Модель |
Score |
Голосов |
|
1 |
Hunyuan Image 3.0 |
1153 |
37 888 |
|
1 |
Gemini 2.5 Flash Image |
1146 |
283 324 |
|
2 |
Imagen 4.0 Ultra |
1145 |
465 488 |
|
1 |
Seedream 4 2K |
1143 |
14 539 |
Китайская модель Hunyuan от Tencent делит первое место. Но кто о ней слышал в западных медиа?
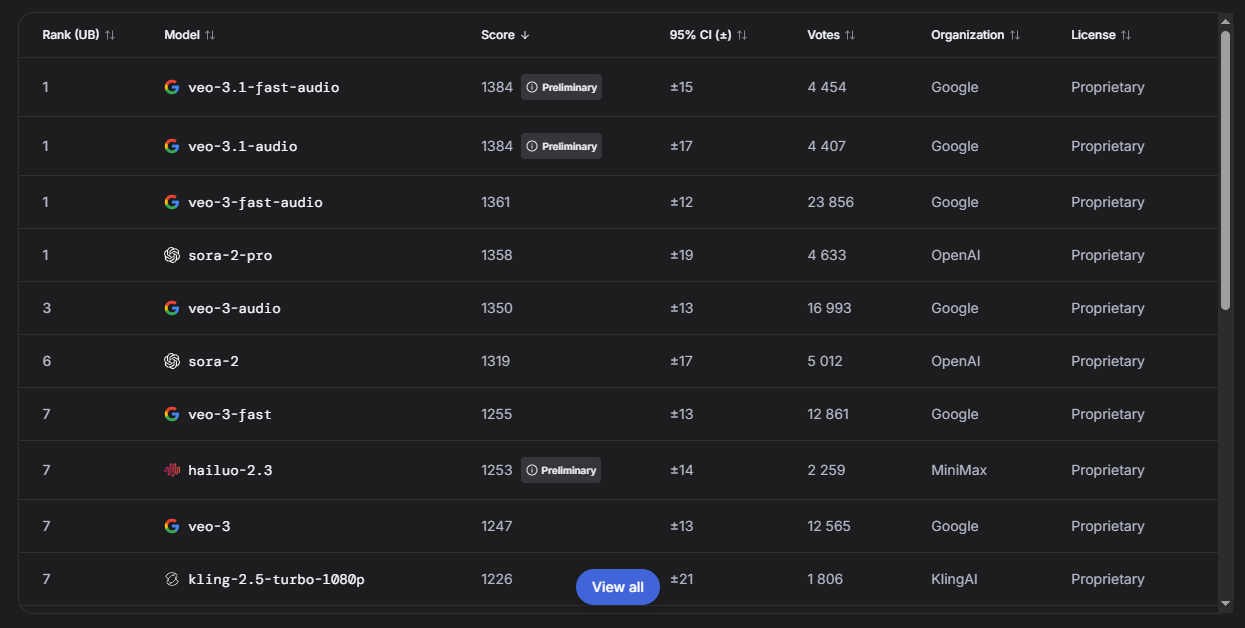
Text-to-Video (Генерация видео)
|
Место |
Модель |
Score |
Голосов |
|
1 |
Veo 3.1 Fast Audio |
1384 |
4 454 |
|
1 |
Veo 3.1 Audio |
1384 |
4 407 |
|
1 |
Veo 3 Fast Audio |
1361 |
23 856 |
|
1 |
Sora 2 Pro |
1358 |
4 633 |
Veo от Google и Sora от OpenAI делят лидерство. Но также отлично показывает себя китайская Hailuo.
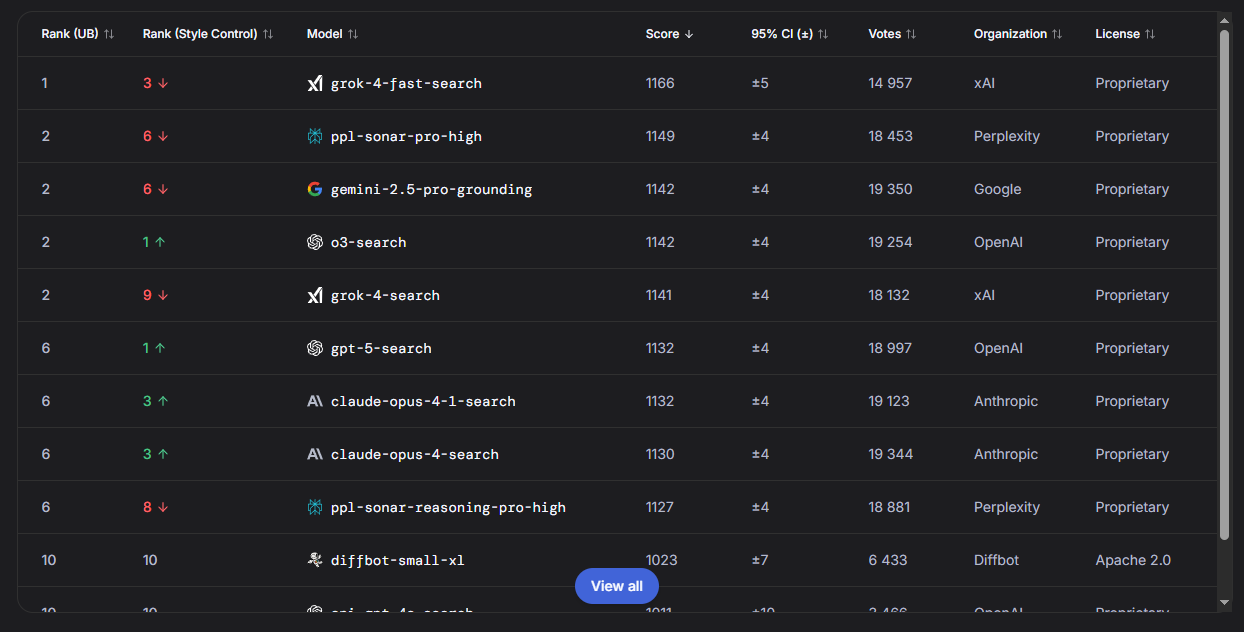
Search (Поиск)
|
Место |
Модель |
Score |
Голосов |
|
1 |
Grok 4 Fast Search |
1166 |
14 957 |
|
2 |
Perplexity Sonar Pro High |
1149 |
18 453 |
|
2 |
Gemini 2.5 Pro Grounding |
1142 |
19 350 |
|
2 |
o3 Search |
1142 |
19 254 |
Grok от xAI (Илона Маска) лидирует в поиске. Но о нём почти не пишут.
Сравнение: медиа vs реальность
Теперь самое интересное — сопоставим медийный шум с реальными возможностями.
Инсайт #1: OpenAI доминирует в новостях, но не в качестве
В медиа:
-
OpenAI — 28 упоминаний (14%)
-
ChatGPT — 13 упоминаний (6.5%)
-
Безусловный лидер по присутствию
В тестах:
-
ChatGPT-4o — только 3-6 место в текстовых задачах
-
GPT-5 в топе, но не на первом месте
-
Claude Opus 4.1 и Gemini 2.5 Pro впереди
Вывод: OpenAI отлично умеет работать с медиа и PR, но технологически уже не является безоговорочным лидером. Google и Anthropic догнали и местами обогнали.
Инсайт #2: Claude — скрытый чемпион
В медиа:
-
Anthropic — 3 упоминания (1.5%)
-
Claude — 1 упоминание (0.5%)
-
Почти невидим
В тестах:
- Claude Opus 4.1 — делит 1-3 места в Text
- Claude — 1-2 места в WebDev
- Claude — в топе по reasoning
Вывод: Самая недооценённая медиа компания. Anthropic делает великолепные модели, но совершенно не умеет их пиарить. Или не считает это приоритетом.
Инсайт #3: Китайские модели — терра инкогнита
В медиа:
-
DeepSeek — 0 упоминаний
-
Qwen — 0 упоминаний
-
Hunyuan — 0 упоминаний
-
О китайских мо��елях не пишут вообще
В тестах:
-
Qwen3-max — 4-е место в Text (1433 score)
-
Hunyuan Image 3.0 — 1-е место в генерации изображений
-
DeepSeek R1 — в топ-10 по WebDev
Вывод: Западные медиа игнорируют китайские модели, хотя они уже в мировом топе. Языковой и политический барьер работает в обе стороны.
Инсайт #4: Google недооценён, xAI переоценён
Google в медиа: 10 упоминаний (5%)
Google в тестах: Gemini 2.5 Pro — абсолютный лидер по Text и Vision
xAI в медиа: 1 упоминание (0.5%)
xAI в тестах: Grok 4 — лидер по Search
Оба недооценены медиа относительно их технологических достижений. При этом о каждом новом твите Илона про AI пишут все издания, но Grok тестируют единицы.
Инсайт #5: Тренды медиа ≠ тренды технологий
О чём пишут медиа (топ-3):
1. Бизнес/инвестиции (8.5%)
2. AI Agents (5.5%)
3. Coding (3.5%)
Что реально развивается (по LMArena):
1. Multimodal модели (Vision + Audio)
2. Reasoning / CoT модели (o1, o3, Claude thinking)
3. Генерация видео (Veo, Sora, Hailuo)
Медиа фокусируются на деньгах и агентах, а реальный прогресс идёт в мультимодальности и reasoning. Показательно: генерация изображений почти исчезла из новостей (1% статей), потому что стала обыденностью.
Практические выводы: какую модель выбрать
На основе тестов Chatbot Arena, вот мои рекомендации по выбору модели под разные задачи:
Для текстовых задач (письмо, анализ, общение)
Лучший выбор: Gemini 2.5 Pro или Claude Opus 4.1
Бюджетный вариант: Claude Sonnet 4.5 (отличное соотношение цена/качество)
Альтернатива: Qwen3-max (если работаете с китайским рынком)
Для программирования
Лучший выбор: GPT-5 High или Claude Opus 4.1 (thinking)
Быстрый вариант: Claude Sonnet 4.5
Неожиданность: MiniMax-M2 в топ-5
Для работы с изображениями (распознавание)
Лучший выбор: Gemini 2.5 Pro
Альтернатива: ChatGPT-4o Latest
Google здесь вне конкуренции.
Для генерации изображений
Лучший выбор: Hunyuan Image 3.0 или Seedream 4
Проверенный вариант: Imagen 4.0 Ultra от Google
Забудьте: DALL-E и Midjourney уже не в топе
Для генерации видео
Лучший выбор: Veo 3.1 от Google (с audio)
Альтернатива: Sora 2 Pro от OpenAI
Бюджетный: Hailuo 2.3 (из Китая)
Для AI-поиска
Лучший выбор: Grok 4 Fast Search
Альтернатива: Perplexity Sonar Pro
От гигантов: Gemini 2.5 Pro Grounding или o3 Search
Почему такой разрыв между медиа и реальностью?
Несколько факторов объясняют этот феномен
-
PR и маркетинг
OpenAI тратит огромные бюджеты на PR. Anthropic фокусируется на продукте. Результат: ChatGPT знают все, Claude — только профессионалы.
-
Timing
ChatGPT был первым массовым продуктом в эпоху LLM. Первопроходцы получают непропорционально много внимания, даже если их потом обгоняют.
-
Бизнес-новости интереснее технических
Журналистам проще написать про $100M раунд, чем разбираться в архитектуре transformer'ов. Отсюда фокус на инвестициях, а не на бенчмарках.
-
Западоцентричность медиа
TechCrunch, VentureBeat и MIT Technology Review — американские издания. Они пишут о своих компаниях. Китайские модели в топах, но о них просто не знают.
-
Бенчмарки сложны
Chatbot Arena — отличный инструмент, но он не попадает в новостную повестку. Статья "OpenAI привлёк $X млрд" соберёт больше просмотров, чем "Claude обогнал GPT на 12 пунктов ELO".
Что из этого следует для разработчиков
Несколько советов на основе этого анализа:
-
Не верьте хайпу — тестируйте сами
То, о чём больше всего кричат, не обязательно лучшее. Проверяйте модели на своих задачах.
-
Следите за бенчмарками, а не за новостями
Chatbot Arena, MMLU, HumanEval — эти метрики важнее громких пресс-релизов.
-
Смотрите на китайские модели
Qwen, DeepSeek, Hunyuan — они уже в мировом топе и часто бесплатны или дешевле западных аналогов.
-
Claude недооценён
Если вы всё ещё используете только ChatGPT, попробуйте Claude. Особенно для кода и сложных reasoning-задач.
-
Gemini — тёмная лошадка
Google незаметно сделал одну из лучших моделей. Особенно сильна в мультимодальности.
-
Используйте специализированные модели
Для поиска — Grok или Perplexity. Для видео — Veo. Для изображений — Hunyuan. Универсальные модели не всегда лучшие.
Заключение
Анализ 200 статей показал огромный разрыв между тем, о чём пишут tech-медиа, и реальными возможностями ИИ-моделей. OpenAI доминирует в новостях, но Claude и Gemini часто превосходят его в тестах. Китайские модели в топах, но о них никто не знает на Западе. Журналисты пишут про инвестиции, а настоящий прогресс происходит в reasoning и мультимодальности.
Главный вывод: в мире ИИ нельзя полагаться только на новости. Если вы разработчик, исследователь или просто интересуетесь технологиями — изучайте бенчмарки, тестируйте модели сами и следите за малоизвестными игроками. Часто именно они делают самые интересные вещи.
Я продолжаю отслеживать новости об ИИ и публикую самые важные и интересные в своём Telegram-канале Ai&I (https://t.me/chatgptdom_telegram_bot>). Там вы найдёте не только хайп, но и реальные технологические прорывы — на русском языке, кратко и по делу.
А какие модели используете вы? Совпадает ли ваш опыт с результатами LMArena? Делитесь в комментариях!
Все данные актуальны на начало ноября 2025 года.










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое