Гибридный подход к контексту: как сделать LLM-агентов быстрее и дешевле
Команда AI for Devs подготовила перевод статьи о том, как AI-агенты на базе LLM тратят лишние деньги из-за разрастающегося контекста и как простое маскирование наблюдений нередко работает лучше сложного LLM-суммирования. Авторы предлагают гибридный метод, который делает агентов дешевле и надёжнее без дообучения модели.
Представьте, что вы работаете над проектом и записываете буквально каждую мысль, эксперимент и неудачу. Проходит время — и заметок становится столько, что поиск чего-то полезного занимает больше сил и времени, чем сама работа. С похожей проблемой сталкиваются пользователи агентных систем в сфере разработки: агенты «делают заметки» по каждому сгенерированному результату, итеративно добавляя его в контекст. В итоге накапливаются гигантские — и дорогие — объёмы памяти.
Огромный контекст создаёт проблемы по нескольким причинам. Во-первых, AI-модели тарифицируются по количеству слов (токенов), и чем больше контекст, тем стремительнее растут затраты. Если позволить контексту расти бесконтрольно, есть риск быстро превысить контекстное окно современных LLM. Кроме того, реальный эффективный объём контекста у агента довольно мал (см. эту статью и эту статью).
Получается, что контекст, который агент сам себе генерирует, очень быстро превращается в шум, а не в полезные сведения. Можно посмотреть на это и иначе: контексты растут настолько стремительно, что становятся крайне дорогими, но при этом почти не улучшают качество выполнения последующих задач. Сейчас мы расходуем ресурсы, а отдача остаётся заметно ниже оптимальной.
Если растущий контекст — проблема, то какие меры вообще предпринимаются для его контроля? Удивительно мало — учитывая масштабы последствий. Пока что внимание в основном сосредоточено на улучшении планирования агента за счёт увеличения объёмов данных и разнообразия сред (см. статьи 1 и 2), а также за счёт улучшенных стратегий планирования и более эффективных методов поиска (см. статьи 1 и 2).
Однако в исследованиях всё ещё есть существенный пробел, когда речь идёт об эффективности управления контекстом. Наши исследователи закрыли этот пробел — они выполнили эмпирическое исследование основных подходов к эффективному управлению контекстом, а также предложили новый гибридный метод, который позволяет значительно снизить стоимость. Эта работа — часть магистерской диссертации Тобиаса Линденбауэра в лаборатории Software Engineering and AI Технического университета Мюнхена (TUM). Мы представим результаты на воркшопе Deep Learning 4 Code, который входит в программу конференции NeurIPS 2025 и пройдёт 6 декабря 2025 года в Сан-Диего.
В этой статье мы расскажем:
-
О двух основных подходах к управлению контекстом: маскировании наблюдений и суммировании с помощью LLM.
-
О нашем эксперименте и его результатах, где мы сравнили эти два подхода с базовым решением.
-
О нашем гибридном методе и о том, как шире применять результаты исследования.
Подходы к управлению контекстом
Когда AI-агенты решают сложные задачи программирования, им нужно помнить, что они делали раньше: какие файлы читали, какой код тестировали, как рассуждали об ошибках. Эта «память» и есть контекст, который помогает агентам эффективнее рассуждать. Но управлять этой памятью — значит балансировать между тем, чтобы дать модели достаточно информации для чёткого мышления и при этом не завалить её лишним шумом.
В последние годы появилось несколько исследований, в которых подробно изучается, как размер контекстного окна влияет на работу модели (например, исследование 2024 года и исследование 2025 года). Эти работы последовательно показывают, что по мере роста контекста языковые модели всё хуже используют весь полученный объём сведений. Хотя управление контекстом напрямую влияет и на качество работы агента, и на стоимость его использования, в большинстве исследований оно всё ещё рассматривается скорее как инженерная деталь, чем как ключевая научная проблема.
Сегодня в state of the art-подходах существует два основных способа решать задачу управления контекстом. Важно отметить, что первый подход более новый и продвинутый: его впервые представил OpenHands, и сейчас он используется в коммерческих SE-агентах Cursor и Warp. Второй же подход — более старый и более простой.
-
LLM-суммирование: короткие сводки генерирует другая модель.
-
Маскирование наблюдений: устаревшая или менее важная информация скрывается.
Оба подхода сохраняют важные части контекста — в этом причина того, что они вообще работают. Главное различие — в том, как они это делают. Ниже изображение, демонстрирующее разницу, а затем текст подробно её разбирает.
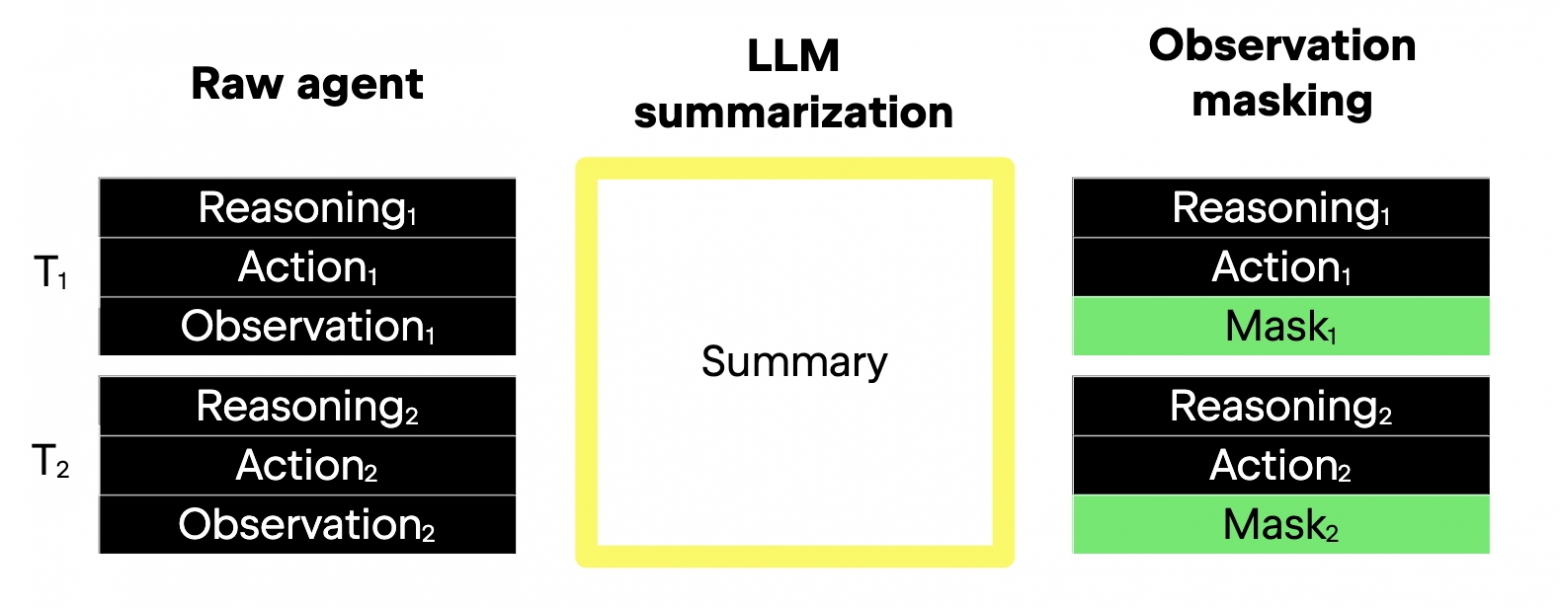
На левой стороне изображён базовый процесс — raw agent (для простоты подсказки опущены). Каждый шаг, обозначенный T1 и T2 в левой части, состоит из трёх элементов: рассуждений, действия и наблюдения.
В центре показано LLM-суммирование. Оно уменьшает детализацию всех трёх элементов шага, по сути сжимая длинную историю, которая со временем накапливается (то есть траекторию), в компактную форму. Жёлтая рамка обозначает суммарное представление первых двух шагов — T1 и T2.
Справа показано, как маскирование наблюдений воздействует только на наблюдения среды, но сохраняет в полном виде историю действий и рассуждений. Скрывается лишь третий элемент шага — здесь он выделен зелёным. Учитывая, что в типичном шаге SE-агента основная масса объёма приходится именно на наблюдения, логично, что этот подход уменьшает разрешение именно этого элемента. Агент при этом сохраняет доступ к своим прежним рассуждениям и решениям, но больше не вынужден заново обрабатывать огромные объёмы многословных логов или полные дампы файлов из прошлых шагов.
