Фактчекинг за $0.09: GPT-5-mini + Perplexity sonar-pro в продакшене
Новости противоречат друг другу. Один источник пишет «завод встал», второй — «встала первая линия», третий копипастит статью двухлетней давности. Когда через твой пайплайн проходят сотни таких новостей в сутки, ручная верификация перестаёт масштабироваться.
Мы столкнулись с этим при построении новостного пайплайна StatCar — нишевого СМИ об автомобилях. Стандартные LLM не подходят — их знания устаревают на момент обучения. Вариант «LLM + web_search tool» рассматривали, но отказались: дороже и менее эффективно. Perplexity заточен под поиск — это его core competency.
Ниже — разбор того, как мы построили конвейер фактчекинга на базе OpenRouter и Perplexity. Расскажу, почему для Perplexity написали свой клиент вместо SpringAI, какие параметры поиска критичны и сколько это стоит в продакшене.
TL;DR
|
Компонент |
Решение |
|---|---|
|
Прослойка |
OpenRouter — обход геоблокировок + vendor-agnostic API |
|
Экстракция интентов |
gpt-5-mini (~$0.002-0.003/запрос) |
|
Поиск |
Perplexity sonar-pro ($0.09/фактчек) |
|
Фильтр качества |
Минимум 6 независимых источников — иначе на ручную проверку |
|
Парамет��ы поиска |
|
|
Клиент |
Свой WebClient — SpringAI строго валидирует ответы |
Архитектура: почему одной модели мало
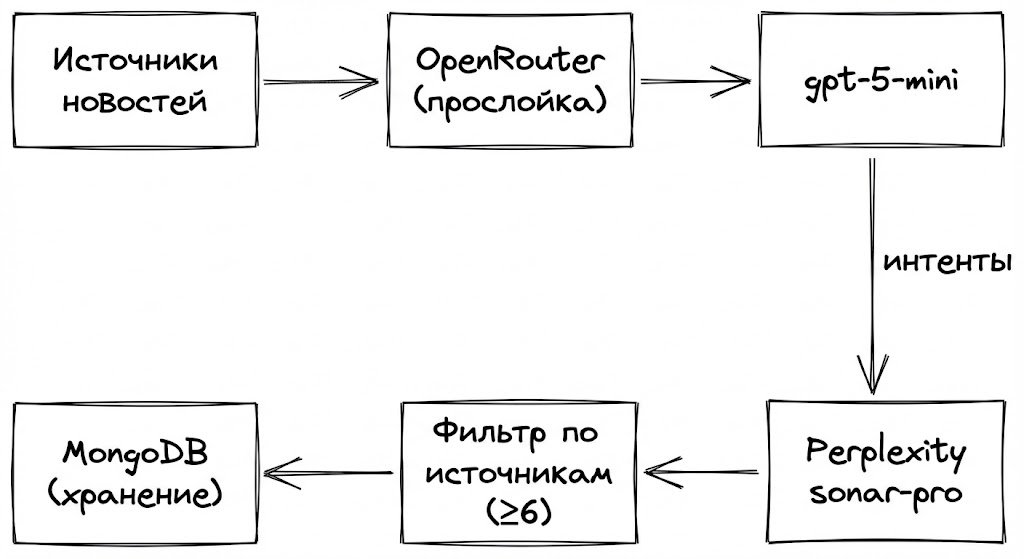
Прямой запрос в поисковую модель (мы выбрали Perplexity) работает плохо по двум причинам:
-
Цена. Гонять поисковую модель на каждый чих — дорого.
-
Фокус. Если скормить модели сырой текст новости на 3к знаков, она начинает искать всё подряд, теряя суть.
Поэтому мы разбили задачу на два этапа: выделение интентов (дешево) и глубокий поиск (дорого и качественно).
Этап 1. Экстракция интентов (OpenRouter + gpt-5-mini)
На входе у нас сырой текст. Нам нужно понять, что именно проверять. Для этого используем OpenRouter как единый шлюз.
Зачем прослойка?
|
Причина |
Описание |
|---|---|
|
Zero Vendor Lock |
Переезд с OpenAI на Anthropic или Google Gemini — правка одной строки в конфиге |
|
GeoIP и доступность |
Запросы идут к шлюзу OpenRouter — нет блокировок по IP (актуально для серверов в РФ) |
Для этой задачи gpt-5-mini хватает с головой. Она дешевая, быстрая и отлично понимает структуру JSON.
Системный промпт просит модель сформулировать 4-6 поисковых вопросов на естественном языке — не ключевые слова, а конкретные запросы, как если бы эксперт спрашивал коллегу:
system("""
Роль: Вы — Prompt Engineer для поисковой системы Perplexity.
Задача: Преобразовать сырой текст новости в набор четких поисковых интентов на естественном языке.
Входные данные:
Заголовок: {{NEWS_TITLE}}
Текст: {{NEWS_TEXT}}
Инструкция:
Вместо набора ключевых слов, сформулируй 4-6 предложений-вопросов на русском языке, которые охватывают суть новости и требуемые детали.
Эти вопросы будут отправлены в поисковик. Они должны звучать так, как эксперт спрашивает у коллеги или у Google.
Структура ответа (JSON):
Верни JSON строго следующего формата (без markdown):
{
"naturalLanguageQueries": "Текст, объединяющий запросы. Пример: \n1. Каковы официальные технические характеристики [Модель] и дата выхода? \n2. Какие последние финансовые показатели [Компании] за Q3 2025 и прогнозы аналитиков? \n3. Есть ли официальные комментарии [Директора] по поводу [События]? \n4. Сравнение [Новинки] с конкурентами [Конкурент 1] и [Конкурент 2] по цене и запасу хода."
}
Принципы составления вопросов (Natural Language Queries):
1. **Контекст:** Не просто «Toyota двигатель», а «Подробные характеристики нового двигателя Toyota, анонсированного в 2024 году».
2. **Специфика:** Если речь об инвестициях, спрашивай «Объем инвестиций [Компании] в [Проект] и источники финансирования».
3. **Проверка фактов:** Всегда добавляй вопрос на проверку: «Официальное подтверждение [События] в пресс-релизах [Компании]».
4. **Язык:** Вопросы должны быть строго на РУССКОМ языке.
ВАЖНО: Не используй общие фразы типа «Расскажи мне о новостях». Будь максимально конкретен.
""".trimIndent())

Пример ответа модели (для новости о Tesla FSD в Европе)
{
"naturalLanguageQueries": "1. Каков текущий статус сертификации системы Full Self-Driving (FSD) Tesla в странах ЕС: какие страны уже дали или близки к одобрению, какие конкретные требования регуляторов и ожидаемые сроки окончательного разрешения?\n2. Какие юридические, страховые и репутационные риски несёт Tesla при официальном признании её автомобилей полностью беспилотными в США; какие текущие расследования и судебные иски могут увеличить финансовую ответственность компании?\n3. Каковы точные данные о падении продаж Tesla за последние кварталы 2024–2025 годов (объёмы поставок, выручка, доля рынка) и какие факторы конкуренции и рыночные тренды объясняют это снижение?\n4. Какие инвестиции, технические достижения и практические проекты в области автопилота реализовали основные конкуренты Tesla (например, Waymo, Cruise/GM, Volkswagen, Hyundai и ведущие стартапы); как эти решения по безопасности, масштабируемости и коммерциализации сравниваются с FSD?\n5. Есть ли официальные подтверждения от Tesla или Илона Маска о стратегической ставке на автономное вождение: пресс-релизы, дорожные карты по внедрению FSD в Европе, прогнозы по влиянию на продажи и планы финансирования внедрения?\n6. Какие технические и производственные препятствия мешают массовой интеграции FSD в серийные автомобили Tesla (аппаратные требования, обучение нейросетей, тестирование, логистика обновлений) и какие сроки и инвестиции нужны для их преодоления?"
}
Этап 2. Поиск и верификация (Perplexity API)
Полученные запросы летят в Perplexity. Мы используем модель sonar-pro — она оптимизирована под поиск и агрегацию информации из множества источников.
Почему Perplexity, а не LLM + web_search?
Рассматривали вариант с web_search tool в обычных LLM (OpenAI, Anthropic, Google). Отказались по двум причинам:
-
Цена. Web search tool делает поиск и генерацию в одном запросе, но стоит дороже — вы платите и за поиск, и за токены модели. Perplexity оптимизирован под эту задачу и выходит дешевле.
-
Качество поиска. Perplexity заточен под агрегацию и сопоставление источников. Это его core competency, а не побочная фича.
Почему sonar-pro, а не sonar-reasoning-pro?
У Perplexity две «топовые» модели: sonar-pro и sonar-reasoning-pro. Разница принципиальная:
|
Характеристика |
sonar-pro |
sonar-reasoning-pro |
|---|---|---|
|
Главная задача |
Поиск и синтез текста |
Логика и вычисления (Chain of Thought) |
|
Цена (вход/выход) |
$3 / $15 за 1M токенов |
$2 / $8 за 1M токенов |
|
Контекст |
200K токенов |
128K токенов |
|
Скорость |
Высокая (100+ tok/s) |
Переменная (тратит время на «мысли») |
Для фактчекинга новостей нам не нужны цепочки рассуждений. Мы не решаем математические задачи и не пишем код. Наша задача — быстро найти информацию в 10-15 источниках и синтезировать её в структурированный отчёт. Это именно то, под что заточен sonar-pro:
-
Широкий контекст (200K) — можем скормить длинную новость + все найденные источники
-
Качество текста — модель лучше понимает нюансы языка и пишет связные саммари
-
Скорость — не тратим время на «размышления», сразу получаем результат
sonar-reasoning-pro имеет смысл, если вам нужно: посчитать финансовые показатели из найденных данных, сравнить противоречивые факты по сложной логике, или написать код на основе найденной документации.
Почему SpringAI нам не подошел
Изначально мы использовали spring-ai-starter-model-openai, полагаясь на заявленную совместимость Perplexity с API OpenAI.
В теории красиво: подключаешь стартер, инжектишь ChatClient — и в бой. На практике — ад с десериализацией. SpringAI строго валидирует ответ, а Perplexity позволяет себе вольности:
-
Структура
usageотличается от спецификации OpenAI — SpringAI падает сJsonMappingException -
Поле
search_resultsв ответе парсер не ждёт — ещё одинUnrecognizedPropertyException -
При ошибках 5xx структура ответа меняется непредсказуемо
Типичный лог при попытке использовать SpringAI с Perplexity:
com.fasterxml.jackson.databind.exc.UnrecognizedPropertyException:
Unrecognized field "search_results"
(class org.springframework.ai.openai.api.OpenAiApi$ChatCompletion),
not marked as ignorable
Мы столкнулись с поведением, похожим на issue #2442. Решение очевидное: для Perplexity написать свой клиент на WebClient, а SpringAI оставить для остальных провайдеров (OpenRouter, OpenAI). Код клиента на WebClient — около 80 строк против ~15 со SpringAI, но полный контроль над сырым JSON:
// Было (SpringAI) — не работает с Perplexity
val response = chatClient.call(prompt)
// Стало (WebClient) — работает
webClient.post()
.uri("/chat/completions")
.bodyValue(request)
.retrieve()
.bodyToMono(PerplexityResponse::class.java)
Запрос к Perplexity: борьба за структуру
Чтобы модель не писала эссе, а возвращала данные для бэкенда, мы используем JSON Schema в параметре response_format.
Важный нюанс: Perplexity возвращает поле search_results с title, url и date каждого источника. Это и есть ваши пруфы — без них модель бесполезна для фактчекинга.
Почему промпт устроен именно так (по документации Perplexity)
Наш промпт не случаен — мы следовали официальным рекомендациям. Вот ключевые принципы:
1. System prompt не влияет на поиск.
"The real-time search component of our models does not attend to the system prompt."
— Perplexity Docs: Prompt Guide
Поэтому в system prompt мы задаём только формат вывода и правила обработки, а поисковые запросы передаём в user prompt.
2. Никогда не просите URL в промпте — модель их галлюцинирует.
"Never ask for URLs or source links in your prompts. The generative model cannot see the actual URLs from the web search, which means any URLs it provides in the response text are likely to be hallucinated."
Вместо этого берём ссылки из поля search_results в ответе API. В промпте просим использовать индексы [1], [2], которые потом матчим с реальными URL из search_results.
3. Явно инструктируйте модель признаваться в незнании.
"LLMs are designed to be 'helpful' and may attempt to provide answers even when they lack sufficient information."
Поэтому в промпте явно пишем: "If specific details are not found, state 'Not available in search results' — don't guess."
4. Специфичность критична для качества поиска.
"Adding just 2-3 extra words of context can dramatically improve performance."
Именно поэтому первый этап (gpt-5-mini) генерирует не ключевые слова, а полноценные вопросы: "Каковы официальные сроки начала продаж Toyota Land Cruiser 250 в России?" вместо "Toyota Land Cruiser 250 цена".
5. Избегайте few-shot prompting.
"Few-shot prompting confuses web search models by triggering searches for your examples rather than your actual query."
Мы не даём примеры в промпте — только структуру ожидаемого JSON.
Параметры поиска: что и зачем
Помимо промпта, Perplexity API принимает параметры, которые критически влияют на качество результатов. Вот что мы используем:
private val DATE_FILTER_FORMAT = DateTimeFormatter.ofPattern("M/d/yyyy")
val options = RequestOptions(
model = "sonar-pro",
searchAfterDateFilter = LocalDate.now().minusDays(7).format(DATE_FILTER_FORMAT), // "12/1/2024"
searchBeforeDateFilter = LocalDate.now().format(DATE_FILTER_FORMAT), // "12/8/2024"
searchContextSize = "high", // Максимум контекста из каждого источника
searchLanguageFilter = "ru", // Только русскоязычные источники
userLocation = UserLocation(country = "RU") // Геолокация для релевантности
)
searchAfterDateFilter / searchBeforeDateFilter — фильтрация по дате публикации источников в формате M/d/yyyy. Для новостного фактчекинга критично: статья двухлетней давности не подтвердит сегодняшний релиз. Мы ставим окно в 7 дней.
Важно: В документации Perplexity есть параметр
search_recency_filterсо значениямиday,week,month. Выглядит удобнее, но он не работает. API принимает параметр без ошибок, но игнорирует его — модель возвращает источники любой давности. ИспользуйтеsearchAfterDateFilterиsearchBeforeDateFilter.
searchContextSize = "high" — модель вытягивает больше контекста из каждого источника. Это увеличивает точность, но и стоимость. Для фактчекинга оправдано.
searchLanguageFilter = "ru" — фильтруем только русскоязычные источники. Про российский авторынок пишут преимущественно российские СМИ.
userLocation = RU — Perplexity учитывает геолокацию при ранжировании. Российские источники получают приоритет для запросов о российском рынке.
Системный промпт для Perplexity
Промпт задаёт формат вывода (JSON), правила цитирования источников через индексы [1], [2], и инструкции по обработке конфликтов между источниками.
Полный системный промпт
val systemPrompt = """
You are a precise news research analyst. Your goal is to synthesize information
from search results into a valid JSON object.
**Core Rules:**
1. Output MUST be a single, valid JSON object. No markdown, no text before or after.
2. **citations:** Use citation indexes [1], [2] to reference sources in your summary.
3. **Accuracy:** If you find conflicting data, document it explicitly in `key_facts_aggregated`.
Example: "CONFLICT: Source [1] says X, while Source [2] says Y."
4. If specific details are not found, state "Not available in search results" — don't guess.
5. **Language:** The content of the JSON must be in RUSSIAN.
**JSON Structure:**
{
"search_topic": "Topic provided by user",
"analysis_summary": {
"main_event_summary": "Comprehensive summary of the event with citation indexes [1].",
"sources_used_indices": [1, 2, 3] // List the citation numbers used.
},
"compiled_information_for_next_step": {
"key_facts_aggregated": [
"Fact 1 with citation [1]",
"Fact 2 with citation [2]",
"CONFLICT: Source [1] says X, while Source [2] says Y."
],
"different_angles_found": "Description of perspectives or null.",
"key_quotes_found": [
{ "quote": "...", "attribution": "Speaker Name", "source_index": 1 }
],
"brief_context_found": "Background info or null.",
"forecasts_found": "Forecasts/expectations or null."
},
"article_draft_for_next_step": {
"suggested_title_base": "Russian Title",
"draft_text": "Structured news draft (150-250 words) integrating the facts found. Use citation indices [x] where appropriate."
}
""".trimIndent()
User prompt передаёт интенты с первого этапа:
User prompt
val userPrompt = """
Analyze the following automotive news event based on the search queries provided.
**Search Context & Specific Questions:**
${prefindPerplexityNewsResponse.naturalLanguageQueries}
**Instructions:**
1. **Verify Facts:** Cross-reference the information. Look for official confirmations, press releases, or major automotive news outlets.
2. **Be Specific:** Look for exact numbers, dates, technical specifications, and direct quotes.
3. **Handle Missing Info:** If the search results do not contain the specific details requested (e.g., exact price or release date), explicitly state in the JSON that this information was not found. Do not halluncinate.
**Output:** Provide ONLY the JSON object defined in the system prompt.
""".trimIndent()
JSON Schema передаётся отдельно через response_format. Ключевое поле — sources_used_indices: по нему мы фильтруем ответы с недостаточным количеством источников.
Полная JSON Schema
val jsonSchema = JsonSchema(
name = "news_search_result",
schema = mapOf(
"type" to "object",
"properties" to mapOf(
"search_topic" to mapOf("type" to "string"),
"analysis_summary" to mapOf(
"type" to "object",
"properties" to mapOf(
"main_event_summary" to mapOf("type" to "string"),
"sources_used_indices" to mapOf(
"type" to "array",
"items" to mapOf("type" to "integer")
)
),
"required" to listOf(
"main_event_summary",
"sources_used_indices"
)
),
"compiled_information_for_next_step" to mapOf(
"type" to "object",
"properties" to mapOf(
"key_facts_aggregated" to mapOf(
"type" to "array",
"items" to mapOf("type" to "string")
),
"different_angles_found" to mapOf("type" to "string"),
"key_quotes_found" to mapOf(
"type" to "array",
"items" to mapOf(
"type" to "object",
"properties" to mapOf(
"quote" to mapOf("type" to "string"),
"attribution" to mapOf("type" to "string"),
"source_index" to mapOf("type" to "integer")
),
"required" to listOf("quote", "source_index")
)
),
"brief_context_found" to mapOf("type" to "string"),
"forecasts_found" to mapOf("type" to "string")
),
"required" to listOf("key_facts_aggregated", "key_quotes_found")
),
"article_draft_for_next_step" to mapOf(
"type" to "object",
"properties" to mapOf(
"suggested_title_base" to mapOf("type" to "string"),
"draft_text" to mapOf("type" to "string")
),
"required" to listOf("suggested_title_base", "draft_text")
)
),
"required" to listOf(
"search_topic",
"analysis_summary",
"compiled_information_for_next_step",
"article_draft_for_next_step"
)
)
)
Если источников мало — новость, скорее всего, слух.
Подводные камни реализации
1. Таймауты и Retry-политика
Поисковые модели работают медленнее обычных LLM — нужно время на обход источников. Ответ может генерироваться 15–30 секунд. Дефолтные таймауты WebClient (часто 5-10 сек) приводят к обрыву соединения.
Плюс, Perplexity любит возвращать 429 (Too Many Requests), если у них пиковая нагрузка.
Наш конфиг на Kotlin + Reactor (Project Reactor) выглядит так:
webClient.post()
.uri("/chat/completions")
.bodyValue(request)
.retrieve()
.bodyToMono(PerplexityResponse::class.java)
.timeout(properties.timeout.read) // 5 минут — даем время на обход источников
.retryWhen(
Retry.backoff(
properties.retry.maxAttempts.toLong(), // 5 попыток
properties.retry.initialDelay // 1 секунда
)
.maxBackoff(properties.retry.maxDelay) // cap: 60 секунд
.jitter(0.5) // ±50% случайности
.filter { throwable ->
when (throwable) {
is WebClientResponseException -> {
throwable.statusCode == HttpStatus.TOO_MANY_REQUESTS ||
throwable.statusCode.is5xxServerError
}
else -> true // Сетевые ошибки тоже ретраим
}
}
)
В конфигурации мы вынесли таймауты и retry-параметры в отдельный properties-класс:
data class TimeoutConfig(
val connect: Duration = Duration.ofSeconds(30),
val read: Duration = Duration.ofMinutes(5), // Ключевое: 5 минут на чтение
val write: Duration = Duration.ofMinutes(2)
)
data class RetryConfig(
val maxAttempts: Int = 5,
val initialDelay: Duration = Duration.ofSeconds(1),
val maxDelay: Duration = Duration.ofSeconds(60)
)
2. Другие грабли
|
Проблема |
Симптом |
Решение |
|---|---|---|
|
Пустой |
Модель возвращает пустой массив, хотя в тексте есть ссылки |
Фильтруем → помечаем как «требует ручной проверки» |
|
Rate limiting без |
429 без заголовка о времени ожидания |
Exponential backoff с jitter решает проблему |
Экономика вопроса
Главный вопрос, который мне задают коллеги: не проще ли посадить студента проверять факты?
Давайте посчитаем. Мы используем sonar-pro — поисковая модель с высоким качеством агрегации. В продакшене StatCar мы проверяем не всё подряд, а только потенциально вирусные или спорные инфоповоды (около 35–40 проверок в день).
|
Показатель |
Значение |
|---|---|
|
Проверок в день |
35–40 |
|
Дневной расход |
~$3.6 |
|
Месячный бюджет |
~$110 |
|
Стоимость одного фактчека |
$0.09 |
9 центов. За эти деньги мы получаем структурированный отчёт с пруфами за 30 секунд. Редактор потратит на поиск первоисточников, сверку цифр и формулировку вывода минимум час. Даже при минимальной зарплате это кратно дороже.
Когда это НЕ работает
Важно понимать ограничения подхода:
|
Ограничение |
Причина |
Решение |
|---|---|---|
|
Breaking news (первые 2-4 часа) |
Perplexity индексирует веб с задержкой |
Ручная проверка или ожидание |
|
Нишевые темы (<6 источников) |
Модель галлюцинирует при недостатке данных |
Фильтр |
Итого
Что получили
|
Метрика |
Значение |
|---|---|
|
Время фактчека |
30 сек vs час ручной работы |
|
Стоимость |
|
|
Прозрачность |
Каждый факт привязан к источнику через |
 110/месяц на 1200 проверок)
110/месяц на 1200 проверок)Технические решения
|
Решение |
Результат |
|---|---|
|
OpenRouter вместо прямых интеграций |
Миграция между провайдерами за 1 строку конфига |
|
Свой WebClient вместо SpringAI |
Полный контроль над ответом Perplexity |
|
Параметры поиска |
|
|
Фильтрация по источникам |
Отсев слухов и непроверенной информации |
Главный урок
Perplexity API — рабочий инструмент для автоматического фактчекинга в продакшене. Фильтр по количеству источников отсекает галлюцинации эффективнее, чем любые промпт-хаки.
В продакшене StatCar эта схема работает второй месяц без критичных сбоев.
Если делаете что-то похожее — делитесь опытом в комментариях, интересно сравнить подходы.










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое