Стоит ли обжаловать решение суда? Битва AI-титанов в 2026 году
Как разработчик постоянно ищу способы улучшить качество прогнозов своего сервиса, который анализирует судебные документы (иски, решения судов), и выдаёт прогноз исхода. А с недавних пор производит также оценку шансов на обжалование судебных актов. Качество этого прогноза - core value.
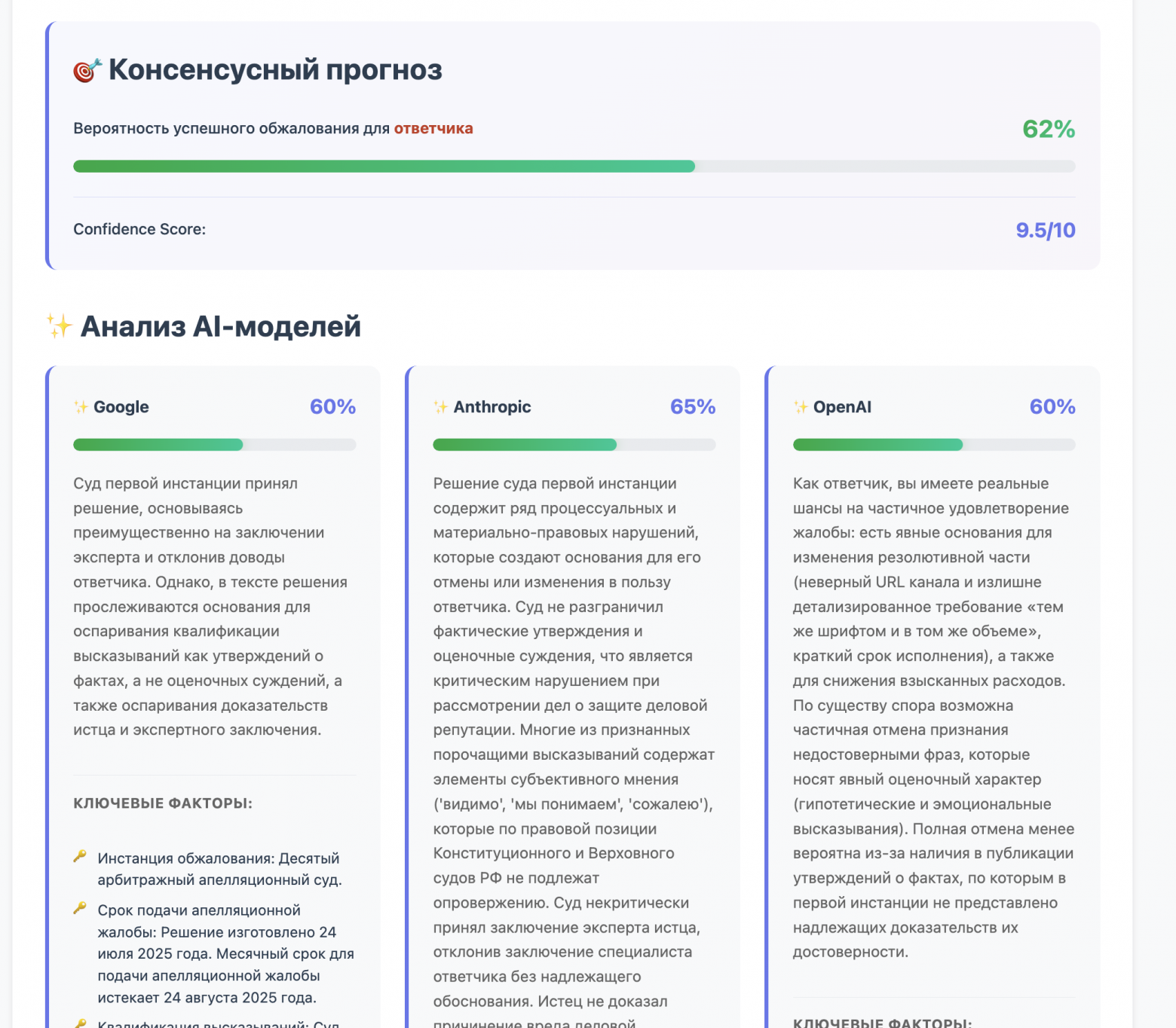
Недавно на рынке произошло мощное обновление всей "большой тройки" LLM. Я решил провести исследование и сравнить самые свежие версии моделей от Anthropic, OpenAI и Google, чтобы понять, кто из них лучше всего справляется с ролью "LLM as real Judge". Причем только в части оценки шансов в апелляции.
Кто участвовал в тесте?
Для чистоты эксперимента я взял самые актуальные модели (по состоянию на февраль 2026 года): Claude Sonnet 4.6 (Anthropic) с улучшенным long-context reasoning (до 1М токенов), GPT-5.2 Pro / Thinking (OpenAI), Gemini 3.1 Pro (Google).
Как я их проверял
Здесь все достаточно просто. Собрал датасет из реальных завершенных судебных дел из "Моего арбитра", где был известен исход первой инстанции и результаты апелляции - старался равномерно взять дела разных категорий (споры о признании договоров недействительными, дела о защите репутации и проч.). Принципиальный момент: все решения — строго за последние полгода, чтобы повысить вероятность их отсутствия в обучающих выборках.
Чтобы не сжечь бюджет на API и время на разметку, я разделил тестирование на этапы. Для стартового smoke-теста (проверить, что модель отдаёт валидный JSON и понимает роли сторон) хватило 30 ручных примеров: 15 отменённых апелляцией решений и 15 устоявших. Но для более достоверного Brier Score и графиков калибровки я собрал MVP-бенчмарк из 150 дел (только арбитражные решения). Здесь возник классический trade-off: писать автоматический парсер для kad.arbitr.ruили скачать вручную? В результате - потратил 2 часа на ручной сбор датасета. В будущем, для продакшн-мониторинга деградации промптов, думаю, расширить этот датасет до 400+ дел.
Каждой модели я подавал на вход:
-
Текст решения суда первой инстанции
-
Выверенный предыдущими тестами жестко заданный промпт с контекстом (стадия дела: "Обжалование" и т.п.).
-
Требование выдать json со структурированным ответом: вероятность отмены решения (0-100), ключевые факторы и рекомендации для жалобы.
-
В настройках, насколько это возможно, блокировал возможность поиска в сети - ("plugins": []...).
Применял стандартную метрику Brier Score для оценки в��роятностных прогнозов. Она наказывает модель и за неверные предсказания, и за излишнюю (или недостаточную) самоуверенность. Дополнительно я смотрел на calibration plot - насколько заявленные моделью проценты соответствуют реальной частоте успешных апелляций (например, если модель говорит "вероятность успеха 70%", выигрывают ли реально 7 из 10 таких дел?). И скорее всего этот параметр важнее, чем простая accuracy.
Сразу к результатам!
-
Claude Sonnet 4.6 (выйдет следующий Opus - проверим и его) - выдает самые взвешенные и юридически грамотные recommendations и reasoning. Он отлично "жует" огромные портянки судебных решений без потери деталей благодаря новому окну в 1М токенов. Он может быть слишком осторожным в оценке вероятностей, из-за чего кривая калибровки иногда сползает вниз, но идеален для генерации пользовательских отчетов и формирования качественного json-ответа, который не стыдно показать клиенту.
-
GPT-5.2 (Thinking) - оказался лучший Brier Score. Модель отлично улавливает паттерны и выдает очень хорошо откалиброванные вероятности. Если GPT говорит 15% шансов на отмену - скорее всего, дело действительно гиблое. Описательная часть иногда получается суховатой, а цена вызова API ощутимо бьет по unit-экономике как теста, так и сервиса. Но это лучший выбор для точного расчета вероятности и поля probability.
-
Gemini 3.1 Pro - новое ядро рассуждения (core reasoning) творит чудеса. Она находила процессуальные нарушения в тексте, которые пропускали другие модели. Очень быстрая генерация ответа. Изредка "галлюцинирует" в ссылках на конкретные статьи АПК/ГПК, если не дать жестких ограничений в system prompt. Отличный вариант для консенсусного анализа, чтобы дать альтернативный взгляд на дело.
Факультативно я провел еще один эксперимент на 30 отмененных решениях. И здесь достаточно очевидный ход - скармливать модели не только текст решения первой инстанции, но и доводы проигравшей (победившей в апелляции) стороны. Взял реальные аргументы из апелляционных определений, вычистил из них любые упоминания того, что речь идет о судебном акте и подал на вход "Клиент считает, что суд не учел...".
Результат оказался впечатляющим. Даже читая только "голый" текст решения, где судья максимально гладко обосновал свою позицию, флагманские модели оказались пугающе проницательными. Они самостоятельно находили логические дыры и неверное применение норм, верно предсказывая высокие шансы на отмену в 60% точности. Но стоило добавить аргументы жалобы в качестве вектора для анализа, то процент верных предсказаний взлетел до 93%!
Впрочем, здесь не все так просто. В этом взрывном росте кроется известная когнитивная ловушка нейросетей - стремление угодить (есть даже термин для этой болезни - sycophancy). Когда модель получает готовые аргументы от пользователя, она начинает "болеть" за его сторону и поддакивать, искусственно завышая шансы.
Что дальше?
Для бесплатного базового прогноза оставлю предыдущую версию Gemini Flash, так как она дает все еще неплохой баланс между качеством текста рекомендаций и стоимостью. Для premium-анализа продолжу использовать консенсусный подход (как его называют в англоязычных ИИ-исследованиях - wisdom of the crowd) топовых моделей. В будущем планирую усреднить итоговый ConsensusProbability с весами, зависящими от их Brier Score на наших внутренних тестах.
Всю математику с графиками калибровки и Brier Score сейчас упаковываю в небольшой препринт. Как только допишу и опубликую - обязательно добавлю ссылку сюда.
Сентенция. Если вы не знаете как сжечь AI API-токены, то что-нибудь поисследуйте!
Никита Поляков
? aidalex.ru | neshemyaka.ru










-
Кому принадлежит Gemini?
-
Как работает Gemini?
-
Является ли Gemini точным?
-
Может ли Gemini помочь с конкретными задачами или вопросами?
-
Является ли Gemini бесплатным сервисом?
-
Можно ли использовать Gemini на мобильных устройствах?
-
Доступен ли Gemini на разных языках?
-
Как начать работу с Gemini?
Войти в Gemini: быстрый и безопасный доступ к вашему ИИ-помощнику
- Исследуйте возможности Gemini, передового ИИ от Google, созданного для преобразования вашей работы и творчества.
Что такое Gemini
- Gemini — это революционная разработка в области искусственного интеллекта, созданная компанией Google. Этот многофункциональный ИИ-помощник
Регистрация Gemini в России: Полное Руководство
- Gemini — это многофункциональный искусственный интеллект, способный генерировать тексты, переводить языки, писать код, анализировать данные и многое