Ещё одно различие между подходами касается бесконечных контекстов. Теоретически LLM-суммирование позволяет бесконечно масштабировать число шагов, не раздувая контекст до бесконечности — благодаря повторным суммированиям, которые не дают контекстному окну превысить допустимые пределы. Маскирование наблюдений значительно снижает скорость роста контекста, но если количество шагов будет расти бесконечно, то и контекст при таком подходе тоже будет расти без ограничений.
Ниже представлена таблица с плюсами и минусами каждого подхода.

В последнее время несколько исследовательских групп представили собственные инструменты управления контекстом и изучили их эффективность. Последние работы включают:
-
MEM1, где исследовалась динамическая работа с состоянием для задач вроде многошагового ответа на вопросы и навигации по вебу. Однако эта работа не сравнивалась с более простыми методами на базе пропуска, такими как маскирование наблюдений, и использовала относительно короткие и лёгкие тесты (всего несколько сотен токенов), а не длинные траектории, характерные для SE-агентов. Обратите внимание: этот подход требует обучения модели.
-
Вариант подхода на базе LLM-суммирования, призванный улучшить управление контекстом SE-агентов. Но он тоже не включал сравнение с более простым методом маскирования наблюдений. Ближайшая альтернатива — Delete baseline — просто удаляет целые шаги диалога вместо их суммирования. Это может казаться эффективным, но поскольку такие агенты большую часть времени взаимодействуют со средой, полное удаление шагов нарушает их линию рассуждений и снижает качество работы.
-
Подход с маскированием наблюдений, который показал впечатляющие результаты в задачах обучения с подкреплением и в агентах, управляющих компьютером. И здесь модель требуется обучать.
Примечание: хотя первый из этих подходов предшествовал нашему исследованию, два других были опубликованы уже после его завершения.
Несмотря на интересные результаты этих работ, многого ещё предстоит узнать о том, какие стратегии действительно оптимальны для эффективного управления контекстом. В нашем исследовании мы поставили вопрос: действительно ли нужны сложные методы суммирования? Чтобы это проверить, мы провели эксперименты с SWE-agent и OpenHands и оценили, насколько хорошо работают более простые техники — об этом расскажем в следующем разделе.
Наш эмпирический взгляд на современные подходы к управлению контекстом
В экспериментах мы протестировали три стратегии работы с памятью. Вот эти стратегии — первая служит базовой линией, а две остальные являются основными объектами исследования:
-
Контекст растёт без ограничений — raw agent
-
Обрезание старых наблюдений с заменой на заглушки — маскирование наблюдений
-
Использование отдельной модели для суммирования прошлых шагов — LLM-суммирование
В качестве базового варианта мы рассмотрели raw agent на основе scaffold’ов ReAct и CodeAct. В этих фреймворках траектория агента — это последовательность взаимодействий со средой, и контекст при этом никак не ограничен.
Для двух основных исследуемых подходов мы проанализировали их популярные реализации в Open source-решениях:
-
Маскирование наблюдений через скользящее окно (SWE-agent):
-
сохраняет историю рассуждений и действий агента полностью;
-
заменяет старые наблюдения на заглушки, если они выходят за пределы фиксированного окна — по сути сообщая модели: «некоторые подробности опущены для краткости».
-
-
LLM-суммирование на основе промптов (OpenHands):
-
использует отдельную языковую модель-суммаризатор, которая сжимает старые взаимодействия (наблюдения, действия, рассуждения) в краткие сводки;
-
всегда оставляет самые свежие шаги нетронутыми.
-
Предварительные эксперименты показали: чтобы корректно сравнить ограниченный по размеру контекст при LLM-суммировании с медленно, но всё же неограниченно растущим контекстом при маскировании наблюдений, нужно использовать длинные траектории с большим числом шагов (подробнее в приложении к нашей статье). Поэтому в основных экспериментах мы позволяли агентам работать до 250 шагов. В варианте маскирования наблюдений оптимальным оказалось окно в 10 последних шагов — оно давало лучшую комбинацию качества и экономичности. В варианте LLM-суммирования мы раз за разом суммировали 21 шаг, при этом последние 10 всегда хранили полностью.
Кроме того, мы использовали самые современные модели — как открытые (Qwen3), так и проприетарные (Gemini 2.5 Flash), с размерами от 32B до 480B параметров; покрыли при этом и режимы с «мышлением», и без него. Все эксперименты выполнялись на наборе SWE-bench Verified, по 500 инстансов на каждую конфигурацию. Подробности см. в разделе 3 статьи.
Маскирование наблюдений: просто, но эффективно
Как описано в предыдущем разделе, в наших экспериментах мы изучили три стратегии управления памятью. Первая служит базовым вариантом, а две другие — основными объектами исследования. Главный вывод: маскирование наблюдений оказывается эффективнее и надёжнее LLM-суммирования.
-
Контекст растёт без ограничений — raw agent
-
Обрезание старых наблюдений с заменой на заглушки — маскирование наблюдений
-
Использование отдельной модели для суммирования прошлых шагов — LLM-суммирование
И маскирование наблюдений, и LLM-суммирование стабильно сокращают затраты более чем вдвое по сравнению с базовым вариантом, где память агента никак не ограничивается. Такие ориентированные на эффективность стратегии резко уменьшают рост контекста — и при этом не ухудшают способность агентов решать задачи.
Удивительно, но простой метод маскирования наблюдений оказался не только дешевле: он нередко работал на уровне или даже немного лучше, чем LLM-суммирование. В четырёх из пяти тестовых сценариев агенты с маскированием наблюдений тратили меньше средств на задачу — и часто показывали лучшую результативность.
Например, мощная модель Qwen3-Coder 480B показывала рост доли решённых задач на 2,6% по сравнению с полностью неуправляемым контекстом — при этом в среднем была на 52% дешевле. В других сценариях LLM-суммирование давало сопоставимые результаты, но почти никогда не превосходило маскирование. Даже разница в пару-тройку центов на задачу имеет значение при масштабных развёртываниях.
Различия в зависимости от конкретного агента
Нам также было важно понять, можно ли обобщить результаты на другого агента — с теми же параметрами, но на меньшей выборке. Для этого мы провели дополнительные тесты с агентом OpenHands, сравнив оба подхода на слайсе SWE-bench Verified (50 инстансов вместо 500). Агент был ограничен моделью Gemini 2.5 Flash без режима мышления.
Дополнительные тесты включали реализацию оптимального значения для SWE-agent в контексте OpenHands, наблюдение значимых различий в работе, а затем корректировку параметров, чтобы вернуть производительность на исходный уровень. Мы обнаружили, что маскирование наблюдений сопоставимо с LLM-суммированием и по стоимости, и по качеству — но только после настройки гиперпараметра окна для каждого конкретного типа агента.
Что значит «настроить окно маскирования»? Каждый агент хранит историю взаимодействий по-своему. В нашем исследовании SWE-agent (с маскированием) пропускает неудачные попытки повтора, тогда как OpenHands (с суммированием) включает все шаги.
Если считать последние 10 шагов контекста, различия в истории могут быть огромными. Если агент проваливается 10 раз подряд, окно контекста OpenHands будет состоять исключительно из ошибок — что может полностью сбить агента с толку.
Поэтому агентам вроде OpenHands действительно нужно расширять окно, чтобы не ухудшать качество. Настройка размера окна позволяет учитывать такие особенности и корректировать его, когда это необходимо.
LLM-суммирование и удлинение траекторий
Мы очень хотели понять, почему LLM-суммирование — более сложный и «умный» подход — зачастую менее экономичный, чем простое маскирование. И выяснили интересную деталь: при использовании суммирования агенты чаще работают дольше, что ведёт к росту затрат и снижению общей эффективности.
Данные показали, что для моделей вроде Gemini 2.5 Flash LLM-суммирование увеличивало среднюю длину траектории до 52 шагов, что на 15% дольше, чем при маскировании. Для Qwen3-Coder 480B — та же картина: траектории удлинялись примерно на 15% по сравнению с raw agent и на 13% — по сравнению с маскированием.
Почему так? Похоже, что LLM-сводки «сглаживают» или скрывают сигналы, которые указывали бы агенту, что задачу уже пора считать нерешаемой. Агент продолжает попытки, хотя обычно он бы давно остановился (см. исследование о плато успешности).
То есть сводки, призванные сделать историю аккуратнее, могут невольно побуждать агента тратить больше шагов без повышения качества. Иногда простота действительно работает лучше — и эффективнее.
И это ещё не всё: каждый раз, когда агент запрашивает сводку, он делает дорогой API-вызов, обрабатывающий значительный фрагмент траектории. Эти обращения стоят недёшево, иногда составляя более 7% общей стоимости. Поскольку каждый вызов работает с уникальным участком истории, возможности кеширования практически нет. Если вычесть стоимость генерации сводок, разница в эффективности между LLM-суммированием и маскированием заметно сокращается.
Итог: оба подхода уменьшили затраты примерно вдвое по сравнению с отсутствием контроля, но простота чаще побеждает в общей эффективности и стабильности. Даже если LLM-суммирование звучит «умно», на практике оно оказывается дороже и не даёт надёжного выигрыша. Это говорит о том, что многие современные AI-агенты могли бы снизить расходы, если бы меньше полагались на суммаризацию или использовали более изобретательные гибридные методы.
Наш гибридный подход: ещё больше эффективности
После того как мы увидели, что и маскирование наблюдений, и LLM-суммирование показывают себя весьма достойно — причём маскирование часто оказывается не хуже, а то и лучше суммирования, — мы решили проверить: а что если объединить сильные стороны обоих методов? Тем более что, как видно из таблицы выше, их преимущества дополняют друг друга.
Наш гибридный метод работает так: маскирование наблюдений выступает первой линией обороны от разрастания контекста. Мы выбрали именно его в качестве основы, потому что оно быстрое и дешёвое: старые шумные выводы инструментов заменяются заглушками, а агент сохраняет только действительно важные части истории.
Но вместо того чтобы полностью отказаться от суммирования, гибридная система иногда подключает LLM-суммаризацию как последний рубеж, когда контекст становится действительно громоздким. В нашей настройке агент использует маскирование почти на всех шагах, а суммирование вызывается только после накопления крупного блока шагов — при достижении определённого значения, задаваемого гиперпараметром.
Преимущества нашего гибридного подхода:
-
Агент быстро экономит за счёт маскирования — особенно в начале, когда задача ещё короткая и контекст не успел разрастись.
-
Даже для очень длинных или сложных задач периодическое суммирование не даёт памяти выйти из-под контроля — и при этом не тратит лишнее на генерацию сводок там, где они не нужны.
-
Поскольку метод не требует обучения модели (то есть изменения весов), его можно применять к любым существующим моделям — включая GPT-5 и Claude. Это даёт немедленную экономию даже там, где обучение попросту невозможно. Насколько нам известно, конкурентные подходы таким свойством не обладают.
Как уже отмечалось выше, настройка гиперпараметров имеет большое значение — и в гибридном методе это тоже критично. Мы подбирали и размер окна маскирования, и количество шагов до вызова суммаризации, подстраивая оба параметра под конкретного агента или конкретную задачу. Когда мы пробовали использовать настройки, подходящие для одного агента, в другом сценарии результаты иногда ухудшались.
Мы тщательно протестировали метод, и результаты подтверждают наши выводы. На сложном бенчмарке SWE-bench-Verified и при использовании огромной модели Qwen3-Coder 480B наш гибрид снизил стоимость на 7% по сравнению с чистым маскированием и на 11% по сравнению с одним только LLM-суммированием. При этом доля успешно решённых задач выросла примерно на 2,6 процентных пункта, а экономия по бенчмарку составила до 35 долларов — что существенно при масштабном запуске агентов.
Эффективное управление контекстом
В этом исследовании мы подробно изучили разные способы управления растущим контекстом AI-агентов, протестировав их на широком спектре моделей и фреймворков. Нам также удалось стабильно воспроизводить результаты при условии достаточно длинных траекторий и внимательной настройки параметров.
Основные выводы:
-
Игнорировать ориентированные на эффективность методы управления контекстом — значит игнорировать важные способы снизить затраты.
-
Если вам нужны агенты, которые работают и точно, и экономно, не стоит полагаться на один подход — наш гибрид объединяет сильные стороны маскирования наблюдений и LLM-суммирования.
В дополнение к статье мы выложили код в открытый доступ. Попробуйте его и оцените разницу в управлении контекстом: Посмотреть код
Русскоязычное сообщество про AI в разработке

Друзья! Эту статью подготовила команда ТГК «AI for Devs» — канала, где мы рассказываем про AI-ассистентов, плагины для IDE, делимся практическими кейсами и свежими новостями из мира ИИ. Подписывайтесь, чтобы быть в курсе и ничего не упустить!










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое